目录
- 前述:卷积神经网络基础
- 1.卷积网络流程
- 2.卷积网络核心
- 3.卷积下采样
- 4.卷积上采样--转置卷积
- 一、卷积神经网络层
- 1.卷积层
- (1)内部参数:卷积核权重
- (2)内部参数:偏置
- (3)外部参数:填充padding(默认不填充)
- (3)外部参数:步幅stride(默认步幅为1)
- 2. 滤波器--多通道卷积核
- (1)多通道输入
- (2)多通道输出
- 3. 池化层(Pooling)
- (1) 最大池化层
- (2) 平均池化层
- 4. 平铺层及全连接层(线性层)
- 二、卷积神经网络模型
- 1. LeNet-5
- 2. AlexNet
- 3. GoogLeNet
- 4. ResNet(残差网络)
卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。卷积神经网络结构包括:卷积层,降采样层,全链接层。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。
前述:卷积神经网络基础
1.卷积网络流程
输入层–>卷积层(提取特征)–>池化层(压缩特征)–>平铺层及全连接层–>输出特征图。
2.卷积网络核心
(1)浅层卷积层提取基础特征,如边缘、轮廓。
(2)深层卷积层提取抽象特征。如指对数据中的高级、语义性质的表示或描述。
(3)全连接层根据特征进行评分分类。
3.卷积下采样
通道加倍,尺寸减半。
●通道加倍原因:用多个通道特征图去描述某个特征。
●尺寸减半原因:①计算力限制。②各特征建立联系。
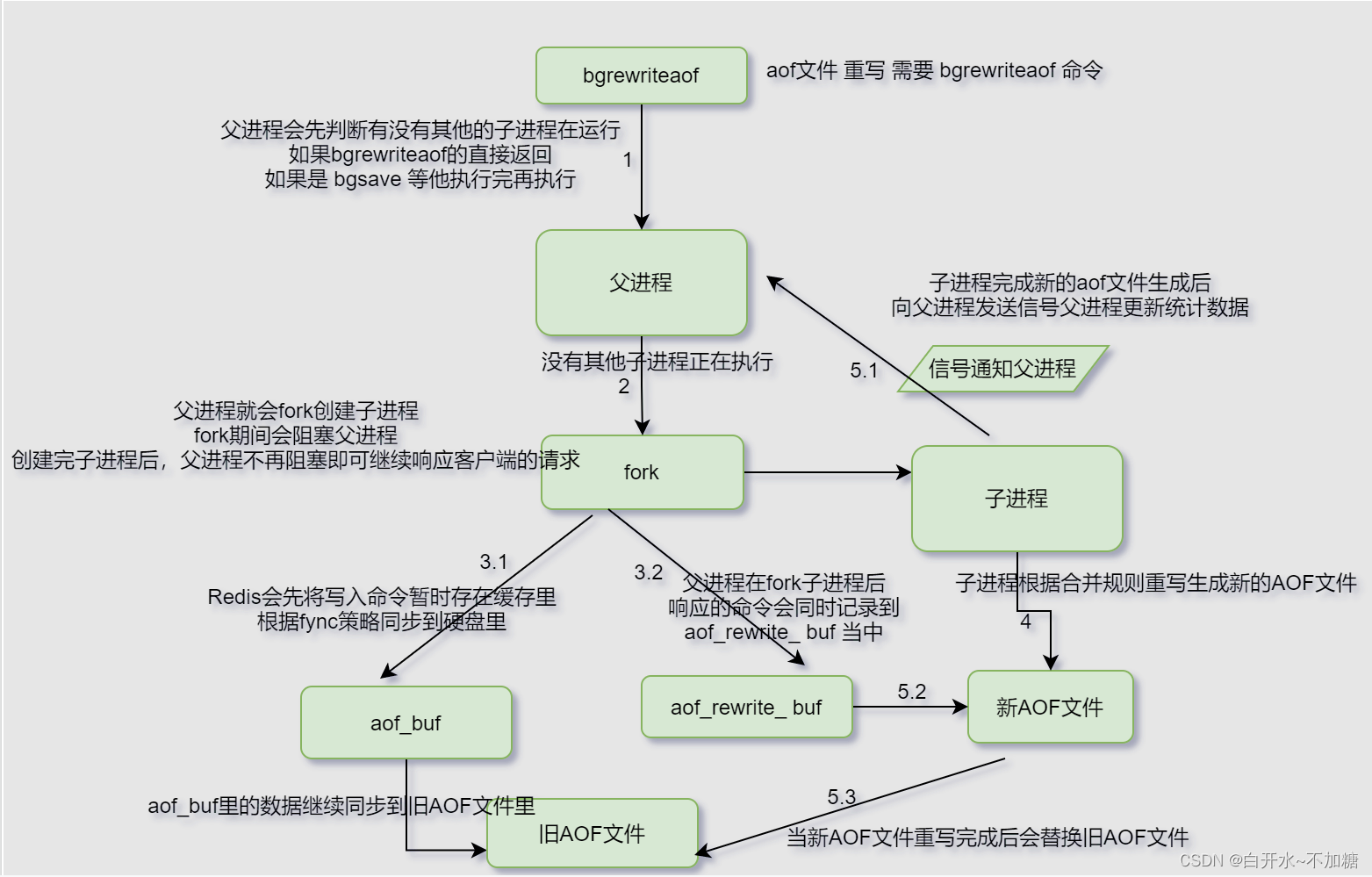
4.卷积上采样–转置卷积
用于将输入的特征图的尺寸增加,从而实现上采样的目的。这在一些任务中非常有用,比如语义分割、图像生成等。
一、卷积神经网络层
输入数据进入卷积层后,与卷积核进行运算,计算的结果就是得到的特征图。如果得到的特征图尺寸较大,我们可以采用池化层(降采样层)进行降采样,来减小特征图的尺寸。
1.卷积层
conv2d = nn.Conv2d(1, 1, kernel_size=3) #输入通道数为1,输出通道数为1,卷积核为3*3
(1)内部参数:卷积核权重
当输入数据进入卷积层后,输入数据会与卷积核进行卷积运算。卷积核相当于权重系数。将卷积核与输入数据对应元素进行加权求和计算出结果。
kernel_size=3 """3*3的卷积核"""
kernel_size=(2,3) """2*3的卷积核"""

具体计算步骤:
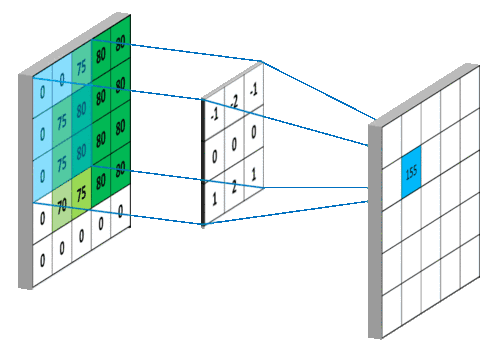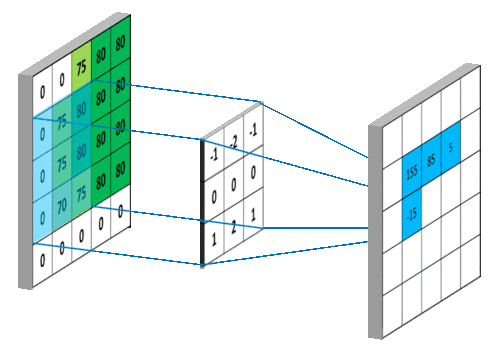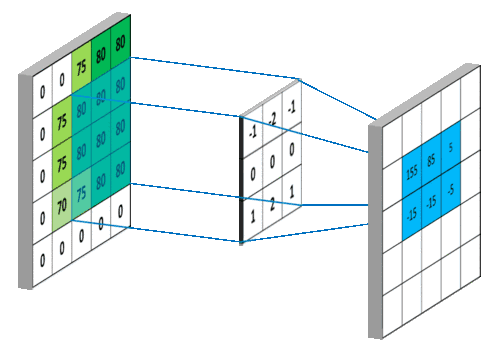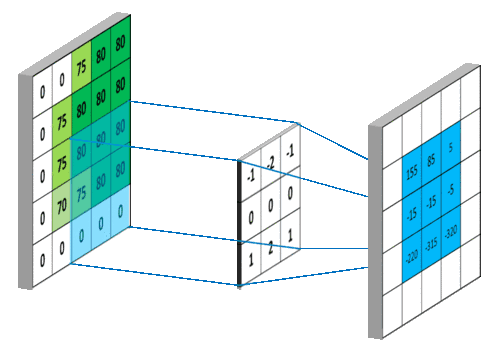
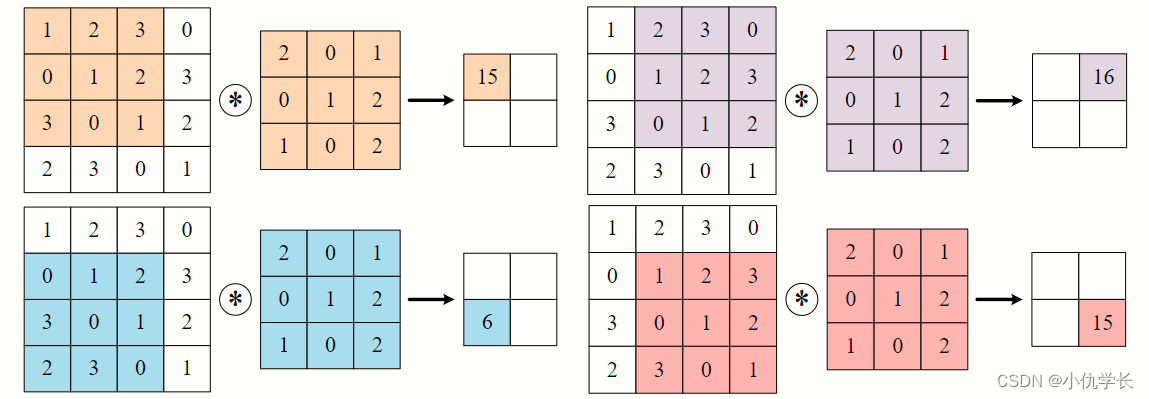
(2)内部参数:偏置
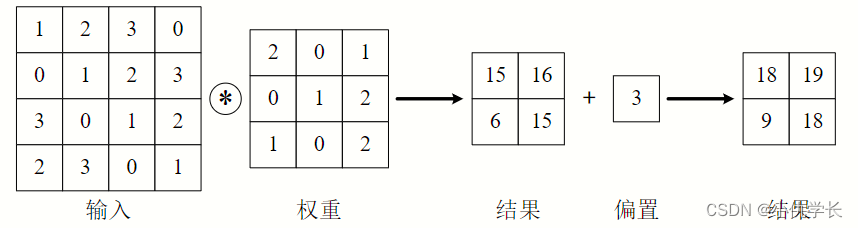
卷积层也会有偏置操作。
(3)外部参数:填充padding(默认不填充)
经过卷积层后,输入的图像特征尺寸会减小。为了使得图像的输入尺寸和输出尺寸保持一致,可以使用填充padding,来确保卷积后图像尺寸保持不变。
为了防止经过多个卷积层后图像越卷越小,可以在进行卷积层的处理之前,向输入数据的周围填入固定的数据(比如 0),这称为填充(padding)。这样经过卷积后的图片不会变小,并且可以保留原始图像的边界信息,以便我们设计更深层次的神经网络。
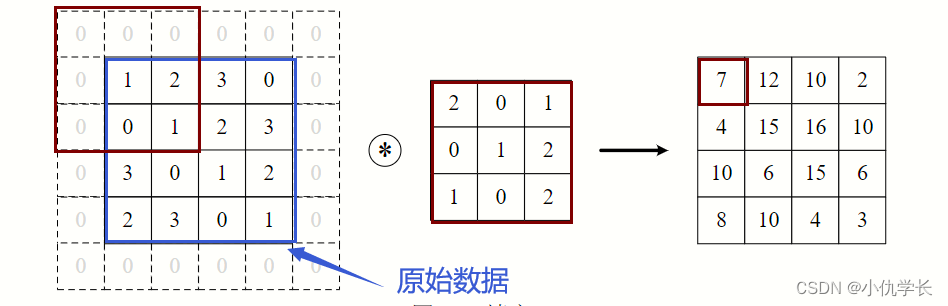
padding=1 :输入元素上下左右各添加一圈0元素
"""(输入通道、输出通道、卷积核,填充层)"""
""" padding=1 :输入元素上下左右各添加一圈0元素"""
"""kernel_size=3 :卷积核为3×3 """
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1) #举例: 0 0 0 0 0 0
1 2 3 4 0 1 2 3 4 0
5 6 7 8 0 5 6 7 8 0
9 10 11 12 0 9 10 11 12 0
13 14 15 16 0 13 14 15 16 00 0 0 0 0 0
padding=(0,1) :输入元素上下维度不添加0,左右维度添加一圈0元素
"""padding=(0,1) :输入元素上下维度不添加0,左右维度添加一圈0元素"""
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=(0,1)) #举例:
1 2 3 4 0 1 2 3 4 0
5 6 7 8 0 5 6 7 8 0
9 10 11 12 0 9 10 11 12 0
13 14 15 16 0 13 14 15 16 0
padding=‘SAME’ :在输入的周围添加足够的零填充,以确保卷积操作的输出尺寸与输入尺寸相同
"""padding='SAME ' 即在输入的周围添加足够的零填充,以确保卷积操作的输出尺寸与输入尺寸相同"""
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding='SAME' )
(3)外部参数:步幅stride(默认步幅为1)
在卷积操作中,步幅(stride)是指卷积核在输入数据上滑动的步长。它决定了输出特征图的空间尺寸。
具体来说,步幅控制了卷积核在输入数据的行和列方向上的移动距离。如果步幅为 1,那么卷积核将以一次一个像素的速度沿着输入数据的行和列方向滑动。而如果步幅为 2,则每次移动两个像素,以此类推。
stride=2 :行列步幅都为2。
conv2d = nn.Conv2d(1, 1, kernel_size=2, stride=2)
如下:
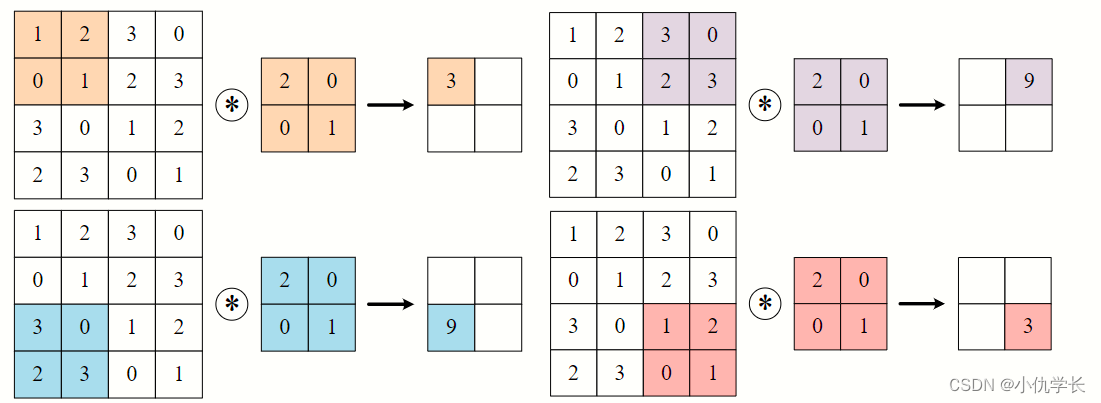
stride=(2,3) :行步幅为2,列步幅为3。
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=1, stride=(2,3))
2. 滤波器–多通道卷积核
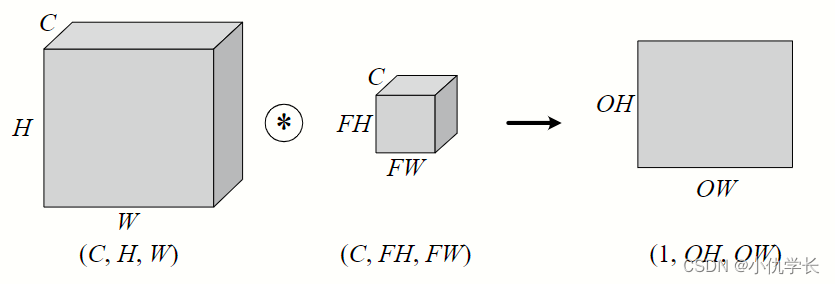
上述的卷积层,仅仅针对二维的输入与输出数据(一般是灰度图像),可称之为单通道。但是,彩色图像除了高、长两个维度之外,还有第三个维度:通道(channel)。例如,以 RGB 三原色为基础的彩色图像,其通道方向就有红、黄、蓝三部分,可视为 3 个单通道二维图像的混合叠加。
一般的,当输入数据是二维时,权重被称为卷积核(Kernel);当输入数据是三维或更高时,权重被称为滤波器(Filter)。
在卷积神经网络(CNN)中,滤波器用于提取图像中的特征。每个滤波器都可以看作是一个多通道的卷积核,因为它在图像的每个通道上进行卷积操作,并输出一个单通道的特征图。
(1)多通道输入
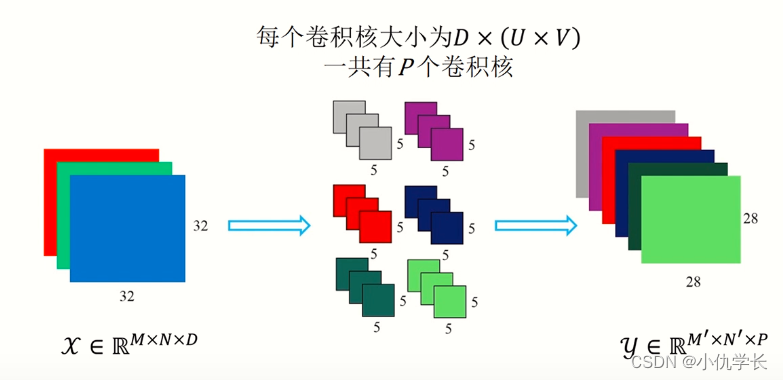
对三维数据的卷积操作下图所示,输入数据与滤波器的通道数必须要设为相同的值,可以发现,这种情况下的输出结果降级为了二维特征图,也就是单通道。
简单来说:输入数据有多少个通道就决定了一个滤波器有多少个通道。
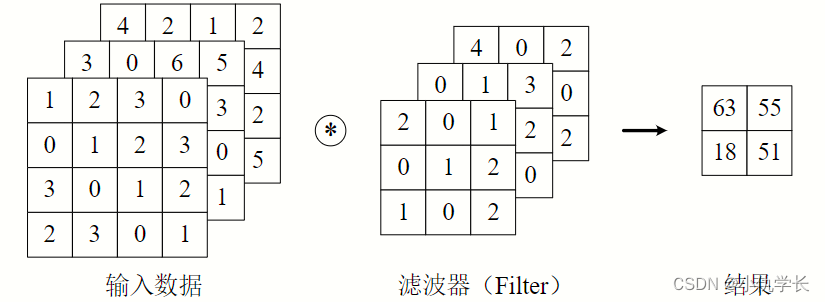
计算过程:
(2)多通道输出
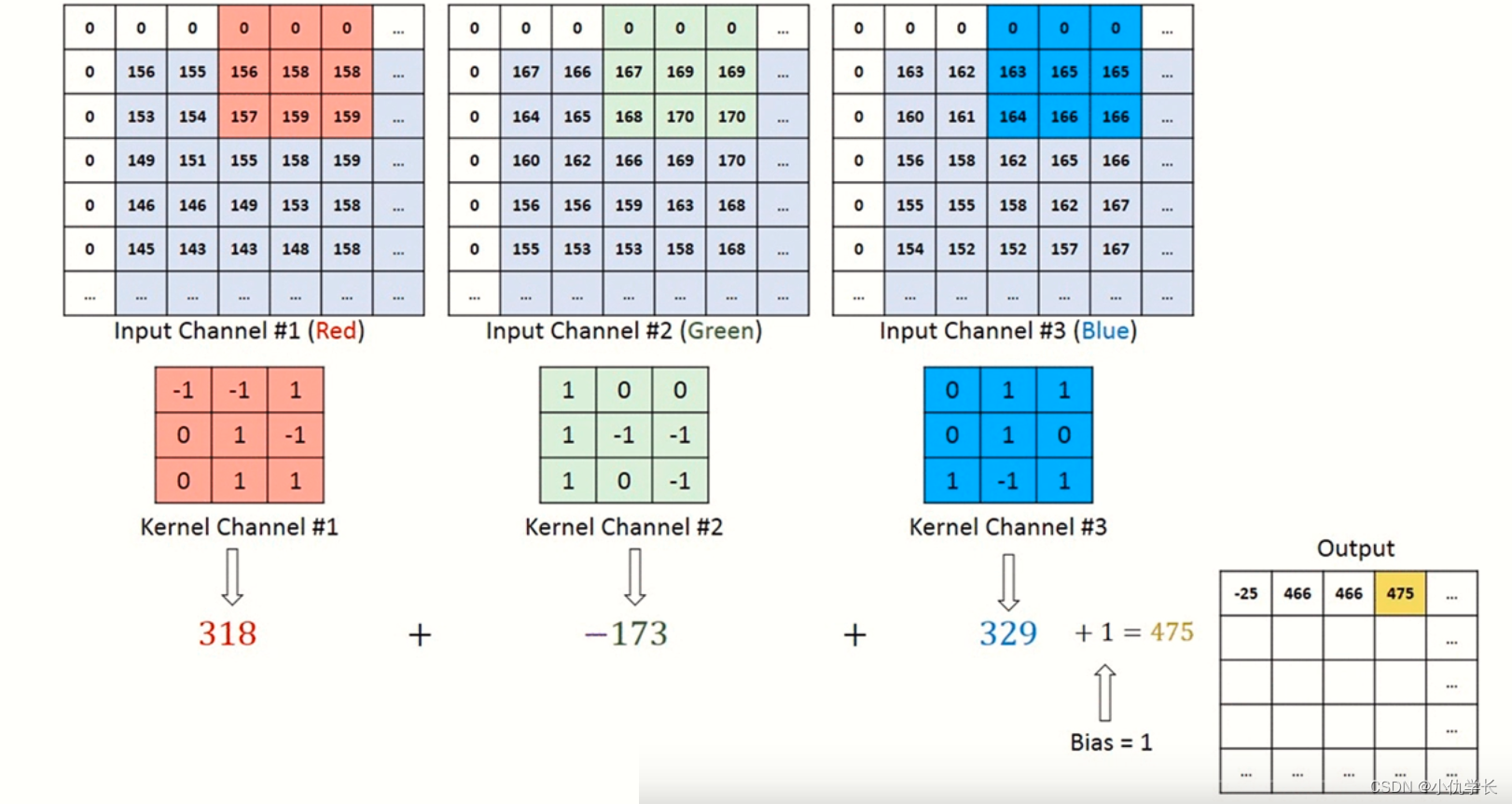
当通过一个多层卷积核(滤波器)时,输出就被降成二维特征图了。大多数时候我们需要三维的特征图时就可以多经过几个滤波器,单个滤波器会生成单通道的特征图,多个滤波器就可以生成多个特征图,我们把这些多个特征图合并,就变成了多通道的特征图,因此就有了多通道输出。
简单来说:有多少个滤波器(多通道卷积核),输出特征图就有多少个通道。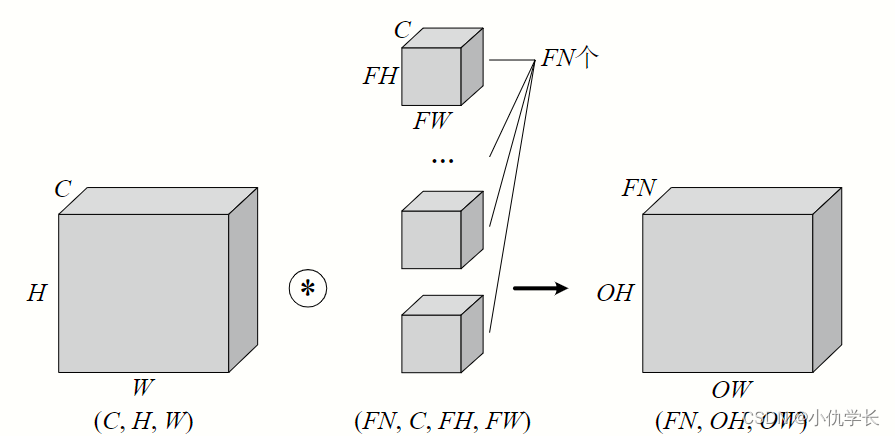
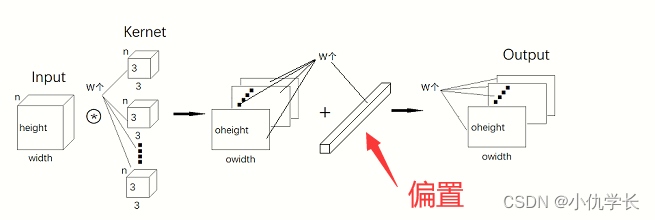
别忘了,卷积运算中存在偏置,如果进一步追加偏置的加法运算处理,则结果如下图所示,每个通道都有一个单独的偏置。
3. 池化层(Pooling)
池化层是卷积神经网络中的一种常用层,用于减少特征图的空间尺寸,从而减少参数数量并且降低模型的计算复杂度。
池化操作通常应用于卷积层的输出之后,卷积计算之后,特征数据多的话,识别会浪费很多时间,所以可以通过下采样的方式,将特征减少(但仍保留重要的特征点),这样就节约很多时间。
池化层分为:最大池化和平均池化。
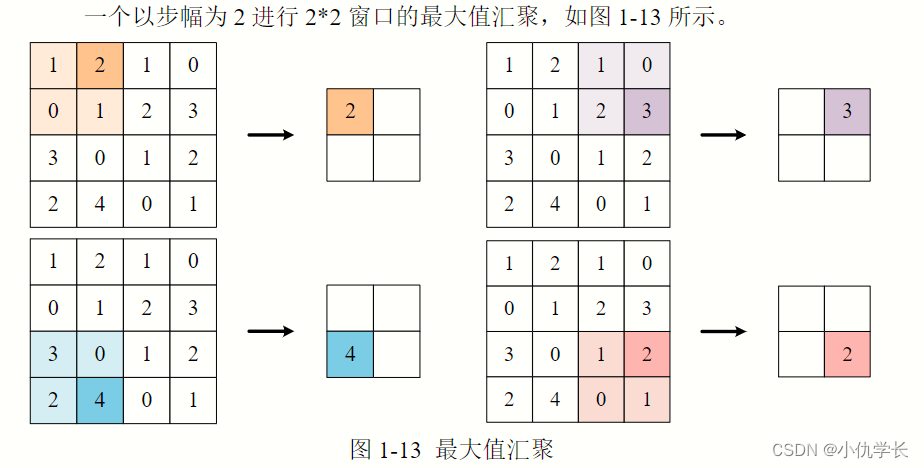
(1) 最大池化层
原理:取得原特征图窗口大小内元素的最大值作为新的特征图元素。
max_pool_layer = nn.MaxPool2d(kernel_size=2, stride=2)
(2) 平均池化层
原理:取得原特征图窗口大小内元素的平均值作为新的特征图元素。
avg_pool_layer = nn.AvgPool2d(kernel_size=2, stride=2)
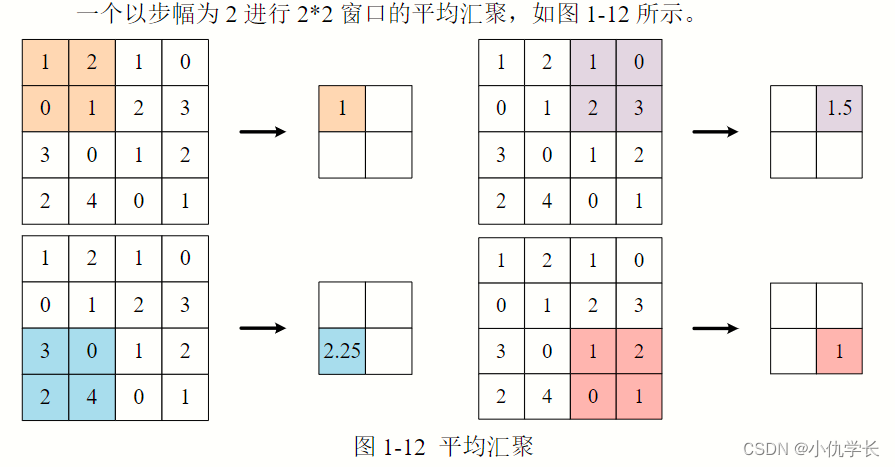
4. 平铺层及全连接层(线性层)
nn.Linear(输入的维度,输出维度)。
全连接层通常用于在神经网络的前向传播过程中进行特征提取和分类。这些层的输入是前一层的输出,每个输入节点与当前层的每个节点都连接,每个连接都有一个权重。然后,通过对每个连接的加权和以及可选的偏置项,得到当前层的输出。
平铺操作:nn.Flatten()。神经网络中用于将多维的输入张量(如图像)展平成一维的张量。这在卷积神经网络(Convolutional Neural Networks,CNNs)的卷积层之后、全连接层之前常见。
在分类任务中,全连接层的输出通常与softmax函数结合,以将输出转换为表示类别概率分布的形式,从而进行分类。在回归任务中,全连接层的输出通常直接作为最终的预测结果。
二、卷积神经网络模型
1. LeNet-5
LeNet-5 虽诞生于 1998 年,但基于它的手写数字识别系统则非常成功。
该网络共 7 层,输入图像尺寸为 28×28,输出则是 10 个神经元,分别表示某手写数字是 0 至 9 的概率。
(1)网络结构
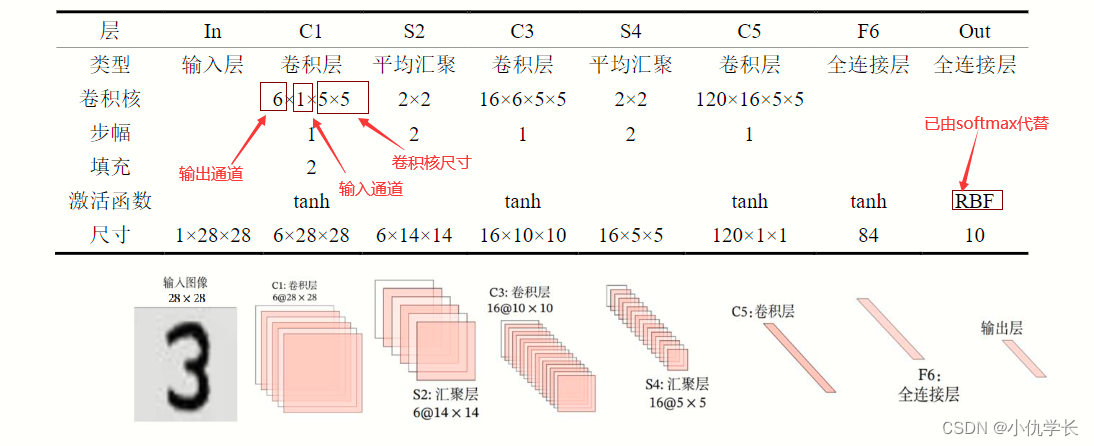
(2)根据网络结构搭建模型
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10))def forward(self, x):y = self.net(x)return y# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
2. AlexNet
AlexNet相当于更深一点、更胖一点的LeNet网络。
AlexNet 主要用于图像分类任务。它是一个深度卷积神经网络架构,旨在对图像进行高效和准确的分类。通过学习大量的标记图像数据集(如 ImageNet),AlexNet 能够从输入的图像中提取特征,并将其映射到不同的类别,从而实现对图像的分类识别。
除了图像分类之外,AlexNet 的架构也可以用于其他视觉任务,如目标检测、物体识别、图像分割等。在这些任务中,可以使用 AlexNet 作为特征提取器,然后将提取的特征输入到其他模型中进行进一步处理。
●AlexNet细节:①激活函数从sigmoid变为了Relu。②全连接层后加入丢弃层。③数据增强。
丢弃层:在计算下一层之前将当前层的一些节点置0(设定丢弃概率),即在层之间加入噪音。丢弃层在训练时把神经元丢弃后训练,在预测时不丢弃。用于提高模型的鲁棒性(抗干扰性)。
(1)网络结构
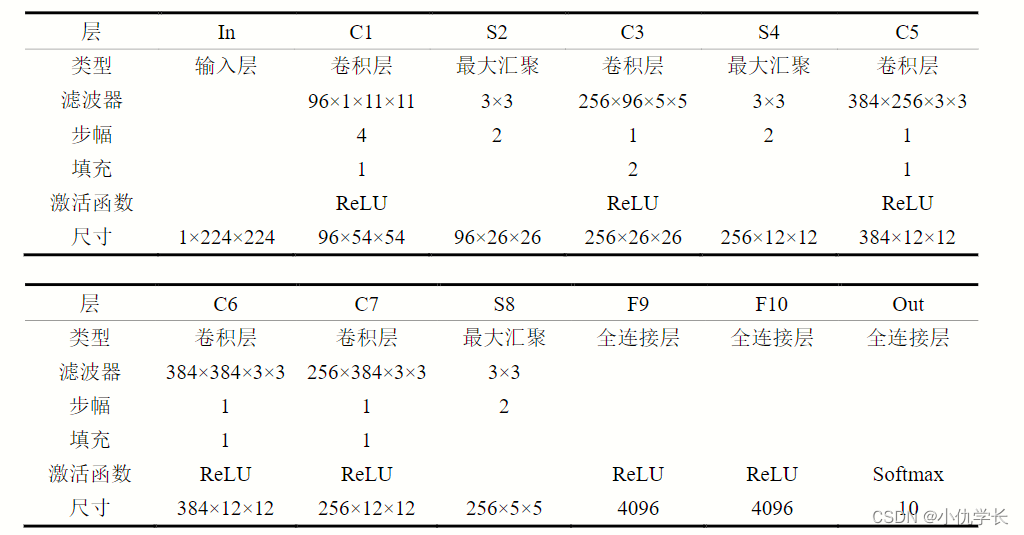
(2)根据网络结构搭建模型
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10))def forward(self, x):y = self.net(x)return y# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')3. GoogLeNet
这个模型解决了一个重要问题:滤波器超参数选择困难,如何能够自动找到最佳的情况。其在网络中引入了一个小网络——Inception 块,由 4 条并行路径组成,4 条路径互不干扰。这样一来,超参数最好的分支的那条分支,其权重会在训练过程中不断增加,这就类似于帮我们挑选最佳的超参数,如示例所示。
GoogLeNet共有22层网络,但是参数却比AlexNet少得多,主要通过以下方法提升性能:①Inception 结构融合多尺度特征信息。②使用1×1的卷积进行降维,减少计算量。③使用辅助分类器,缓解梯度弥散。④丢弃全连接层,使用平均池化层,大幅度减少模型参数。
(1)Inception 块
作用:提高模型效果,减少参数量。
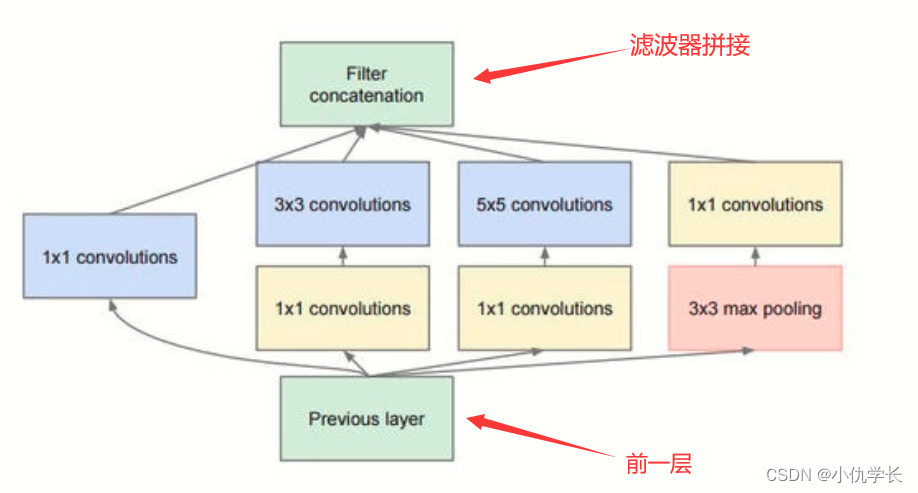
其中1×1的卷积核主要是降维(尺寸不变,减少通道数)的作用!!
注意:每个分支所得到的特征矩阵高和宽必须相同!
# 一个 Inception 块
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()"""1*1的卷积核不改变尺寸,因此输入和输出尺寸一致"""self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)"""3*3的卷积核会改变尺寸,但是填充1层padding后,输入和输出尺寸一致"""self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),)"""5*5的卷积核会改变尺寸,但是填充2层padding后,输入和输出尺寸一致"""self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, 24, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1) """滤波器拼接:将多个张量拼接为维度为1的张量"""
(2)搭建模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10))def forward(self, x):y = self.net(x)return y# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
4. ResNet(残差网络)
当模型达到最优状态时,后续操作层对模型无太大的影响,可使得模型保持最优。因为每一层卷积操作不一定使得模型一直在优化,为了使得那些效果不好的某层卷积不影响模型,提出了残差网络。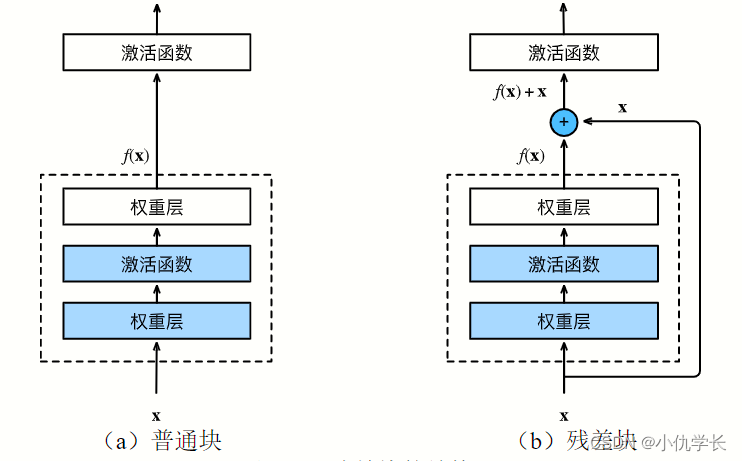
(1)残差块
""""""
class ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.net = nn.Sequential(nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(channels, channels, kernel_size=3, padding=1),)def forward(self, x):y = self.net(x) return nn.functional.relu(x+y)"""两个张量 x 和 y 的元素级相加结果进行 ReLU(Rectified Linear Unit)激活函数的操作。""""""ReLU 激活函数,它将输入张量中所有小于零的元素置为零,大于零的元素保持不变"""
(2)模型搭建
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(16),nn.Conv2d(16, 32, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(32),nn.Flatten(),nn.Linear(512, 10))def forward(self, x):y = self.net(x) return y