R2GenCMN中的 Encoder_Decoder 结构
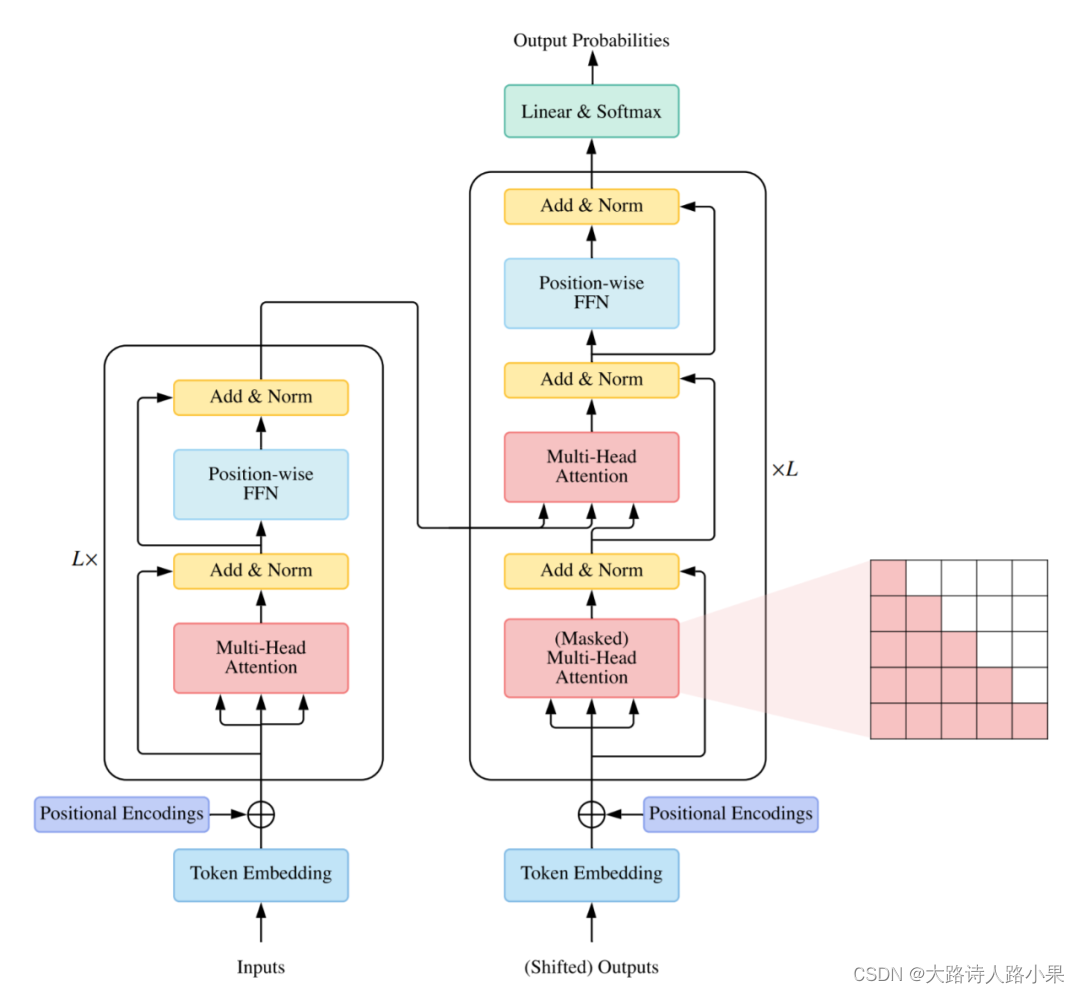
Encoder_Decoder 结构直接关系到文本的生成,它结构参考的transformer的结构

我们这里主要看代码的实现,从视觉编码器的输出开始
1. 模型结构
首先介绍一下整体结构,这里的baseCMN其实就是一个包装了的Transformer的 Transformer,这个Transformer里面是有n个连续的encoder和n个连续的decoder组成的。图片的输入进入encoder进行编码,这个过程是Transformer的结构,加入了位置编码和注意力机制。(凡是框框里面有的,都是一个类)
文章中的 CMN组件是在 encoder之后起作用的,CMN如同一个字典,(这是一个虚构的字典),这个字典负责查询,正常encoder的输出直接进入decoder就可以了,但是在这里,encoder的输出,需要先经过CMN的查询响应,与响应叠加之后的输出进入decoder。它同时对文本和图像两个变量进行索引和反馈,在prepare_feature的函数中,它将 图像的特征进行查询反馈。在decode过程中对 文本特征进行查询反馈。(这里今后我打算采用 稀疏学习 的方式进行优化)
decoder的结构是标准的Transfomer的decoder结构,有两个多头注意力机制,但是在这里,第一个多头注意力进行文本内容的注意力特征提取,第二头进行跨模态的特征提取,也就是使用x对图片的特征进行特征提取。
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
最终,得到输出。
2. 模型训练
文本生成模型是一个自回归模型,模型的不是一下子输出全部,而是一点一点的输出一个token,而这里的实现就是在使用core函数。实际上core函数并不是标准内置的响应函数,这个代码中,将使用forward和sample来进行区分运行的模式,在模型的训练阶段,模型的运行模式是自回归方式。对于自回归模型,如GPT系列,在模型的训练过程中,即使模型在某个步骤中预测错误(比如预测了“海边”而不是“公园”),下一步的训练输入仍然是真实的序列中的词(“公园”),而不是模型错误的预测结果(“海边”)。这样做的目的是加速(并行处理)训练并提高模型的稳定性和性能。
- 训练:
- 1. 并行处理: 尽管模型预测下一个词是基于之前的所有词,但在训练时,这个过程是并行化的。给定一个序列,模型能够同时计算序列中每个位置的输出。这是通过使用所谓的“掩码”技术在自注意力层中实现的,它防止位置注意到它之后的任何位置,确保预测仅依赖于之前的词和当前位置的词。
2.(Teacher foring): 给定序列的当前位置,模型使用之前位置的真实词(而不是模型自己生成的词)来预测下一个词。
这实际上也能看出来GPT模型的缺点,就是内容连贯性,但是如果模型一开始是错误的,那么模型的很容易一直错下去,生成开口完全一致,内容一模一样,如同幻觉一般的句子,如果数据集的多样性非常有限,就是文本之间非常像的话,最终模型的训练会陷入一个误区就是找整个数据集中的一个内容不变的句子,这个句子对于 整个数据集来说差异最小 。导致报告的生成陷入一个由于数据集差异太小,同时样本多数一致的 训练误区。
- 解决办法
- 找到一种办法就是可以 重新量化差异,让本来差异很小的数据集,在新的视角下,差异变大
3. 代码实现过程
encoder_decoder的传播函数
def _forward(self, fc_feats, att_feats, seq, att_masks=None):print(f"这里是encoder_decoder的forward")embed()att_feats, seq, att_masks, seq_mask = self._prepare_feature_forward(att_feats, att_masks, seq)out = self.model(att_feats, seq, att_masks, seq_mask)outputs = F.log_softmax(self.logit(out), dim=-1)return outputs
这里我们查看输入都是什么, 可以看到fc_feature= 2048 * 4 = 8192 的特征是我进行堆叠,图片att_feature是我进行了cat= 7* 7* 4
In [1]: fc_feats.shape
Out[1]: torch.Size([10, 8192])In [2]: att_feats.shape
Out[2]: torch.Size([10, 196, 2048])In [3]: seq.shape
Out[3]: torch.Size([10, 284])In [4]: att_masks.shape
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[4], line 1
----> 1 att_masks.shapeAttributeError: 'NoneType' object has no attribute 'shape'
经过prepare_feature,
In [5]: att_feats, seq, att_masks, seq_mask = self._prepare_feature_forward(att_feats, att_masks, seq)In [6]: att_feats.shape
Out[6]: torch.Size([10, 196, 512])In [7]: seq.shape
Out[7]: torch.Size([10, 283])In [8]: att_masks.shape
Out[8]: torch.Size([10, 1, 196])In [9]: seq_mask.shape
Out[9]: torch.Size([10, 283, 283])
在prepare的函数中,使用clip进行了特征的裁剪,如果是直接使用预训练的,我认为这样直接剪切是不合理,应该进行embedding进行映射
def _prepare_feature(self, fc_feats, att_feats, att_masks):att_feats, att_masks = self.clip_att(att_feats, att_masks)# embed fc and att featsfc_feats = self.fc_embed(fc_feats)att_feats = pack_wrapper(self.att_embed, att_feats, att_masks)# Project the attention feats first to reduce memory and computation comsumptions.p_att_feats = self.ctx2att(att_feats)
1. Transformer进行编码
1.1 Transformer架构
class Transformer(nn.Module):def __init__(self, encoder, decoder, src_embed, tgt_embed, cmn, model_type):super(Transformer, self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = src_embedself.tgt_embed = tgt_embedself.cmn = cmnself.model_type=model_typedef forward(self, src, tgt, src_mask, tgt_mask, memory_matrix=None):return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask, memory_matrix=memory_matrix)def encode(self, src, src_mask):return self.encoder(self.src_embed(src), src_mask)def decode(self, memory, src_mask, tgt, tgt_mask, past=None, memory_matrix=None):embeddings = self.tgt_embed(tgt)print(f"这个是transformer的decode函数")embed()#@ymy CLSif self.model_type=="CMN":# Memory querying and responding for textual featuresdummy_memory_matrix = memory_matrix.unsqueeze(0).expand(embeddings.size(0), memory_matrix.size(0), memory_matrix.size(1))responses = self.cmn(embeddings, dummy_memory_matrix, dummy_memory_matrix)embeddings = embeddings + responses# Memory querying and responding for textual features#@ymy SEPreturn self.decoder(embeddings, memory, src_mask, tgt_mask, past=past)
1.2 位置编码,和前馈网络 (Position-wise FFN), 注意力, 多头注意力
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, d_model, 2).float() *-(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):print(f"这里是PositionalEncoding的forward")embed()x = x + self.pe[:, :x.size(1)]return self.dropout(x)class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w_1 = nn.Linear(d_model, d_ff)self.w_2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):print(f"这里是 PositionwiseFeedForward 的forward")embed()return self.w_2(self.dropout(F.relu(self.w_1(x))))def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnclass MultiHeadedAttention(nn.Module):def __init__(self, h, d_model, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert d_model % h == 0self.d_k = d_model // hself.h = hself.linears = clones(nn.Linear(d_model, d_model), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None, layer_past=None):print(f"这里是多头注意力的forward")embed()if mask is not None:mask = mask.unsqueeze(1)nbatches = query.size(0)if layer_past is not None and layer_past.shape[2] == key.shape[1] > 1:query = self.linears[0](query)key, value = layer_past[0], layer_past[1]present = torch.stack([key, value])else:query, key, value = \[l(x) for l, x in zip(self.linears, (query, key, value))]if layer_past is not None and not (layer_past.shape[2] == key.shape[1] > 1):past_key, past_value = layer_past[0], layer_past[1]key = torch.cat((past_key, key), dim=1)value = torch.cat((past_value, value), dim=1)present = torch.stack([key, value])query, key, value = \[x.view(nbatches, -1, self.h, self.d_k).transpose(1, 2)for x in [query, key, value]]x, self.attn = attention(query, key, value, mask=mask,dropout=self.dropout)x = x.transpose(1, 2).contiguous() \.view(nbatches, -1, self.h * self.d_k)if layer_past is not None:return self.linears[-1](x), presentelse:return self.linears[-1](x)
1.3 模型框架,整体梳理
########### Encoder: #####################
ModuleList((0-2): 3 x EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0-3): 4 x Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionwiseFeedForward((w_1): Linear(in_features=512, out_features=512, bias=True)(w_2): Linear(in_features=512, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0-1): 2 x SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))
)########### Decoder: #####################
ModuleList((0-2): 3 x DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0-3): 4 x Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0-3): 4 x Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionwiseFeedForward((w_1): Linear(in_features=512, out_features=512, bias=True)(w_2): Linear(in_features=512, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0-2): 3 x SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))
)
1.4 模型的代码,这里我把类的名字改成了EncoderDecoder,实际上它原来是BaseCMN
class EncoderDecoder(AttModel):def __init__(self, args, tokenizer, model_type="base", core_type='fast'):super(EncoderDecoder, self).__init__(args, tokenizer)self.args = argsself.num_layers = args.num_layersself.d_model = args.d_modelself.d_ff = args.d_ffself.num_heads = args.num_headsself.dropout = args.dropoutself.topk = args.topktgt_vocab = self.vocab_size + 1self.cmn = MultiThreadMemory(args.num_heads, args.d_model, topk=args.topk)self.model_type = model_typeself.core_type = core_typeself.model = self.make_model(tgt_vocab, self.cmn)self.logit = nn.Linear(args.d_model, tgt_vocab)self.memory_matrix = nn.Parameter(torch.FloatTensor(args.cmm_size, args.cmm_dim))nn.init.normal_(self.memory_matrix, 0, 1 / args.cmm_dim)def make_model(self, tgt_vocab, cmn):c = copy.deepcopyattn = MultiHeadedAttention(self.num_heads, self.d_model)ff = PositionwiseFeedForward(self.d_model, self.d_ff, self.dropout)position = PositionalEncoding(self.d_model, self.dropout)model = Transformer(Encoder(EncoderLayer(self.d_model, c(attn), c(ff), self.dropout), self.num_layers),Decoder(DecoderLayer(self.d_model, c(attn), c(attn), c(ff), self.dropout), self.num_layers),nn.Sequential(c(position)),nn.Sequential(Embeddings(self.d_model, tgt_vocab), c(position)), cmn,self.model_type)for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)return modeldef init_hidden(self, bsz):return []def _prepare_feature(self, fc_feats, att_feats, att_masks):att_feats, seq, att_masks, seq_mask = self._prepare_feature_forward(att_feats, att_masks)memory = self.model.encode(att_feats, att_masks)return fc_feats[..., :1], att_feats[..., :1], memory, att_masksdef _prepare_feature_forward(self, att_feats, att_masks=None, seq=None):#att_feats, att_masks = self.clip_att(att_feats, att_masks)att_feats = pack_wrapper(self.att_embed, att_feats, att_masks)if att_masks is None:att_masks = att_feats.new_ones(att_feats.shape[:2], dtype=torch.long)#@ymy CLS# Memory querying and responding for visual featuresif self.model_type=="CMN":print(f"这里是prepare feature forward")embed()dummy_memory_matrix = self.memory_matrix.unsqueeze(0).expand(att_feats.size(0), self.memory_matrix.size(0), self.memory_matrix.size(1))responses = self.cmn(att_feats, dummy_memory_matrix, dummy_memory_matrix)att_feats = att_feats + responses# Memory querying and responding for visual features##@ymy SEPatt_masks = att_masks.unsqueeze(-2)if seq is not None:seq = seq[:, :-1]seq_mask = (seq.data > 0)seq_mask[:, 0] += Trueseq_mask = seq_mask.unsqueeze(-2)seq_mask = seq_mask & subsequent_mask(seq.size(-1)).to(seq_mask)else:seq_mask = Nonereturn att_feats, seq, att_masks, seq_maskdef _forward(self, fc_feats, att_feats, seq, att_masks=None):att_feats, seq, att_masks, seq_mask = self._prepare_feature_forward(att_feats, att_masks, seq)#@ymy CLSif self.model_type=="CMN":out = self.model(att_feats, seq, att_masks, seq_mask, memory_matrix=self.memory_matrix)else:out = self.model(att_feats, seq, att_masks, seq_mask)#@ymy SEPoutputs = F.log_softmax(self.logit(out), dim=-1)return outputsdef _save_attns(self, start=False):if start:self.attention_weights = []self.attention_weights.append([layer.src_attn.attn.cpu().numpy() for layer in self.model.decoder.layers])def core(self, it, fc_feats_ph, att_feats_ph, memory, state, mask):if len(state) == 0:ys = it.unsqueeze(1)past = [fc_feats_ph.new_zeros(self.num_layers * 2, fc_feats_ph.shape[0], 0, self.d_model),fc_feats_ph.new_zeros(self.num_layers * 2, fc_feats_ph.shape[0], 0, self.d_model)]else:ys = torch.cat([state[0][0], it.unsqueeze(1)], dim=1)past = state[1:]#@ymy CLSif self.model_type=="CMN":out, past = self.model.decode(memory, mask, ys, subsequent_mask(ys.size(1)).to(memory.device), past=past,memory_matrix=self.memory_matrix)else:out, past = self.model.decode(memory, mask, ys, subsequent_mask(ys.size(1)).to(memory.device), past=past)#@ymy SEPif not self.training:self._save_attns(start=len(state) == 0)return out[:, -1], [ys.unsqueeze(0)] + past