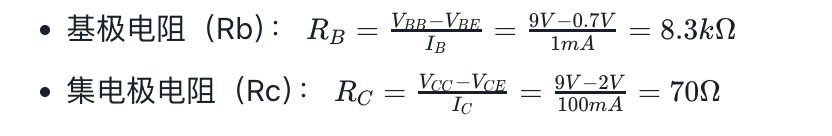集合2
list
Collection:
- List: 元素有序【存储和取出的顺序一致】,允许元素发生重复,具有索引的概念
- Set: 元素唯一且无序
1.概述:是Collection接口的子接口
2.常见的实现类:ArrayList LinkedList VectorCollection【接口】:- List【接口】元素有序【添加和取出的顺序一致】,允许发生重复,有索引- ArrayList: 底层数据结构是数组,查询快,增删慢,线程不安全,效率高
public class ListDemo1 {public static void main(String[] args) {//借助ArrayList实现子类创建List接口的对象List list1 = new ArrayList();list1.add("hello");list1.add("world");list1.add("apple");list1.add("hadoop");list1.add("redis");list1.add("world");System.out.println("list1: " + list1);Iterator iterator = list1.iterator();while (iterator.hasNext()){System.out.println(iterator.next());}}
}
List特有方法
集合具有索引的概念,根据索引提供了List集合特有的一些功能:
void add(int index,E element)
E remove(int index)
E get(int index)
E set(int index,E element)
ListIterator listIterator()
public class ListDemo2 {public static void main(String[] args) {//借助ArrayList实现子类创建List接口的对象List list1 = new ArrayList();list1.add("hello");list1.add("world");list1.add("apple");list1.add("hadoop");list1.add("redis");list1.add("world"); // 集合的末尾处添加System.out.println("list1: " + list1);//[hello, world, apple, hadoop, redis, world]// void add(int index,Object element)list1.add(3,"数加");System.out.println("list1: " + list1);//[hello, world, apple, 数加, hadoop, redis, world]//Object remove(int index) 根据索引移除元素
// System.out.println(list1.remove(10)); // 返回被删除的元素
// System.out.println("list1: " + list1);// Object get(int index) 通过索引获取元素
// System.out.println(list1.get(3));
// System.out.println("list1: " + list1);System.out.println("======");System.out.println(list1.get(3));// Object set(int index,E element) 根据索引修改值
// System.out.println(list1.set(3, "shujia")); //返回索引位置上的旧值
// System.out.println("list1: " + list1);list1.set(1,"world");System.out.println(list1);// ListIterator listIterator() 是List集合专有的迭代器对象 要想倒着遍历,必须得先正着遍历一次
// ListIterator listIterator = list1.listIterator();ListIterator listIterator = list1.listIterator();while (listIterator.hasNext()){System.out.println(listIterator.next());}System.out.println("--------------------------------------");
// while (listIterator.hasNext()){
// System.out.println(listIterator.next());
// }while (listIterator.hasPrevious()){System.out.println(listIterator.previous());}}
}
底层逻辑
1.ArrayList构造方法:a.ArrayList() 构造一个初始容量为十的空列表b.ArrayList(int initialCapacity) 构造具有指定初始容量的空列表 2.ArrayList源码总结:a.不是一new底层就会创建初始容量为10的空列表,而是第一次add的时候才会创建初始化容量为10的空列表b.ArrayList底层是数组,那么为啥还说集合长度可变呢?ArrayList底层会自动扩容-> Arrays.copyOf c.扩容多少倍?1.5倍
list集合的遍历方式
import java.util.ArrayList;
import java.util.List;/*List集合的遍历方式:1、先转数组再遍历2、获取迭代器遍历3、根据索引和长度使用for循环遍历【List集合专属遍历方式】*/
public class ListDemo4 {public static void main(String[] args) {List list1 = new ArrayList();list1.add("hello");list1.add("world");list1.add("java");list1.add("hadoop");list1.add("redis");System.out.println("list1: " + list1);System.out.println("-------------------------");
//for(int i=0;i<list1.size();i++){Object o = list1.get(i);System.out.println(o);}}
}
去除集合中字符串的重复值
public class ArrayListTest1 {public static void main(String[] args) {ArrayList list1 = new ArrayList();list1.add("hello");list1.add("world");list1.add("hello");list1.add("java");list1.add("flink");list1.add("hello");list1.add("java");list1.add("world");list1.add("hello");System.out.println("list1: "+list1);System.out.println("----------------------------");//创建一个新的集合,遍历旧集合//如果新集合中有该元素,说明重复,不添加//反之添加到新集合中,最后新集合中存储去重后的结果ArrayList list2 = new ArrayList();Iterator iterator = list1.iterator();while (iterator.hasNext()){String s = (String) iterator.next();if(!list2.contains(s)){list2.add(s);}}System.out.println("list2: "+list2);}
}
LinkedList集合
1.概述:LinkedList是List接口的实现类
2.特点:a.元素有序b.元素可重复c.有索引 -> 这里说的有索引仅仅指的是有操作索引的方法,不代表本质上具有索引d.线程不安全3.数据结构:双向链表 4.方法:有大量直接操作首尾元素的方法- public void addFirst(E e):将指定元素插入此列表的开头。- public void addLast(E e):将指定元素添加到此列表的结尾。- public E getFirst():返回此列表的第一个元素。- public E getLast():返回此列表的最后一个元素。- public E removeFirst():移除并返回此列表的第一个元素。- public E removeLast():移除并返回此列表的最后一个元素。- public E pop():从此列表所表示的堆栈处弹出一个元素。- public void push(E e):将元素推入此列表所表示的堆栈。- public boolean isEmpty():如果列表没有元素,则返回true。
/*LinkedList类特有功能【由于底层是链表】public void addFirst(Object e)及addLast(Object e)public Object getFirst()及getLast()public Object removeFirst()及public Object removeLast()*/
public class LinkedListDemo1 {public static void main(String[] args) {//LinkedList() 构造一个空列表。LinkedList list1 = new LinkedList();list1.add("hello");list1.add("world");list1.add("hello");list1.add("clickhouse");list1.add("redis");System.out.println("list1: "+list1);// Iterator iterator = list1.iterator();
// while (iterator.hasNext()){
// System.out.println(iterator.next());
// }System.out.println("-----------------------------------------");//public void addFirst(Object e)及addLast(Object e) 在头部添加一个元素或者尾部添加元素list1.addFirst("kafka");list1.addLast("cdh");System.out.println("list1: "+list1);//public Object getFirst()及getLast()System.out.println(list1.getFirst());System.out.println(list1.getLast());System.out.println("list1: "+list1);//public Object removeFirst()及public Object removeLast() 从集合中移除第一个元素或最后一个元素System.out.println(list1.removeFirst());System.out.println(list1.removeLast());System.out.println("list1: "+list1);}
}
Linkedlist练习
请用LinkedList模拟栈数据结构的集合,并测试
栈的特点:先进后出
题目的意思是:自己造一个类,底层封装LinkedList,自己定义方法
创建自己的类对象,调用自己定义的方法,来实现栈。
package shujia.day10;import java.util.LinkedList;public class MyStack {private LinkedList list;public MyStack(){list = new LinkedList();}public void shuJiaAddElement(Object o){list.addFirst(o);}public Object shuJiaGetElement(){return list.removeFirst();}public int getSize(){return list.size();}@Overridepublic String toString() {return "MyStack{" +"list=" + list +'}';}
}
public class LinkedListTest1 {public static void main(String[] args) {MyStack myStack = new MyStack();myStack.shuJiaAddElement("hello");myStack.shuJiaAddElement("world");myStack.shuJiaAddElement("java");myStack.shuJiaAddElement("hello");myStack.shuJiaAddElement("hadoop");System.out.println("myStack: " + myStack);int size = myStack.getSize();for (int i = 0; i < size; i++) {System.out.println(myStack.shuJiaGetElement());}}
}
Vector
Collection:
- List: 元素有序且允许发生重复,有索引
- ArrayList: 底层数据结构是数组,查询快,增删慢,线程不安全的,效率高
- Vector: 底层数据结构是数组,查询快,增删慢,线程安全的,效率低,即便是这样,我们以后也不用
- LinkedList
- Set:
Vector类特有功能
public void addElement(E obj)
public E elementAt(int index)
public Enumeration elements()
public class VectorDemo1 {public static void main(String[] args) {// Vector() 构造一个空向量,使其内部数据数组的大小为 10 ,标准容量增量为零。Vector v1 = new Vector();v1.add("hello");v1.add("world");v1.add("hello");v1.add("spark");v1.add("hbase");System.out.println("v1: "+v1);System.out.println("---------------");//public void addElement(Object obj) 向集合末尾添加一个元素效果和add方法一样,以后就用add方法替代
// v1.addElement("hive");
// System.out.println("v1: "+v1);//public Object elementAt(int index) 根据索引获取元素 以后也不用,使用get方法进行替代
// System.out.println(v1.elementAt(3));
// System.out.println(v1.get(3));//public Enumeration elements() 这个今后使用迭代器的方式进行替代
// Enumeration elements = v1.elements();
// while (elements.hasMoreElements()){
// System.out.println(elements.nextElement());
// }}
}
Collcetions工具类
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;/*Collections工具类*/
public class CollectionsDemo1 {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>(); // 线程不安全的集合类对象List<String> list2 = Collections.synchronizedList(list1); // 线程安全的list2.add("hello");list2.add("world");list2.add("java");list2.add("hello");list2.add("hadoop");System.out.println("list2: " + list2);}
}
Set
HashSet
Collection【接口】:
- List【接口】元素有序【添加和取出的顺序一致】,允许发生重复,有索引
- ArrayList: 底层数据结构是数组,查询快,增删慢,线程不安全,效率高
- Vector: 底层数据结构是数组,查询快,增删慢,线程安全,效率低,即便安全我们以后也不用
- LinkedList: 底层数据结构是双链表,增删快,查询慢,线程不安全,效率高
- Set【接口】元素无序【添加和取出的顺序不一致】,且唯一
- HashSet: 底层数据结构是哈希表,线程不安全,效率高,能够保证元素的唯一
- TreeSet
public class SetDemo1 {public static void main(String[] args) {// HashSet() 构造一个新的空集合; 背景HashMap实例具有默认初始容量(16)和负载因子(0.75)。HashSet<String> set1 = new HashSet<>();// 因为Set是Collection的子接口,HashSet是Set接口的实现类,里面必然也重写了父接口中所有的抽象方法set1.add("hello");set1.add("world");set1.add("hello");set1.add("java");set1.add("hello"); set1.add("hadoop");for (String s : set1) {System.out.println(s);}}
}
练习:
当学生的姓名和年龄一样的时候,表示重复对象
import java.util.HashSet;//需求:当学生的姓名和年龄一样的时候,表示重复对象
public class SetDemo2 {public static void main(String[] args) {HashSet<Student> set1 = new HashSet<>();Student s1 = new Student("张成阳", 18);Student s2 = new Student("方直", 18);Student s3 = new Student("张成阳", 18);Student s4 = new Student("黄沪生", 17);Student s5 = new Student("黄涛", 19);/*1、HashSet中add方法底层实际上是调用了HashMap中的put方法2、底层依赖于元素对象的类型中的hashCode()方法,但是我们Student类中并没有写,所以用的是Object类中的方法,而父亲Object类中的hashCode()是根据对象的地址值计算出一个哈希值。说明这5个对象hashCode的结果都不一样3、底层判断待插入的元素是否与已经在hashtable中的元素重复,是根据两个条件判断的1)哈希值hashCode()结果是否一样2)元素的equals方法结果是否一样我们的Student元素类中这两个方法都没有进行重写,所以任意两个Student对象的结果都不一样既然不一样,底层就认为不重复,不重复就添加到集合中,所以我们看到的结果是没有去重的*/set1.add(s1);set1.add(s2);set1.add(s3);set1.add(s4);set1.add(s5);for (Student student : set1) {System.out.println(student);}}
}
练习2:编写一个程序,获取10个1至20的随机数,要求随机数不能重复。
public class SetTest1 {public static void main(String[] args) {HashSet<Integer> set1 = new HashSet<>();Random random = new Random();while (set1.size() != 10) {set1.add(random.nextInt(20) + 1);}System.out.println("set1: " + set1);}
}
Treeset
Collection【接口】:
- List【接口】元素有序【添加和取出的顺序一致】,允许发生重复,有索引
- ArrayList: 底层数据结构是数组,查询快,增删慢,线程不安全,效率高
- Vector: 底层数据结构是数组,查询快,增删慢,线程安全,效率低,即便安全我们以后也不用
- LinkedList: 底层数据结构是双链表,增删快,查询慢,线程不安全,效率高
- Set【接口】元素无序【添加和取出的顺序不一致】,且唯一
- HashSet: 底层数据结构是哈希表,线程不安全,效率高,能够保证元素的唯一
- LinkedHashSet: 底层数据结构是哈希表和链表,线程不安全,效率高,能够保证元素的唯一【哈希表】,有序【链表】!
- TreeSet: 底层数据结构是红黑树,具有可预测的迭代次序或自定义排序
排序方式:
1) 自然排序
2) 比较器排序
import java.util.TreeSet;public class TreeSetDemo1 {public static void main(String[] args) {// 使用TreeSet集合存储字符串元素对象并遍历//TreeSet() 构造一个新的,空的树组,根据其元素的自然排序进行排序TreeSet<String> set1 = new TreeSet<>();
// TreeSet<String> set = new TreeSet();/*TreeSet中的add方法底层实际上是调用了TreeMap中的put方法*/set1.add("banana");set1.add("peach");set1.add("apple");set1.add("watermelon");set1.add("banana");set1.add("apple");set1.add("cherry");System.out.println(set1);for (String s : set1) {System.out.println(s);}}
}
需求:
使用TreeSet存储自定义对象并遍历
当教师的姓名和年龄一样的时候,认为发生重复
需求:将教师对象添加到TreeSet集合中,去重的同时,按照年龄从小到大排序
自然排序要求元素类要实现Comparable接口,并重写compareTo方法
而compareTo方法中的结果返回值,取决于需求来编写代码逻辑
public class Teacher implements Comparable<Teacher>{private String name;private int age;public Teacher() {}public Teacher(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Teacher{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic int compareTo(Teacher o) {//按照年龄从小到大排序// o - 根的元素【已经存储在树中的元素】// this - 待插入的元素//显式条件:年龄从小到大排序//隐藏条件:年龄一样,姓名不一定一样// return this.getAge()-o.getAge();int i1 = this.getAge()-o.getAge();// 当年龄一样的时候,比较姓名return (i1==0)?this.getName().compareTo(o.getName()):i1;// return -10;}
}
public class TreeSetDemo2 {public static void main(String[] args) {TreeSet<Teacher> set1 = new TreeSet<>();Teacher t1 = new Teacher("小虎", 18);Teacher t2 = new Teacher("杨老板", 16);Teacher t3 = new Teacher("笑哥", 19);Teacher t4 = new Teacher("旭哥", 15);Teacher t5 = new Teacher("小虎", 18);Teacher t6 = new Teacher("强哥", 18);set1.add(t1);set1.add(t2);set1.add(t3);set1.add(t4);set1.add(t5);set1.add(t6);for (Teacher teacher : set1) {System.out.println(teacher);}}
}
import java.util.Comparator;
import java.util.TreeSet;/*使用比较器的方式创建TreeSet集合需求:书的名字和价格一样的话,重复,价格从小到大排序*/
class MyComparator implements Comparator<Book> {@Overridepublic int compare(Book o1, Book o2) {// o1 - 待插入的元素’// o2 - 已经在树中的元素
// return 0;int i1 = o2.getPrice() - o1.getPrice();return (i1 == 0) ? o1.getName().compareTo(o2.getName()) : i1;}
}// 按照书的名字从短到长排序
//class MyComparator2 implements Comparator<Book> {
// @Override
// public int compare(Book o1, Book o2) {
// int i1 = o1.getName().length() - o2.getName().length();
// int i2 = (i1 == 0) ? o1.getName().compareTo(o2.getName()) : i1;
// return (i2 == 0) ? o1.getPrice() - o2.getPrice() : i2;
// }
//}public class TreeSetDemo3 {public static void main(String[] args) {
// TreeSet<Book> books = new TreeSet<>(new MyComparator());TreeSet<Book> books = new TreeSet<>(new Comparator<Book>() {@Overridepublic int compare(Book o1, Book o2) {int i1 = o1.getName().length() - o2.getName().length();int i2 = (i1 == 0) ? o1.getName().compareTo(o2.getName()) : i1;return (i2 == 0) ? o1.getPrice() - o2.getPrice() : i2;}});Book b1 = new Book("面试指南", 100);Book b2 = new Book("大数据spark", 98);Book b3 = new Book("面试指南", 100);Book b4 = new Book("flink开发指南", 100);Book b5 = new Book("java从基础到入坑", 50);books.add(b1);books.add(b2);books.add(b3);books.add(b4);books.add(b5);for (Book book : books) {System.out.println(book);}}
}
Map
Map【接口】:每一个元素是由键和值构成
1、在同一个Map集合中,键是唯一的,值可以发生重复
2、Map的子类HashMap,TreeMap,其中的唯一性是针对键来说的
Map接口中的方法:
V put(K key,V value)
V remove(Object key)
void clear()
boolean containsKey(Object key)
boolean containsValue(Object value)
boolean isEmpty()
int size()
public class MapDemo1 {public static void main(String[] args) {//借助Map子类HashMap来创建对象Map<Integer, String> map1 = new HashMap<>();//String put(Integer key,String value) // 返回被覆盖的旧值map1.put(1001, "张三");map1.put(1002, "李四");map1.put(1001, "王五");map1.put(1003, "赵六");System.out.println("map1: " + map1);// System.out.println("-----------------");//map1: {1001=王五, 1002=李四, 1003=赵六}//V remove(Object key) 根据键删除一个键值对, 返回对应的值
// System.out.println(map1.remove(1001));
// System.out.println("map1: " + map1);
// System.out.println("-----------------");
// //void clear() 清空map集合中所有的键值对元素
// map1.clear();
// System.out.println("map1: " + map1);System.out.println("-----------------");
// boolean containsKey(Object key) 判断是否包含某个键System.out.println(map1.containsKey(1001));System.out.println("-----------------");// boolean containsValue(Object value) 判断是否包含某个值System.out.println(map1.containsValue("李四"));System.out.println("-----------------");//boolean isEmpty() 判断集合中是否有键值对System.out.println(map1.isEmpty());System.out.println("-----------------");// int size() 获取键值对个数System.out.println(map1.size());}
}
map遍历
public class MapDemo2 {public static void main(String[] args) {//借助Map子类HashMap来创建对象Map<Integer, String> map1 = new HashMap<>();//String put(Integer key,String value) // 返回被覆盖的旧值map1.put(1001, "张三");map1.put(1002, "李四");map1.put(1001, "王五");map1.put(1003, "赵六");map1.put(1004, "王二麻");map1.put(1005, "王林");System.out.println("map1: " + map1);System.out.println("-----------------");// V get(Object key) 根据键获取值System.out.println(map1.get(1005));System.out.println("map1: " + map1);System.out.println("-----------------");// Set<K> keySet() 将所有的键拿出来放到一个Set集合中
// Set<Integer> keys = map1.keySet();Set<Integer> keys = map1.keySet();for (Integer key : keys) {System.out.println(key);}System.out.println("-----------------");// Collection<V> values() 将所有的值拿出来放到一个Collection集合中Collection<String> values = map1.values();for (String value : values) {System.out.println(value);}System.out.println("------------------");// Set<Map.Entry<K,V>> entrySet() 将每个键值对拿出来放入到Set集合中// map集合遍历方式1:一次获取所有的键值对,依次遍历得到每个键值对的键和值Set<Map.Entry<Integer, String>> entries = map1.entrySet();for (Map.Entry<Integer, String> entry : entries) {// entry - 键值对Integer key = entry.getKey();String value = entry.getValue();System.out.println(key + "-" + value);}System.out.println("------------------");// map集合遍历方式2:先获取所有的键,遍历键,根据键得到对应的值for (Integer key : keys) {// 根据键获取值String value = map1.get(key);System.out.println(key + "-" + value);}System.out.println("------------------");}
}
练习 "aababcabcdabcde",获取字符串中每一个字母出现的次数要求结果:a(5)b(4)c(3)d(2)e(1)
public class MapTest1 {public static void main(String[] args) {String s1 = "aababcabcdabcde";TreeMap<Character, Integer> map1 = new TreeMap<>();char[] chars = s1.toCharArray();for (char aChar : chars) {//判断集合集合是否有该键if(map1.containsKey(aChar)){map1.put(aChar, map1.get(aChar)+1);}else {map1.put(aChar, 1);}}StringBuilder sb = new StringBuilder();Set<Map.Entry<Character, Integer>> entries = map1.entrySet();for (Map.Entry<Character, Integer> entry : entries) {Character c = entry.getKey();Integer counts = entry.getValue();sb.append(c).append("(").append(counts).append(")");}String res = sb.toString();System.out.println(res);}
}
LinkedHashMap
LinkedHashMap是HashMap的子类:底层数据结构是哈希表【唯一性】和双链表【有序】
public class LinkedHashMapDemo1 {public static void main(String[] args) {LinkedHashMap<Student3, String> map1 = new LinkedHashMap<>();map1.put(new Student3("方直", 18), "打游戏");map1.put(new Student3("张成阳", 16), "看动漫");map1.put(new Student3("方直", 18), "看电影");map1.put(new Student3("黄涛", 17), "看书");map1.put(new Student3("康清宇", 14), "看美女");Set<Map.Entry<Student3, String>> entries = map1.entrySet();for (Map.Entry<Student3, String> entry : entries) {Student3 key = entry.getKey();String value = entry.getValue();System.out.println(key + "-" + value);}}
}
HashMap和Hashtable的区别
HashMap和Hashtable的区别
1、从源码上来看,HashMap有的方法,Hashtable中也有,只是单纯的使用没啥太大区别
2、HashMap的键和值都允许为null值, Hashtable的键和值都不允许为null
3、HashMap是不安全的集合类,Hashtable中的方法大部分都是被synchronized关键字修饰的,线程是安全的,效率比HashMap低一些。
public class HashtableDemo {public static void main(String[] args) {HashMap<String, String> map2 = new HashMap<>();map2.put(null, "hello");map2.put("java", null);map2.put(null, null);System.out.println("map2: " + map2);Hashtable<String, String> map1 = new Hashtable<>();map1.put(null, "hello");map1.put("java", null);map1.put(null, null);System.out.println("map1: " + map1);}
}