2024年2月5日跨被试最新文章:
德州州立大学奥斯汀分校研究团队最近的一项研究成果,通过非侵入式的脑机接口,可以让被试不需要任何校准就可以使用脑机接口设备,这意味着脑机接口具备了大规模被使用的潜力。
一般来说,由于存在个体差异性,脑机接口设备经常需要校准用户的脑电参数,才能够正常使用。这个过程对于每个人来说也是不一样的,所以跨被试的脑机接口产品推广就存在很大的用户体验问题。尤其是对于一些病人来说,长时间的模型训练和校准将极大地消耗他们使用这项技术的热情。
研究团队采用了迁移学习的相关算法提升了跨被试的脑机接口性能,相关成果发表在PNAS期刊上(论文见链接和附件);并通过一项赛车游戏展示和论证该方法的可行性。核心方法是 训练一位专家级“解码器”作为基准,为其他用户快速解码脑电,以避免长时间的校准过程。目前已经进行了18位被试成功进行了免校准的脑机接口测试,研究人员表示,他们将来想把这项脑机接口技术应用到临床领域,帮助到病人;但同时还需要进一-步对它进行优化,使得病人更容易使用这项技术。
DOI: 10.1093/pnasnexus/pgae076

时间原因,我就不逐步分析了,总体来讲是通过迁移学习的方式来训练模型,来解码不同被试的EEG信号,并取得不错的结果了。
DOI: 10.1093/pnasnexus/pgae076
Abstract
Subject training is crucial for acquiring brain–computer interface (BCI) control. Typically, this requires collecting user-specific calibration data due to high inter-subject neural variability that limits the usability of generic decoders. However, calibration is cumbersome and may produce inadequate data for building decoders, especially with naïve subjects. Here, we show that a decoder trained on the data of a single expert is readily transferrable to inexperienced users via domain adaptation techniques allowing calibration-free BCI training. We introduce two real-time frameworks, (i) Generic Recentering (GR) through unsupervised adaptation and (ii) Personally
Assisted Recentering (PAR) that extends GR by employing supervised recalibration of the decoder parameters. We evaluated our frameworks on 18 healthy naïve subjects over five online sessions, who operated a customary synchronous bar task with continuous feedback and a more challenging car racing game with asynchronous control and discrete feedback. We show that along with improved task-oriented BCI performance in both tasks, our frameworks promoted subjects’ ability to acquire individual BCI skills, as the initial neurophysiological control features of an expert subject evolved and became subject specific. Furthermore, those features were task-specific and were learned in parallel as participants practiced the two tasks in every session. Contrary to previous findings implying that supervised methods lead to improved online BCI control, we observed that longitudinal training coupled with unsupervised domain matching (GR) achieved similar performance to supervised recalibration (PAR). Therefore, our presented
frameworks facilitate calibration-free BCIs and have immediate implications for broader populations—such as patients with neurological pathologies—who might struggle to provide suitable initial calibration data.
学科训练是获得脑机接口(BCI)控制的关键。通常,这需要收集用户特定的校准数据,因为高度的主体间神经变异性限制了通用解码器的可用性。然而,校准是麻烦的,并且可能产生不充分的数据,用于构建解码器,特别是naïve受试者。在这里,我们表明,通过允许无需校准的BCI训练的领域适应技术,在单个专家的数据上训练的解码器很容易转移给没有经验的用户。我们引入了两个实时框架,(i)通过无监督自适应的通用重入(GR)和(ii)个人辅助重入(PAR),通过对解码器参数进行监督重校准来扩展GR。我们在5个在线会议中对18个健康的naïve受试者进行了评估,他们操作了一个具有连续反馈的习惯同步酒吧任务,以及一个具有异步控制和离散反馈的更具挑战性的赛车游戏。我们发现,随着两项任务中任务导向脑机接口性能的提高,我们的框架促进了受试者获得个体脑机接口技能的能力,因为专家受试者最初的神经生理控制特征进化并成为特定于受试者的特征。此外,这些特征是特定于任务的,并且在参与者每次练习两个任务时并行学习。与之前的研究结果相反,我们发现纵向训练与无监督域匹配(GR)相结合取得了与监督重新校准(PAR)相似的性能。因此,我们提出的框架促进了无需校准的脑机接口,并对更广泛的人群有直接的影响,例如患有神经系统疾病的患者,他们可能难以提供合适的初始校准数据。
在本文中,我们首次展示了学科间迁移学习方法如何使没有经验的用户能够立即操作无创脑机接口(BCI),从而避免了标准个人校准会话的需要。
获取校准数据以构建BCI解码器是昂贵且容易出错的,因为naïve受试者可能由于缺乏反馈而产生判别能力不足的脑信号。因此,最终的解码器将表现不佳,从而阻碍了BCI训练。我们的方法为这个问题提供了一个解决方案,因为它依赖于一个独立于主题的解码器,该解码器建立在一个单一专家主题的数据上,使得校准不必要。在连续和离散在线反馈任务中验证了该方法的有效性
Introduction
基于脑电图(EEG)的无创脑机接口(BCI)已被证明在神经康复(1,2)、机器人(3,4)、通信(5,6)或虚拟现实(7,8)等应用中是有效的。运动想象(MI)——不执行肢体运动的心理排练——是一种常见的EEG - BCI模式。心肌梗死引起不同运动的不同感觉运动节律(SMR) (9,10);然而,在线解码受到脑电图非平稳特性的影响。尽管复杂的机器学习(ML)模型可以缓解这一问题,但很大一部分受试者往往表现出接近机会水平的分类表现(11),因此,受试者对BCI技能的学习——产生独特的smr——对于操作脑控设备似乎也至关重要(12-15)。因此,相互学习——建立促进受试者获得脑机接口技能的机器学习模型——得到了越来越多的关注(13,15 - 21),并且仍然是脑机接口中的一个悬而未决的问题。培训BCI主题通常从离线校准会话开始,以收集数据以构建单独的解码器。除了耗时外,这个初始解码器可能效率低下,因为受试者在校准期间没有收到帮助他们获得适当SMR的反馈。解决办法是利用杠杆预先记录的数据,以建立独立于主体的MI-BCI解码器。
在脑机接口领域,这种现象通常被称为主体间迁移学习(22),类似于机器学习领域文献中对迁移学习更常见的理解,即将在一个领域训练的模型的知识转移到另一个领域(23)。然而,学科间迁移学习策略需要处理跨学科的SMR可变性,并且需要昂贵的数据收集工作,其中可能包括由于不可区分的SMR而导致脑机接口表现不佳的受试者。
在这里,我们提出了一个Riemannian增量域适应框架,该框架对基于单个专家脑机接口(BCI)受试者的预记录数据进行跨主体迁移学习的SMR分布进行统计匹配(22,24)(图1)。我们假设我们的框架支持纵向MI-BCI训练,并促进naïve受试者的学习。
我们的框架假设不同的受试者的SMR协方差特征在黎曼流形上移位(22)(图1a)。我们的方法使用一阶统计量实时匹配专家和naïve受试者的数据分布(图1b)。因此,脑机接口提供偶然的鲁棒反馈,从而使参与者能够立即操作脑控制设备,并通过纵向训练获得脑机接口技能。
一个关键因素是匹配或重新进入过程是无监督的,并且对naïve受试者持续进行,因此也应对受试者内部SMR随时间的变化-在BCI会话内和跨会话。然而,可能的情况是,重新进入可能不足以处理受试者之间和受试者内部的SMR变异性。因此,我们测试了主体间迁移学习框架的两种变体。第一种是通用重入(GR),在整个实验过程中,专家解码器的决策边界保持固定(图1c)。我们的第二个框架,个人调整重入(PAR),通过使用一小块输入naïve主题数据调整专家解码器的参数来扩展GR(图1d)。
为了验证我们的假设,我们招募了18名BCI-naïve健康志愿者(GR组和PAR组各N = 9)参加为期5天的培训计划(图1e)。我们在两种不同的环境下评估了GR和PAR的效果(图1f):标准的酒吧任务和Cybathlon赛车游戏(25),这是一种更现实的应用。在第一个同步控制的任务中,BCI反馈是连续的,而当受试者异步发出汽车转弯命令时,游戏提供离散反馈。在每次训练中,参与者先完成酒吧任务,然后再完成赛车游戏。值得注意的是,专家数据是在酒吧任务中获得的,专家从未玩过赛车游戏。研究结果表明,受试者通过纵向训练可以在GR和PAR框架下学习MI-BCI的操作。此外,我们提供的证据表明,脑机接口控制的改善部分是由于受试者获得了产生越来越有区别的神经生理特征的技能,这些特征不一定与原始专家受试者相匹配。最后,与普遍认为个性化或有监督的解码器调整会导致更好的脑机接口性能(24)相反,GR组和PAR组的受试者在两项任务中都达到了统计上相似的性能。
Result
Acquiring BCI control: the bar task:
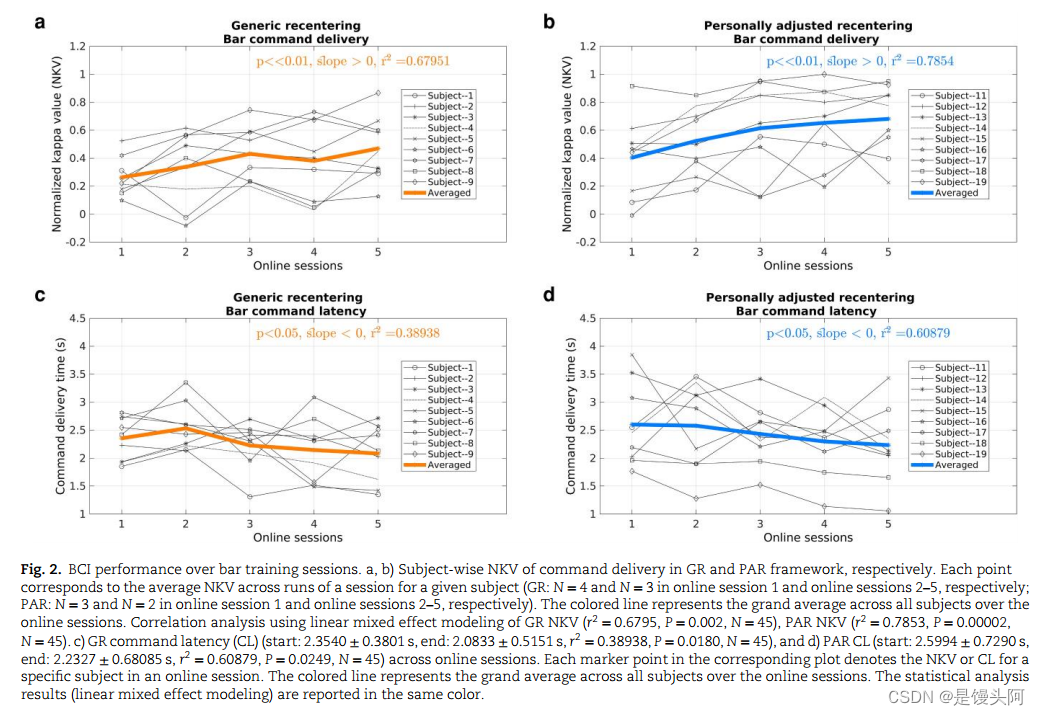
在试验中,受试者执行左侧或右侧MI。当某一类MI的累积概率超过命令传递的预定义阈值或超时时间后,试验结束。在每次试验的任务执行期间,被试收到连续的视觉反馈,反映了解码器积累的证据。我们使用Cohen的kappa (26) (κ∈[−1,1],机会水平= 0)来表征命令交付性能,然后根据超时试验次数[归一化kappa值(NKV)]进行调整。由于PAR框架的第一次运行使用试验的基础真值标签来调整解码器参数,因此该运行被排除在分析之外。我们还测量了命令延迟(CL),以量化受试者传递正确命令所需的时间。
参与者在GR(起始值:0.2636±0.1351,结束值:0.4694±0.2293,N = 9, P = 0.02)和PAR(起始值:0.4045±0.2857,结束值:0.6802±0.2526,N = 9, P = 0.001)的训练中均取得了显著的NKV改善。此外,GR和PAR的NKV改善表现出统计学上显著的增加趋势(图2a和b)。尽管PAR组的受试者在训练期间平均NKV得分普遍较高,但两组之间的差异从未达到统计学意义(补充材料,补充统计分析)。与NKV类似,受试者在疗程中改善了他们的CL,并且在两个框架中都表现出明显的下降趋势(图2c和d)。GR和PAR之间的CL在各疗程中统计相似(补充材料,补充统计分析)。
BCI control in a realistic scenario: car racing:
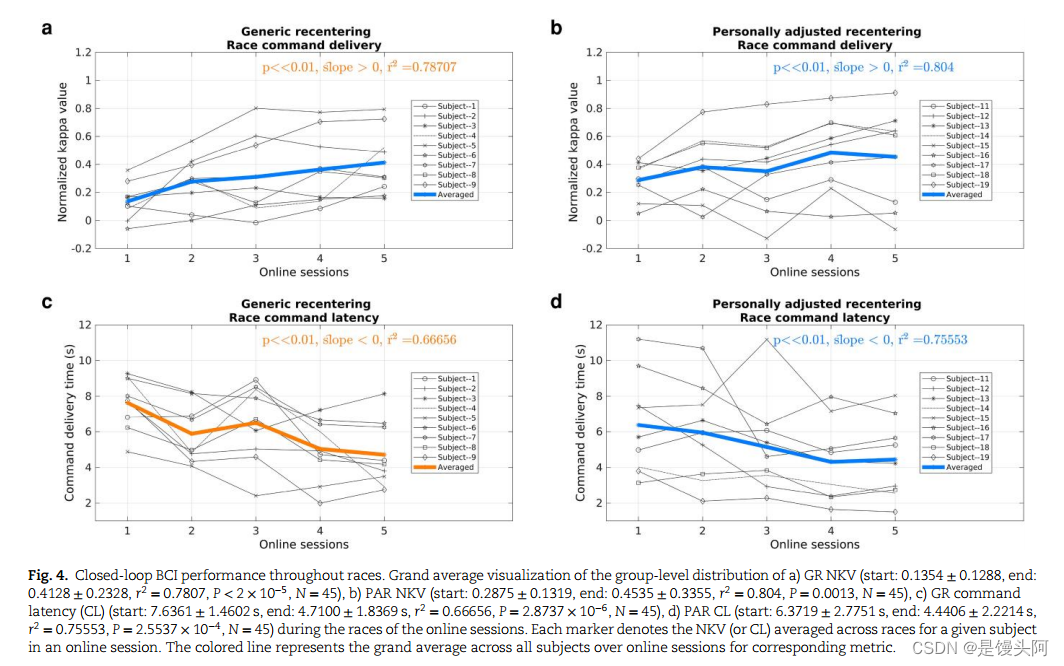
虽然酒吧任务是同步控制的,并提供连续的反馈,但它并不能反映现实生活中的设置,因为现实生活中可能只涉及异步BCI命令交付时的离散反馈。因此,参与者的表现在Cybathlon赛车游戏中被进一步评估,在其他研究中使用(27-29)。赛道被修改为只包括右转弯和左转弯补丁。由于在BCI命令传递中具有更高效率(即更高的准确性和更短的延迟)的玩家能够更快地完成比赛,所以我们使用比赛竞争时间(RCT)作为主要指标。为了完整起见,我们还报告了NKV评分和CL。
纵向训练后的GR(起跑时间:203.63±18.07秒,结束时间:162.61±22.15秒,N = 9, P = 0.00012)和PAR(起跑时间:192.23±23.22秒,结束时间:164.92±35.86秒,N = 9, P = 0.018)均显著加快。两种框架的RCT值在各阶段均呈显著负相关趋势(图3a和b)。与指标的上界(378.88 s)相比,所有受试者的RCT值均显著较低;即。在比赛完成过程中没有或只有错误的命令。
与RCT类似,参与者在GR和PAR的NKV评分中也表现出显著增加的趋势(图4a和b)。此外,受试者在疗程中提高了他们的CL,在两个框架中都显示出统计学上显著的下降趋势(图4c和d)。
RCT、NKV和CL分数表明,GR和PAR框架的纵向训练促进了高认知需求情景(如赛车游戏)中MI-BCI控制的习得。虽然所有的表现指标(RCT、NKV和CL)在训练开始时在PAR框架中显示出不显著的更好的分数,但在训练结束时,这些分数的组间差异相当小,最终在RCT中略有恢复(补充材料,补充统计分析)。


Discussion:
我们提出了两个利用领域适应进行纵向脑机接口训练的主体间迁移学习框架,并展示了它们如何促进个体脑机接口技能的习得。事实上,参与者表现出了技能学习的两个关键要素,即在会话中提高了BCI命令的准确性和更快的执行速度(图2-4)。与现有的迁移学习方法相反,我们的方法只需要其中一个的数据单个专家主体构建初始解码器。这两种框架都被证明是非常有效的,因为参与者能够立即操作大脑控制的设备BCI-naïve受试者不仅在实验室环境中显著增强了他们的控制力,而且在更复杂的场景(赛车游戏)中也是如此。这进一步强调了解码模型在任务之间是可转移的,因为专家受试者从未玩过赛车游戏。
此外,我们引入了一种新的方法来解开参与者调节的特征与脑机接口控制的神经生理学相关性。这通过持续提高特征的可分离性/可判别性(图6)提供了主体学习的证据,这些特征与最初的专家主体(图5)有所区别,并成为特定于主体的(图5)。S9-S12)。
Is inter-subject transfer learning superior to a subject-specific BCI?
尽管我们的研究结果强烈支持可以省略典型的特定科目校准会话,但一个基本问题出现了:所提出的跨科目迁移学习框架如何在特定科目的脑机接口中执行?为了回答这个问题,我们将我们的框架与另外两个BCI解码器进行了比较,这些解码器是根据每个受试者在bar任务的临时伪在线设置中的校准会话数据构建的。第一个解码器在会话期间保持固定,而第二个解码器在会话期间根据受试者组相应的适应框架(GR或PAR)进行调整。
虽然在伪在线设置中比较解码器可能会使结果偏向于在线使用的解码器(受试者试图生成与他们收到的反馈一致的模式),但GR和PAR中的专家解码器在统计上表现良好
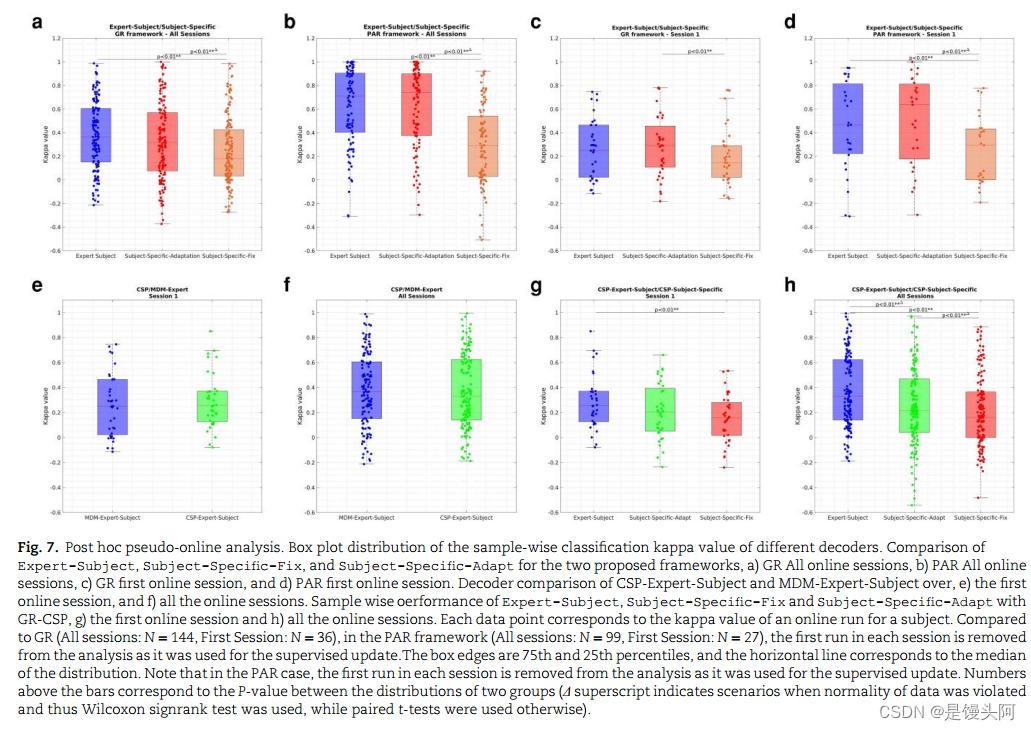
比解码器在校准后保持固定的受试者特异性脑机接口(BCI)更好,但与自适应的受试者特异性解码器表现相似(图7a和b)。此外,与第一次会话中已经使用的受试者特异性解码器相比,受试者使用相应的迁移学习框架取得了统计学上相似或更好的表现(图7c和d)。
迁移学习方法的即时竞争性表现是使被试获得脑机接口控制的关键。
此外,我们提出的将GR框架与CSP集成的方法表明,使用GR框架在新手和专家受试者之间传递CSP解码器,即使从第一次在线会话开始,其性能也与受试者特定的CSP解码器在统计上相似。然而,尽管CSP和基于mdm的分类方法产生相似的分类性能,但我们认为基于mdm的方法更适合在线bci,因为它们能够执行实时解码器参数更新(即PAR框架)。相比之下,更新CSP中的空间滤波器并随后增量更新线性判别分类器将是一项具有挑战性的任务。
这些结果证实,我们的学科间迁移学习方法可以消除对特定学科校准会话的需要。