前言
在上一篇文章中我们已经对闭散列的哈希表(线性探测法)和开散列的哈希表(哈希桶)进行了简单的模拟实现,由于是简单实现,功能简单、没有迭代器且不支持不同的类型(非泛型编程)。此时我们这篇文章主要是对上次开散列哈希表的完善并用其封装出unordered_map和unordered_set
上次哈希桶的代码
#pragma once
#include <vector>
//版本1
namespace HashBucket
{template <class K,class V>struct HashNode//表的节点(桶口){HashNode<K,V>* _next;pair<K, V> _kv;HashNode(const pair<K,V>& kv):_next(nullptr),_kv(kv){}};template<class K, class V>class HashTable{typedef HashNode<K,V> Node;public:HashTable(){_tables.resize(10, nullptr);_n=0;}Node* Find(const K& key){size_t hashi = key % _tables.size();//找下标Node* cur = _tables[hashi];while (cur)//走链表{if (cur->_kv.first == key)//找到了{return cur;}cur = cur->_next;//往下走}//找不到return nullptr;}bool Insert(const pair<K, V>& kv){//插入失败(找不到)if (Find(kv.first))return false;//扩容if (_n == _tables.size())//负载因子极限{vector< Node*> newtable(_tables.size() * 2, nullptr);//把旧桶的节点挂到新表新桶中for (size_t i=0;i<_tables.size();i++){Node* cur = _tables[i];//遍历走一个个旧桶while (cur){Node* next = cur->_next;//存一下next,待会可以往下走size_t hashi = cur->_kv.first % newtable.size();//节点挂到新桶的下标可能不一样//挂上新桶cur->_next = newtable[hashi];newtable[hashi] = cur;//往下走cur = next;}//把旧桶被移走的节点置空_tables[i] = nullptr;}_tables.swap(newtable);}size_t hashi = kv.first % _tables.size();//找到下标Node* newnode = new Node(kv);//开一个节点的空间//头插(入桶)newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}bool Erase(const K& key){size_t hashi = key % _tables.size();Node* prev = nullptr;//保存遍历节点的上一个Node* cur = _tables[hashi];while (cur) {if (cur->_kv.first == key)//找到{//删除if (prev)//节点有可能是头节点 prev非空,不是头节点{prev->_next = cur->_next;}else//要删除的节点是头节点{_tables[hashi] = cur->_next;}delete cur;_n--;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables; // 指针数组size_t _n;};}1.哈希表的改造
哈希表里面不止能存数字,还可能存字符串之类的,当然我们上面的哈希表是存不了字符串的,如果硬用字符串那么会报错:string类不能取模
1.1模板参数的改造
那么解决办法是什么呢?可以用仿函数去解决,也就是再加一层映射
若key不是整形先整成整形再与位置建立关系
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};template<class K, class V,class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K,V> Node;
public://...
private:vector<Node*> _tables; // 指针数组size_t _n;
};
1.2对不同的成员函数进行修改
存不同类型的值,对应不同的仿函数
然后哈希表中的成员函数大部分都要修改(凡是遇到求下标取模的),都要用仿函数去获取
比如:下面的Find
Node* Find(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();//找下标Node* cur = _tables[hashi];while (cur)//走链表{if (cur->_kv.first == key)//找到了{return cur;}cur = cur->_next;//往下走}//找不到return nullptr;
}当然insert和erase也要
bool Insert(const pair<K, V>& kv)
{Hash hs;//插入失败(找不到)if (Find(kv.first))return false;//扩容if (_n == _tables.size()){vector< Node*> newtable(_tables.size() * 2, nullptr);//把旧桶的节点挂到新表新桶中for (size_t i=0;i<_tables.size();i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;//找到下标,取模要调仿函数size_t hashi = hs(cur->_kv.first) % newtable.size();//挂上新桶cur->_next = newtable[hashi];newtable[hashi] = cur;//往下走cur = next;}//把旧桶被移走的节点置空_tables[i] = nullptr;}_tables.swap(newtable);}size_t hashi = hs(kv.first) % _tables.size();//找到下标,取模要调仿函数Node* newnode = new Node(kv);//头插(入桶)newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}bool Erase(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;//保存遍历节点的上一个Node* cur = _tables[hashi];while (cur) {if (cur->_kv.first == key)//找到{//删除if (prev)//节点有可能是头节点 prev非空,不是头节点{prev->_next = cur->_next;}else//要删除的节点是头节点{_tables[hashi] = cur->_next;}delete cur;_n--;return true;}prev = cur;cur = cur->_next;}return false;
}2.再次改造哈希表
把哈希表封装出unordered_map和unordered_set,这和之前红黑树封装出map和set类似
template<class K, class T>class HashTable对于unordered_map
template<class K, class V>
class myunorderedmap
{
public://...
private:HashTable<K, pair<const K, V>> _ht;
};对于unordered_set
template<class K>
class myunorderedset
{
public://...
private:HashTable<K, const K> _ht;
};
泛型编程 T可以是K也可以是pair<K,V>,所以节点的模板参数和存储的数据类型都要修改
template <class T>
struct HashNode//表的节点(桶口)
{HashNode<T>* _next;T _data;HashNode(const T& data):_next(nullptr), _data(data){}
};当然别忘了上面的更改(仿函数),不过仿函数还是由unordered_map和unordered_set来决定比较好;后面用到的data(上面代码中的kv.first)可能是unordered_map的键值对(pair<K,V>)也可能是unordered_set的键(key),底层哈希表并不知道是哪个,所以还要用一个仿函数来解决这一问题
那么对于unordered_map增加MapKeyOfT
template<class K, class V, class Hash = HashFunc<K>>
class myunorderedmap
{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public://...
private:HashTable<K, pair<const K, V>,MapKeyOfT,Hash> _ht;
};对于unordered_set增加SetKeyOfT
template<class K, class Hash = HashFunc<K>>
class myunorderedset
{struct SetKeyOfT{const K& operator()(const K& key){return key;}};
public://...
private:HashTable<K, const K,SetKeyOfT,Hash> _ht;
};当然哈希表也要有对应的接收
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{typedef HashNode<T> Node;
public://...
private:vector<Node*> _tables; // 指针数组size_t _n;
};这样一来,如果是unordered_map调用哈希表,就会用MapKeyOfT传给哈希表,如果是unordered_set调用哈希表,就用SetKeyOfT传给哈希表,那么哈希表就可以知道T是键还是键值对
既然这些增加了对应的仿函数和模板参数,和上文的仿函数类似,所有成员函数中需要用到key的都要用KeyOfT创建的对象去替换
KeyOfT kot;
kot(data);find函数修改
Node* Find(const K& key)
{Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();//找下标Node* cur = _tables[hashi];while (cur)//走链表{if (kot(cur->_data) == key)//找到了{return cur;}cur = cur->_next;//往下走}//找不到return nullptr;
}insert修改
bool Insert(const T& data)
{Hash hs;KeyOfT kot;//插入失败(找不到)if(Find(kot(data)))return false;//扩容if (_n == _tables.size())//负载因子极限{vector< Node*> newtable(_tables.size() * 2, nullptr);//把旧桶的节点挂到新表新桶中for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];//遍历走一个个旧桶while (cur){Node* next = cur->_next;//存一下next,待会可以往下走size_t hashi = hs(kot(cur->_data)) % newtable.size();//挂上新桶cur->_next = newtable[hashi];newtable[hashi] = cur;//往下走cur = next;}//把旧桶被移走的节点置空_tables[i] = nullptr;}_tables.swap(newtable);}size_t hashi = hs(kot(data)) % _tables.size();//找到下标Node* newnode = new Node(data);//开一个节点的空间//头插(入桶)newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}erase修改
bool Erase(const K& key)
{KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){// 删除if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;
}3.具体封装及其迭代器实现
3.1哈希表的构造与析构
构造还是之前的构造
至于析构,先遍历表(一个个桶往后走),再遍历表的过程中遍历桶
具体来说表走第一个桶,然后第一个桶往下走(遍历)删除节点,第一个桶删完,表往后走到第二个桶,第二个桶往下走删除节点,表往后走到第三个桶......
HashTable()//构造
{_tables.resize(10, nullptr);_n = 0;
}
~HashTable()//析构
{for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;_n--;cur = next;}_tables[i] = nullptr;}
}3.2迭代器的实现
3.2.1迭代器的框架
template<class K, class T, class KeyOfT, class Hash>
struct HTIterator
{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef HTIterator<K, T, KeyOfT, Hash> Self;
public:Node* _node;HT* _ht;
}这里要注意的是如果哈希表的实现是再迭代器的下面的话,迭代器的上面要对哈希表进行前置声明,不然编译器向上搜索不到哈希表的话会报错
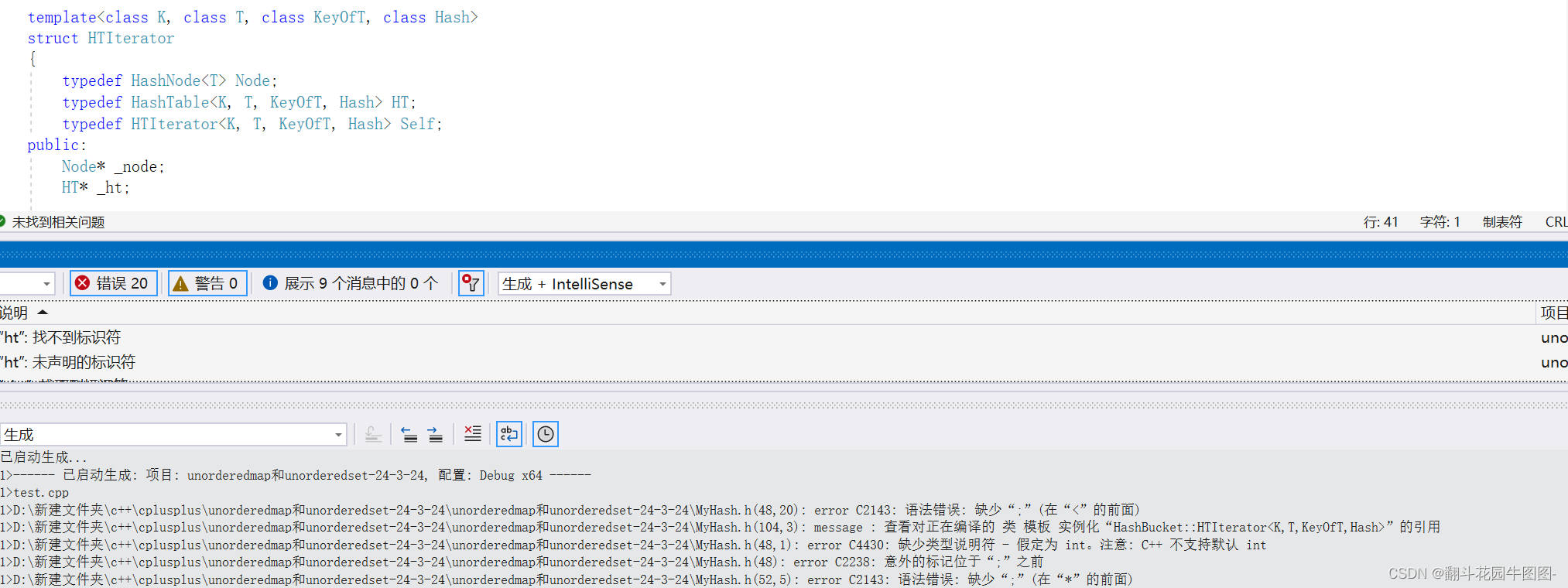
加了前置声明的话就不会
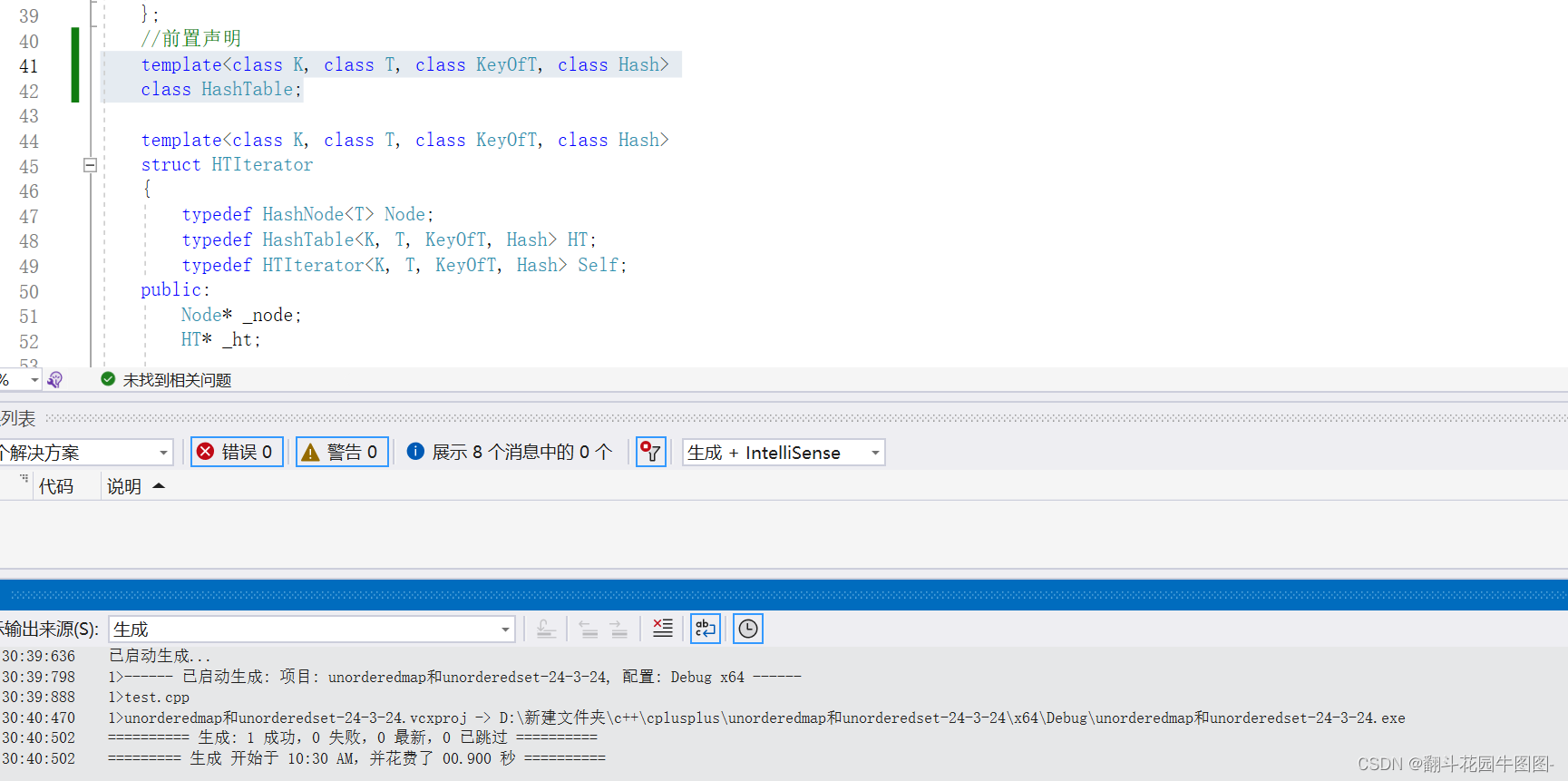
3.2.2迭代器的构造
HTIterator(Node* node,HT* ht)//构造:_node(node),_ht(ht)
{}3.2.3重载*操作符和重载->操作符
T& operator*()
{return _node->_data;
}
T* operator->()
{return &_node->_data;
}3.2.4重载操作符==和!=
bool operator==(const Self& it) const
{return _node == it._node;
}
bool operator!=(const Self& it) const
{return _node != it._node;
}3.2.5重载操作符++
如果当前桶还没走完,那么就这个桶(链表)继续往下走
如果走完了找下一个非空的桶,找到了下一个非空的桶则走到它的第一个节点,没找到走到空
Self& operator++()
{if (_node->_next)//当前桶还未走完{_node = _node->_next;}else{Hash hs;KeyOfT kot;//当前桶走完了,找下一个桶size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();//计算当前在哪个位置(桶上)hashi++;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi])//找到了{_node = _ht->_tables[hashi];break;}hashi++;}if (hashi == _ht->_tables.size())//走到后面没有桶了{_node = nullptr;}}return *this;
}4.源码
4.1unordered_map
#pragma once#include"MyHash.h"namespace HashBucket
{template<class K,class V, class Hash = HashFunc<K>>class myunorderedmap{struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};public:typedef typename HashBucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}bool Insert(const pair<K,V>& kv){return _ht.Insert(kv);}private:HashBucket::HashTable<K,pair<const K,V>,MapKeyOfT, Hash> _ht;};void test_map1(){myunorderedmap<string, string> dict;dict.Insert(make_pair("banana", "香蕉"));dict.Insert(make_pair("strawberry", "草莓"));dict.Insert(make_pair("orange", "橙子"));dict.Insert(make_pair("watermelon", "西瓜"));dict.Insert(make_pair("banana", "香蕉"));dict.Insert(make_pair("strawberry", "草莓"));for (auto& e : dict){cout << e.first << ":" << e.second<<endl;}}
}4.2unordered_set
#pragma once#include"MyHash.h"namespace HashBucket
{template<class K,class Hash = HashFunc<K>>class myunorderedset{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashBucket::HashTable<K, const K, SetKeyOfT, Hash>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}bool insert(const K& key){return _ht.Insert(key);}private:HashBucket::HashTable<K,const K,SetKeyOfT, Hash> _ht;};void test_set1(){myunorderedset<int> us;us.insert(19);us.insert(10);us.insert(11);us.insert(2);us.insert(9);us.insert(7);us.insert(3);us.insert(26);myunorderedset<int>::iterator it = us.begin();while(it!=us.end()){cout << *it << " ";++it;}cout << endl;for (auto& e : us){cout << e << " ";}cout << endl;}
}4.3Hash
#pragma once
#include<vector>
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};// 特化
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};
namespace HashBucket
{template <class T>struct HashNode//表的节点(桶口){HashNode<T>* _next;T _data;HashNode(const T& data):_next(nullptr), _data(data){}};//前置声明template<class K, class T, class KeyOfT, class Hash>class HashTable;template<class K, class T, class KeyOfT, class Hash>struct HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef HTIterator<K, T, KeyOfT, Hash> Self;public:Node* _node;HT* _ht;HTIterator(Node* node,HT* ht)//构造:_node(node),_ht(ht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}Self& operator++(){if (_node->_next)//当前桶还未走完{_node = _node->_next;}else{Hash hs;KeyOfT kot;//当前桶走完了,找下一个桶size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();//计算当前在哪个位置(桶上)hashi++;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi])//找到了{_node = _ht->_tables[hashi];break;}hashi++;}if (hashi == _ht->_tables.size())//走到后面没有桶了{_node = nullptr;}}return *this;}bool operator==(const Self& it) const{return _node == it._node;}bool operator!=(const Self& it) const{return _node != it._node;}};template<class K, class T, class KeyOfT, class Hash>class HashTable{template<class K, class T, class KeyOfT, class Hash>friend struct HTIterator;typedef HashNode<T> Node;public:typedef HTIterator<K, T, KeyOfT, Hash> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){// 找到第一个桶的第一个节点if (_tables[i]){return iterator(_tables[i], this);}}return end();}iterator end(){return iterator(nullptr,this);}HashTable()//构造{_tables.resize(10, nullptr);_n = 0;}~HashTable()//析构{for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;_n--;cur = next;}_tables[i] = nullptr;}}bool Insert(const T& data){Hash hs;KeyOfT kot;//插入失败(找不到)if(Find(kot(data)))return false;//扩容if (_n == _tables.size())//负载因子极限{vector< Node*> newtable(_tables.size() * 2, nullptr);//把旧桶的节点挂到新表新桶中for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];//遍历走一个个旧桶while (cur){Node* next = cur->_next;//存一下next,待会可以往下走size_t hashi = hs(kot(cur->_data)) % newtable.size();//节点挂到新桶的下标可能不一样//挂上新桶cur->_next = newtable[hashi];newtable[hashi] = cur;//往下走cur = next;}//把旧桶被移走的节点置空_tables[i] = nullptr;}_tables.swap(newtable);}size_t hashi = hs(kot(data)) % _tables.size();//找到下标Node* newnode = new Node(data);//开一个节点的空间//头插(入桶)newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();//找下标Node* cur = _tables[hashi];while (cur)//走链表{if (kot(cur->_data) == key)//找到了{return cur;}cur = cur->_next;//往下走}//找不到return nullptr;}bool Erase(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){// 删除if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables; // 指针数组size_t _n;};
}