以前觉得麻烦,一直没用过nnunet,虽然知道它很火,最近一个契机,部署使用了一下nnunet,记录一下其部署和使用的方法与命令。
1、部署
首先,我有一个环境,这个环境可以是以前就有的,也可以为了nnunet重新建一个,给它一个温暖的家。
第一步,激活环境:
source activate myMRI
第二步,安装nnunet:
pip install nnunet
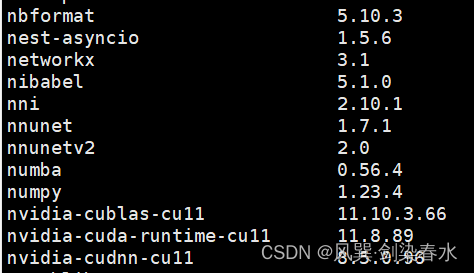
安装完了可以发现,nnunetV1和nnunetV2都安装上了:
第三步,查看与进入.bashrc文件:
ls -al /home/qijing # 查看
vim ~/.bashrc # 进入文件
第四步,修改.bashrc文件:
直接按 i 键可以对文件进行修改,若采用nnunetV1,则文件底部添加:
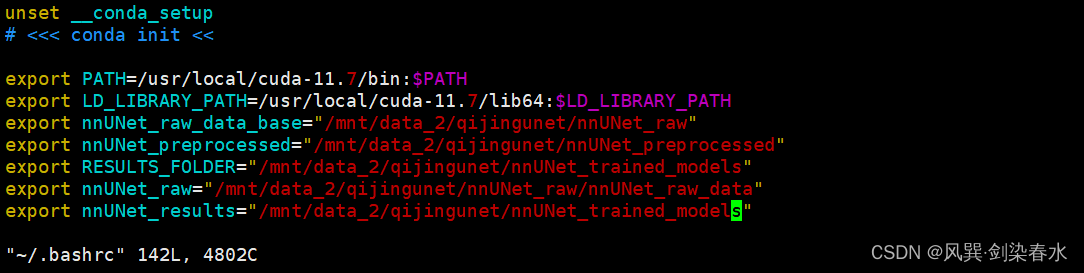
export nnUNet_raw_data_base="/mnt/data_2/qijingunet/nnUNet_raw"
export nnUNet_preprocessed="/mnt/data_2/qijingunet/nnUNet_preprocessed"
export RESULTS_FOLDER="/mnt/data_2/qijingunet/nnUNet_trained_models"
若采用nnunetV2,则文件底部添加:
export nnUNet_raw="/mnt/data_2/qijingunet/nnUNet_raw"
export nnUNet_preprocessed="/mnt/data_2/qijingunet/nnUNet_preprocessed"
export nnUNet_results="/mnt/data_2/qijingunet/nnUNet_trained_models"
这三个路径可以根据自己的文件夹名字设置,我是给V1和V2都设置了:
修改完成后,Esc + :+ wq 退出并保存修改之后的文件:Esc 键退出编辑模式,英文模式下输入 :wq ,然后回车 (write and quit)
第五步,更新.bashrc文件:
source ~/.bashrc
第六步,验证路径设置正确,并且应该打印出正确的文件夹:
echo $RESULTS_FOLDER etc
验证如下所示:

2、应用
部署好了nnunet,得用起来呀,我们试试十项分割挑战赛的数据集:下载传送
以Task02_Heart为例,下载好的文件夹如下所示,其中imagesTr存放训练数据,imagesTs存放测试数据,labelsTr存放训练数据标签,dataset.json是数据集的信息。
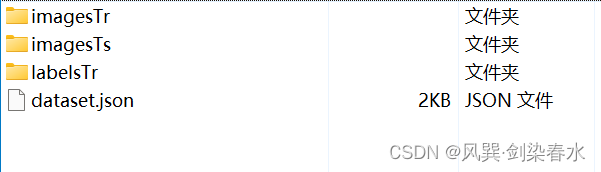
第一步,数据格式转换:
nnunetV1命令:
nnUNet_convert_decathlon_task -i $nnUNet_raw_data_base/nnUNet_raw_data/Task02_Heart
nnunetV2命令:
nnUNetv2_convert_MSD_dataset -i $nnUNet_raw/Task02_Heart
-i 后面也可以写绝对路径:
nnUNetv2_convert_MSD_dataset -i /mnt/data_2/qijingunet/nnUNet_raw/nnUNet_raw_data/Task02_Heart
运行完成后,在同目录下生成一个名为Dataset002_Heart的文件夹。
一般制作自己的数据集,可以直接制作成这一步的样子。
imagesTr文件夹如下所示,其中_0000表示模态,像Task01_BrainTumour数据集,训练数据会有四个模态。
labelsTr文件夹如下所示,与imagesTr文件夹中的数据相对应:
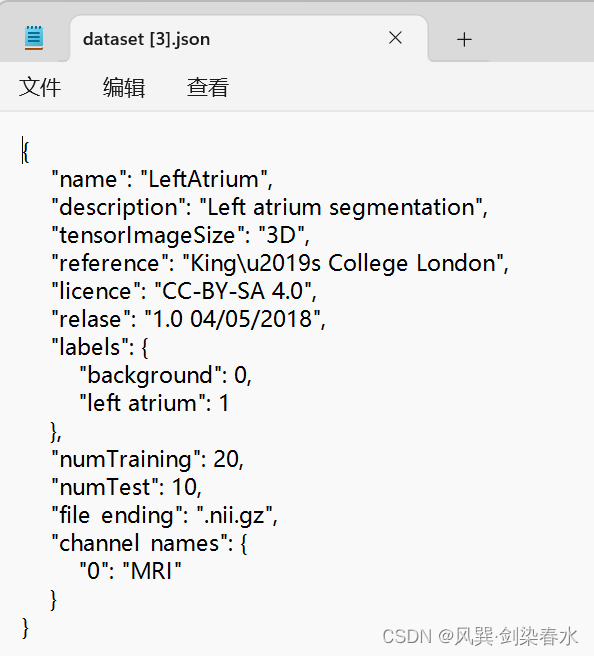
dataset.json文件信息如下,nnUnetV2的dataset.json信息比nnUnetV1简单很多,如果是自己的数据集,可以写代码生成json信息文件,当然如果按V2这个形式,复制过去改是最方便的啦~
第二步,数据预处理:
nnunetV1命令:
nnUNet_plan_and_preprocess -t 002 --verify_dataset_integrity
nnunetV2命令:
nnUNetv2_plan_and_preprocess -d 002 --verify_dataset_integrity
其中,002是任务id号,预处理完成后,会在nnUNet_preprocessed文件夹中生成一个Dataset002_Heart同名文件夹,里面包含以下内容:

第三步,模型训练:
(1)训练2D U-Net模型
nnunetV1命令:
nnUNet_train 2d nnUNetTrainerV2 Task002_Heart 3
nnUNet_train 2d nnUNetTrainerV2 002 3
可以写文件夹全名,也可以只写任务id号,最后的数字表示第几折,默认取值为[0,1,2,3,4],
nnunetV2命令:
nnUNetv2_train 002 2d 0
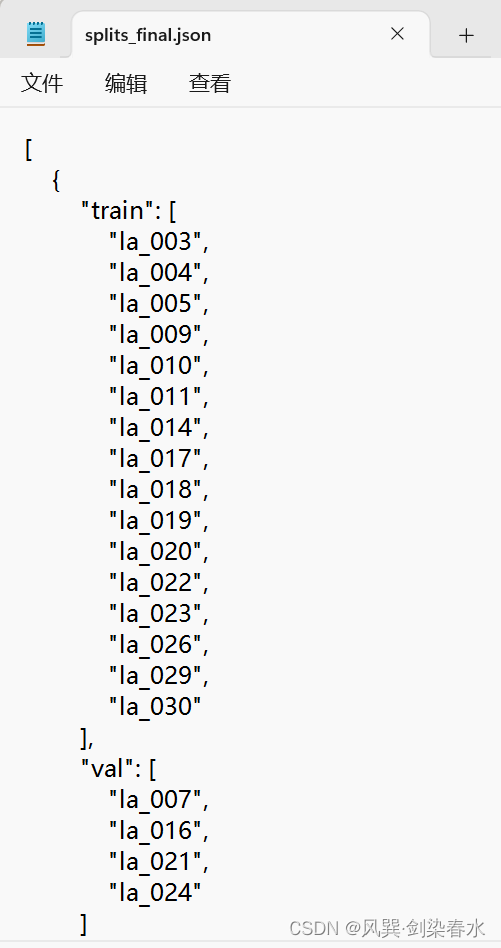
运行命令后,会在nnUNet_preprocessed/Dataset002_Heart文件夹中生成一个splits_final.json文件,其中存储的就是交叉验证的数据划分信息,当然啦,如果想自己划分也可以修改这个文件。
当然啦,一折一折跑还得看着它,挺麻烦的,想要一个命令实现五折交叉验证怎么办咧
使用 && 运行多个 Linux 命令:
nnUNet_train 2d nnUNetTrainerV2 002 0 && nnUNet_train 2d nnUNetTrainerV2 002 1 && nnUNet_train 2d nnUNetTrainerV2 002 2 && nnUNet_train 2d nnUNetTrainerV2 002 3 && nnUNet_train 2d nnUNetTrainerV2 002 4
nnUNetv2_train 002 2d 0 && nnUNetv2_train 002 2d 1 && nnUNetv2_train 002 2d 2 && nnUNetv2_train 002 2d 3 && nnUNetv2_train 002 2d 4
nnUNet五折交叉验证运行结束后可在以下路径中生成五个fold文件夹:
nnUNet_trained_models/nnUNet/2d/Task002_Heart/nnUNetTrainerV2__nnUNetPlansv2.1

(2)训练3D full resolution U-Net模型
nnunetV1命令:
nnUNet_train 3d_fullres nnUNetTrainerV2 Task002_Heart 2
nnunetV2命令:
nnUNetv2_train 002 3d_fullres 0
(3)训练3D U-Net cascade模型
nnunetV1命令:
# 第一步:3D low resolution U-Net训练
nnUNet_train 3d_lowres nnUNetTrainerV2 Task002_Heart 0
# 第二步:3D full resolution U-Net 训练
nnUNet_train 3d_cascade_fullres nnUNetTrainerV2CascadeFullRes Task002_Heart 0
nnunetV2命令:
# 第一步:3D low resolution U-Net训练
nnUNetv2_train 002 3d_lowres 0
# 第二步:3D full resolution U-Net 训练
nnUNetv2_train 002 3d_cascade_fullres 0
第四步,自动确定最佳配置:
五折交叉验证跑完后,可以设置自动识别最适合数据的组合,–strict 参数代表即使配置不存在仍继续执行。
nnunetV1命令:
nnUNet_find_best_configuration -m 2d 3d_fullres 3d_lowres 3d_cascade_fullres -t 002 --strict
nnunetV2命令:
nnUNetv2_find_best_configuration 002 -c 2d
第五步,模型测试:
nnunetV1命令:
nnUNet_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -t TASK_NAME_OR_ID -m CONFIGURATION
其中,INPUT_FOLDER 是测试数据集的路径,OUTPUT_FOLDER 为指定的输出文件夹,TASK_NAME_OR_ID 为任务 id 号,CONFIGURATION 代表所使用的 UNet 配置。
nnunetV2命令:
nnUNetv2_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -d DATASET_NAME_OR_ID -c CONFIGURATION --save_probabilities
交叉验证跑完可以采用以下命令:
nnUNetv2_predict -d Dataset002_Heart -i INPUT_FOLDER -o OUTPUT_FOLDER -f 0 1 2 3 4 -tr nnUNetTrainer -c 2d -p nnUNetPlans
第六步,后处理:
这个好像只有V2版本有,因为运行完第五步后,V1版本没有提示可以后处理的命令:

nnunetV2命令:
nnUNetv2_apply_postprocessing -i OUTPUT_FOLDER -o OUTPUT_FOLDER_PP -pp_pkl_file /mnt/data_2/qijingunet/nnUNet_trained_models/Dataset002_Heart/nnUNetTrainer__nnUNetPlans__2d/crossval_results_folds_0_1_2_3_4/postprocessing.pkl -np 8 -plans_json /mnt/data_2/qijingunet/nnUNet_trained_models/Dataset002_Heart/nnUNetTrainer__nnUNetPlans__2d/crossval_results_folds_0_1_2_3_4/plans.json
其中OUTPUT_FOLDER为上一步的输出路径,OUTPUT_FOLDER_PP为重新指定的新路径。
PS:修改epoch
nnunet默认训练1000个epoch,要是不想训练那么多怎么修改呢?
nnunetV1:在下面路径的py文件中,修改self.max_num_epochs
anaconda3/envs/myMRI/lib/python3.8/site-packages/nnunet/training/network_training/nnUNetTrainerV2.py
nnunetV2:在下面路径的py文件中,修改self.num_epochs
anaconda3/envs/myMRI/lib/python3.8/site-packages/nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py
其实,当自己一步步去做的时候,好像也不是很难~