补充知识1
内存的本质是对数据的临时存储

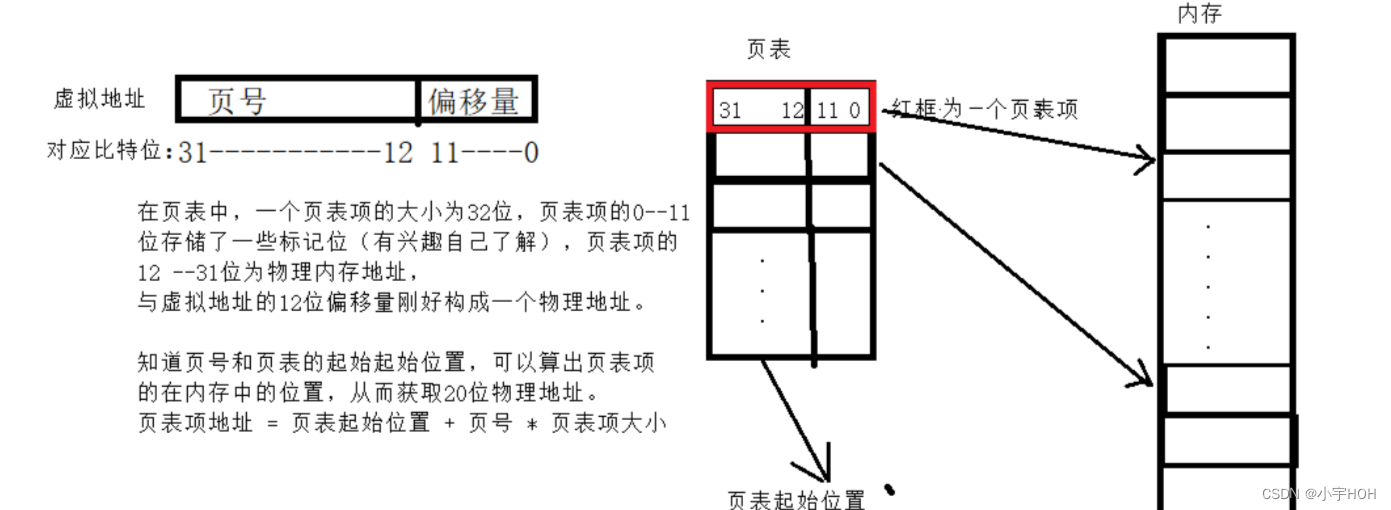
内存与磁盘进行交互时, 最小单位是4kb叫做页框(内存)和页帧(磁盘)
也就是, 如果我们要将磁盘的内容加载到内存中, 可是文件大小只有1kb, 我们也要拿出4kb来存他, 多余的就直接浪费掉, 同理, 如果我们需要对一个比特位进行修改, 也是一样需要将这个比特位所在的大小为4kb的区域加载到内存。
为什么要一次要4kb
因为磁盘是机械设备, 所以他的效率很低, 比起要4次1kb, 1次要4kb会快很多, 而为什么不用多少加载多少是因为虽然现在暂时只需要这100字节, 但是可能马上就又需要他的上下文, 而这样反复的去找对磁盘来说是很花时间的,而磁盘定位完成后, 将数据加载到内存的速度是很快的, 所以当我们找到数据对应的位置的时候, 就干脆把对应的块全加载进来, 这就对于局部性原理的预加载机制。
补充知识2
操作系统是如何管理内存的
操作系统不仅能看到虚拟地址空间, 同时也可以看到物理内存
那操作系统是怎么管理内存的呢?
操作系统中有一个结构叫
struct page {}, 它里面包含了page页必要的属性信息, 一个page对应的是一个4kb的大小。
而由多到的内存空间, 就会有对应大小的struct page数组来管理这些空间, 于是我们对内存空间的管理, 就转变为了对数组的管理, 由于数组是有下表的, 所以这个下表就直接对应的是我们page页的页号

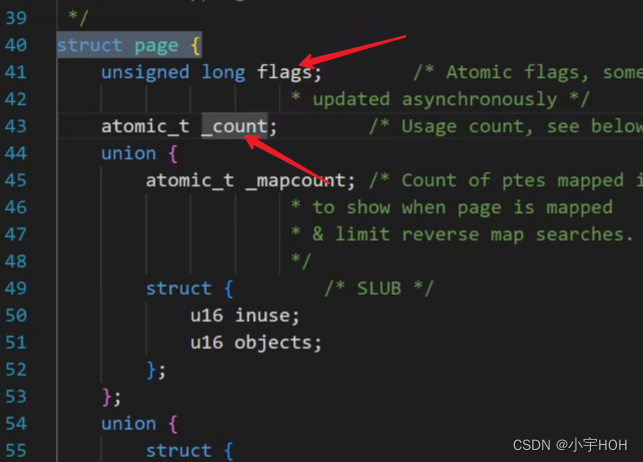
通过查看Linux源码我们可以发现这两个变量
其中flags表示的这个page管理的块的状态, 每个比特位都有他自己的含义, 具体什么就不谈了。
_count是引用计数, 表示的是当前块被几个东西使用, 这里也可以进一步解释我们的写实拷贝, 当我们要修改改字段的时候, 发现该字段的权限为只读, 但是_count >= 2所以此时就发生写实拷贝
补充3
当我们操作系统在打开一个文件的时候, 他会为我们文件创建一个数据结构叫做struct inode 这里面会保存文件的大部分属性他的属性是从inode table里该文件对应的inode里来的
但是到这里还只能获得问价你的属性, 文件的内容该怎么获取呢?
在struct里还有个数据结构叫做struct address+spacess

他里面会包含一个redix_tree_root 这么一颗树


TA
它是一个多叉树的结构, 叶子节点上存的就是一个个的struct page 对象, 每一个对象就对应物理内存中一个4kb大小的块, 所以当我们想把应用层的数据写向内核层的时候, 其实对应的是吧数据按照顺序

最后通过这个树形结构找到对应的struct page 然后再往物理内存中4kb 4kb的写入
这个就叫做文件的页缓冲区
补充4
redix_tree也就是刚刚我们讲到的那个树形结构, 我们称为基数树 \ 基数 本质其实就是一颗字典树

字典树大致是这么个情况, 具体就不多解释了, 不会就自行查看文档。
文件的内容按照4kb是有偏移量的

假如我们的文件有10mb大小, 那么按照4kb来划分, 我们的文件会被划分为2560个块
这样, 文件的每一个块也就有了他的编号。 我们用这个编号乘以4kb的大小, 就可以知道对应的数据在原始内容中的偏移量了。

所以我们拿着这个地址, 就可以去基数树里面找对应的page了
总结
1 一个磁盘对应的文件他在访问之前部分的属性已经加载到内存了。
2 进程打开文件时, 本质上就是进一步在磁盘中把对应的文件打开 –
属性往struct inode放, 内容保存好, 最终在用户层写入的时候, 经过系统调用, 进过一系列数据结构找到对应的page然后将数据刷新进物理内存。