B站视频:https://www.bilibili.com/video/BV1nx4y1v7F5/
白话知识蒸馏
在前面,我们了解了BERT的工作原理,并探讨了BERT的不同变体。我们学习了如何针对下游任务微调预训练的BERT模型,从而省去从头开始训练BERT的时间。但是,使用预训练的BERT模型有一个难点,那就是它的计算成本很高,在有限的资源下很难运行。预训练的BERT模型有大量的参数,需要很长的运算时间,这使得它更难在手机等移动设备上使用。
为了解决这个问题,可以使用知识蒸馏法将知识从预训练的大型BERT模型迁移到小型BERT模型。
我们将了解基于知识蒸馏的BERT变体。首先,我们将了解知识蒸馏及其工作原理。然后,我们将学习DistilBERT模型。通过DistilBERT模型,我们将了解如何利用知识蒸馏将知识从一个预训练的大型BERT模型迁移到一个小型BERT模型中。
接下来,我们将学习TinyBERT模型。我们将了解什么是TinyBERT模型,以及它如何利用知识蒸馏从预训练的大型BERT模型中获取知识。我们还将探讨在TinyBERT模型中使用的几种数据增强方法。
最后,我们将学习如何将知识从一个预训练的大型BERT模型迁移到简单的神经网络中。
1 知识蒸馏简介
知识蒸馏(knowledge distillation)是一种模型压缩技术,它是指训练一个小模型来重现大型预训练模型的行为。知识蒸馏也被称为师生学习,其中大型预训练模型是教师,小模型是学生。让我们通过一个例子来了解知识蒸馏是如何实现的。
假设预先训练了一个大模型来预测句子中的下一个单词。我们将大型预训练模型称为教师网络。我们输入一个句子,让网络预测句子中的下一个单词。它将返回词表中所有单词是下一个单词的概率分布,如图所示。为了更好地理解,我们假设词表中只有5个单词。
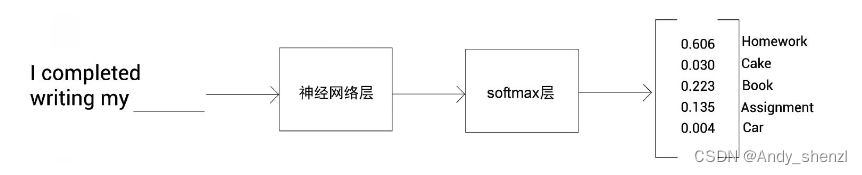
从图中可以看到网络所返回的概率分布,这个概率分布是由softmax函数应用于输出层求得的。我们选择概率最高的单词作为句子中的下一个单词。因为Homework这个单词的概率最高,所以句子中的下一个单词为Homework。
除了选择具有高概率的单词外,能否从网络返回的概率分布中提取一些其他有用的信息呢?答案是肯定的。从下图中可以看到,除了概率最高的单词,还有一些单词的概率也相对较高。具体地说,Book和Assignment这两个单词的概率比Cake和Car略高。
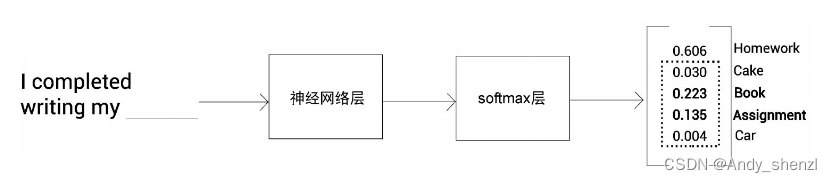
这表明,除了Homework这个单词,Book和Assignment这两个单词与Cake和Car这样的单词相比,与输入的句子更为相关。这就是我们所说的隐藏知识。在知识蒸馏过程中,我们希望学生网络能从教师网络那里学到这些隐藏知识。
但通常情况下,任何好的模型都会为正确的类别返回一个接近1的高概率,而为其他类别返回非常接近0的概率。在本例中,假设模型已经返回了以下的概率分布。

从上图中,可以看到模型对Homework这个单词返回了一个非常高的概率,而对其他单词,概率都接近于或等于0。除了真值(正确的词)外,概率分布中没有其他太多的信息。那么如何提取隐藏知识呢?
这里,需要使用带有温度系数的softmax函数,它被称为softmax温度。我们在输出层使用softmax温度,用来平滑概率分布。带有温度系数的softmax函数如下所示。
p i = e x p ( z i / T ) ∑ j e x p ( z i / T ) p_i = \frac{exp(z_i/T)}{\sum_jexp(z_i/T)} pi=∑jexp(zi/T)exp(zi/T)
在上面的公式中,T 表示temperature,即温度。如果 T = 1 T =1 T=1 ,它就是标准的softmax函数。增加T值,可以使概率分布更加平滑,并提供更多关于其他类别的信息。
如图5-4所示,当 T = 1 T =1 T=1 时,我们将得到与使用标准softmax函数相同的概率分布。当 T = 2 T =2 T=2 时,概率分布会变平滑,而当 T = 5 T =5 T=5 时,概率分布会更加平滑。因此,通过增加 T T T 值,我们可以得到一个平滑的概率分布,从而得到更多关于其他类别的信息。
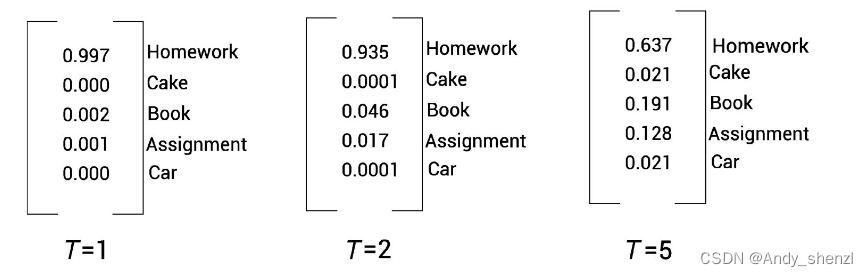
通过softmax温度,我们可以获得隐藏知识,即先用softmax温度对教师网络进行预训练,获得隐藏知识,然后在知识蒸馏过程中,将这些隐藏知识从教师网络迁移到学生网络。
2 训练学生网络
我们已经学习了如何预训练网络,使其可以预测句子中的下一个单词。这个预训练网络被称为教师网络。现在,让我们来学习如何将知识从教师网络迁移到学生网络。请注意,学生网络并没有经过预训练,只有教师网络经过预训练,并且在预训练过程中使用了softmax温度。
如下图所示,将输入句送入教师网络和学生网络,并得到概率分布作为输出。我们知道,教师网络是一个预训练网络,所以教师网络返回的概率分布是我们的目标。教师网络的输出被称为软目标,学生网络做出的预测则被称为软预测。
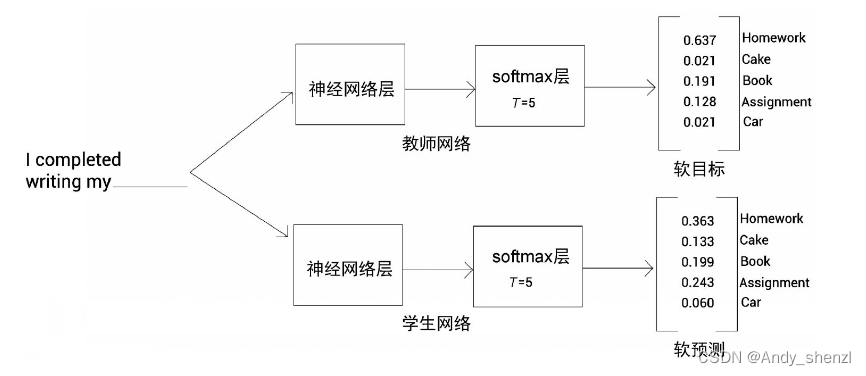
现在,我们来计算软目标和软预测之间的交叉熵损失,并通过反向传播训练学生网络,以使交叉熵损失最小化。软目标和软预测之间的交叉熵损失也被称为蒸馏损失。我们可以从下图中看到,在教师网络和学生网络中,softmax层的T值保持一致,且都大于1。
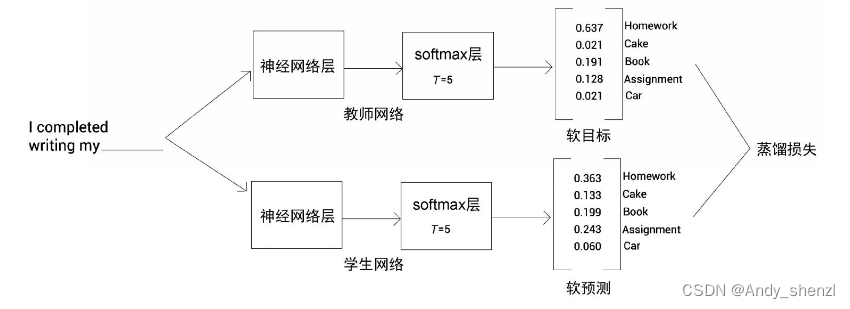
我们通过反向传播算法训练学生网络以使蒸馏损失最小化。除了蒸馏损失外,我们还使用另一个损失,称为学生损失。
为了理解学生损失,我们首先了解软目标和硬目标之间的区别。如图所示,采用教师网络返回的概率分布被称为软目标,而硬目标就是将高概率设置为1,其余概率设置为0。

现在,我们了解一下软预测和硬预测的区别。软预测是学生网络预测的概率分布,其中 T T T大于1,而硬预测是由 T = 1 T =1 T=1得到的概率分布。也就是说,硬预测是指使用标准的softmax函数预测,其中 T = 1 T =1 T=1。
学生损失就是硬目标和硬预测之间的交叉熵损失。下图展示了如何计算学生损失和蒸馏损失。可以看出,为了计算学生损失,在学生网络中使用[插图]的softmax函数,得到硬预测。通过在软目标中,将具有高概率的位置设置为1,将其他位置设置为0来获得硬目标。然后,计算硬预测和硬目标之间的交叉熵损失,即学生损失。
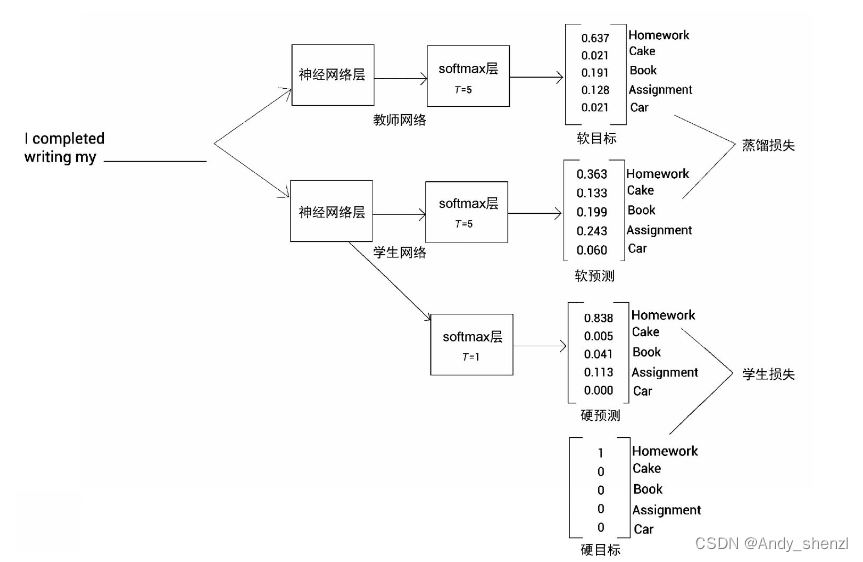
为了计算蒸馏损失,我们使用T大于1的softmax函数计算软预测和软目标之间的交叉熵损失,即蒸馏损失。
最终的损失函数是学生损失和蒸馏损失的加权和,即:
L = α ⋅ 学生损失 + β ⋅ 蒸馏损失 L = \alpha·学生损失 + \beta·蒸馏损失 L=α⋅学生损失+β⋅蒸馏损失
α 和 β \alpha和\beta α和β是用于计算学生损失和蒸馏损失的加权平均值的超参数。我们通过最小化上述损失函数来训练学生网络。
总结一下,在知识蒸馏中,我们把预训练网络作为教师网络,并训练学生网络通过蒸馏从教师网络获得知识。训练学生网络需要最小化损失,该损失是学生损失和蒸馏损失的加权和。
3 DistilBERT模型——BERT模型的知识蒸馏版本
预训练的BERT模型有大量的参数,运算时间也很长,这使得它很难在智能手机等移动设备上使用。为了解决这个问题,Hugging Face的研究人员开发了DistilBERT模型。DistilBERT模型是一个更小、更快、更便宜、轻量级版本的BERT模型。
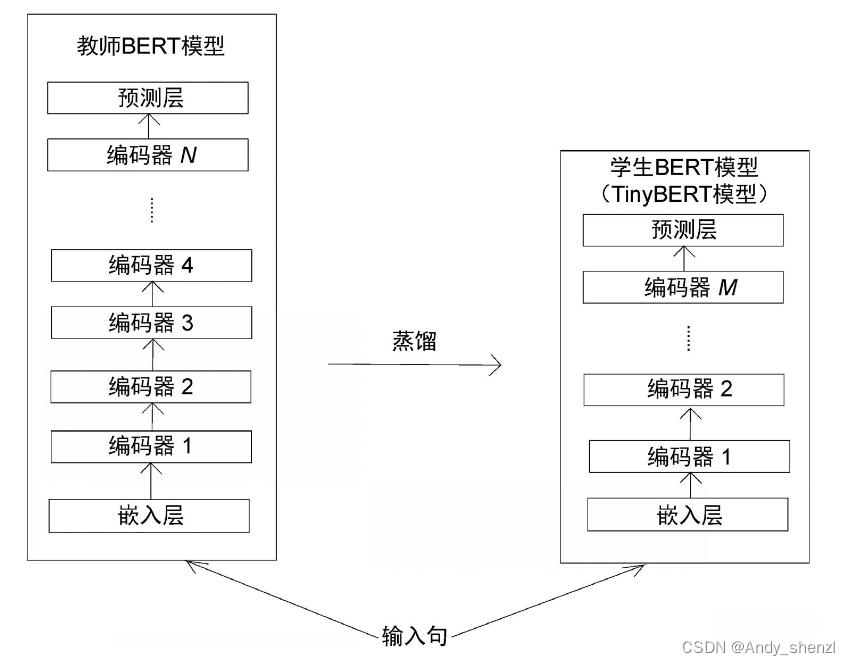
顾名思义,DistilBERT模型采用了知识蒸馏法。DistilBERT的理念是,采用一个预训练的大型BERT模型,通过知识蒸馏将其知识迁移到小型BERT模型中。预训练的大型BERT模型称为教师BERT模型,而小型BERT模型称为学生BERT模型。
与大型BERT模型相比,DistilBERT模型的速度要快60%,但其大小要小40%。现在,我们对DistilBERT模型有了基本的认识,下面让我们通过细节了解它的工作原理。
3.1 教师−学生架构
让我们详细了解教师BERT模型和学生BERT模型的架构。首先,看一下教师BERT模型,然后再看学生BERT模型。
教师BERT模型
教师BERT模型是一个预训练的大型BERT模型。我们使用预训练的BERT-base模型作为教师。在前面我们已经学习了BERT-base模型是如何进行预训练的。我们已知,BERT-base模型是使用掩码语言模型构建任务和下句预测任务进行预训练的。
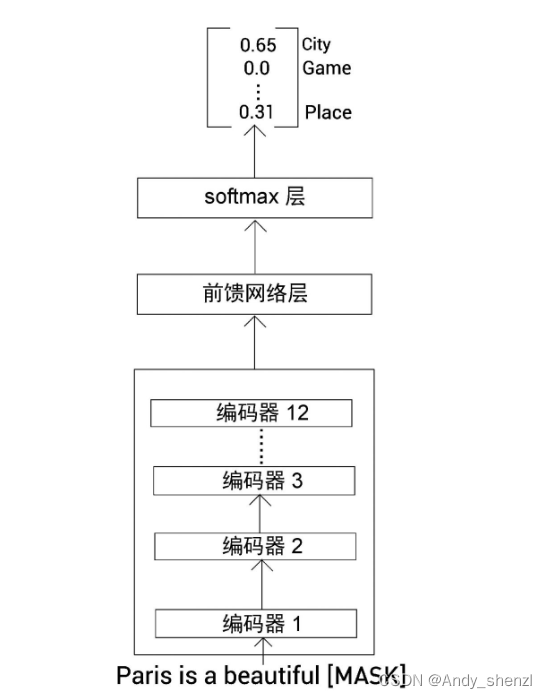
因为BERT是使用掩码语言模型构建任务进行预训练的,所以可以使用预训练的BERT-base模型来预测掩码单词。预训练的BERT-base模型如下图所示。
从图中可以看到,输入一个带掩码的句子,预训练的BERT模型输出了词表中所有单词是掩码单词的概率分布。这个概率分布包含隐藏知识,我们需要将这些知识迁移到学生BERT模型中。下面,让我们看看这是如何实现的。
学生BERT模型
与教师BERT模型不同,学生BERT模型没有经过预训练。学生BERT模型必须向老师学习。它是一个小型BERT模型,与教师BERT模型相比,它包含的层数较少。教师BERT模型包含1.1亿个参数,而学生BERT模型仅包含6600万个参数。
因为学生BERT模型中的层数较少,所以与教师BERT模型(BERT-base模型)相比,它的训练速度更快。
DistilBERT模型的研究人员将学生BERT模型的隐藏层大小保持在768,与教师BERT模型(BERT-base模型)的设置一样。他们发现,减少隐藏层的大小对计算效率的影响并不明显,所以,他们只关注减少层数。
3.2 训练学生BERT模型(DistilBERT模型)
训练学生BERT模型可以使用预训练的教师BERT模型所使用的相同数据集。我们知道,BERT-base模型是使用英语维基百科和多伦多图书语料库数据集进行预训练的,同样,我们可以使用这些数据集来训练学生BERT模型(小型BERT模型)。
我们可以从RoBERTa模型中借鉴一些训练策略。RoBERTa是一个BERT变体。这里,我们只使用掩码语言模型构建任务来训练学生BERT模型,并在该任务中使用动态掩码,同时在每次迭代中采用较大的批量值。
如下图所示,将一个含掩码的句子作为输入送入教师BERT模型(预训练BERT-base模型)和学生BERT模型,得到词表的概率分布。接下来,计算软目标和软预测之间的交叉熵损失作为蒸馏损失。
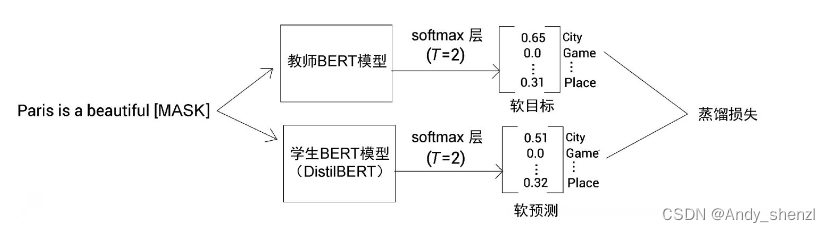
在计算蒸馏损失时,我们同时计算了学生损失,即掩码语言模型损失,也就是硬目标(事实真相)和硬预测( T = 1 T=1 T=1的标准softmax函数预测)之间的交叉熵损失,如下图
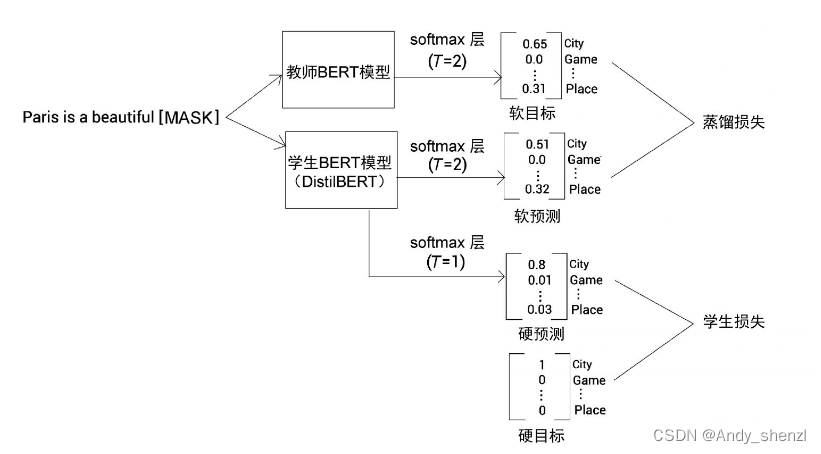
除了蒸馏损失和学生损失,还需计算余弦嵌入损失(cosine embedding loss)。它是教师BERT模型和学生BERT模型所学的特征向量之间的距离。最小化余弦嵌入损失将使学生网络的特征向量更加准确,与教师网络的嵌入向量更接近。
可见,损失函数是以下3种损失之和:
- 蒸馏损失;
- 掩码语言模型损失(学生损失);
- 余弦嵌入损失。
我们通过最小化以上3个损失之和来训练学生BERT模型(DistilBERT模型)。经过训练,学生BERT模型会习得教师BERT模型的知识。
DistilBERT模型可以达到BERT-base模型几乎97%的准确度。由于DistilBERT模型更加轻便,因此我们可以很容易地将其部署在任何终端设备上。与BERT模型相比,它的运算速度快了60%。
DistilBERT模型在8块16 GB的V100 GPU上进行了大约90小时的训练。Hugging Face已对外公开预训练的DistilBERT模型。正如原始BERT模型,我们也可以下载预训练好的DistilBERT模型,并为下游任务进行微调。
研究人员针对问答任务对预训练的DistilBERT模型进行了微调,并将其部署在iPhone 7 Plus上。他们将DistilBERT模型的运算速度与基于BERT-base模型的问答任务的运算速度做了比较,发现DistilBERT模型的运算速度比BERT-base模型快了71%,但模型大小只有207 MB。
4 TinyBERT模型简介
TinyBERT模型是BERT模型的另一个有趣的变体,它也使用了知识蒸馏法。通过DistilBERT模型,我们学会了如何将知识从教师BERT模型的输出层迁移到学生BERT模型中。但除此之外,还能从教师BERT模型的其他层迁移知识吗?答案是肯定的。
在TinyBERT模型中,除了从教师BERT模型的输出层(预测层)向学生BERT模型迁移知识外,还可以从嵌入层和编码层迁移知识。
让我们看一个例子。假设有一个N层编码器的教师BERT模型。为了避免重复,下图中只显示了预训练的教师BERT模型中的一个编码器层。输入一个含掩码的句子,教师BERT模型返回词表中所有被掩盖单词的logit向量。
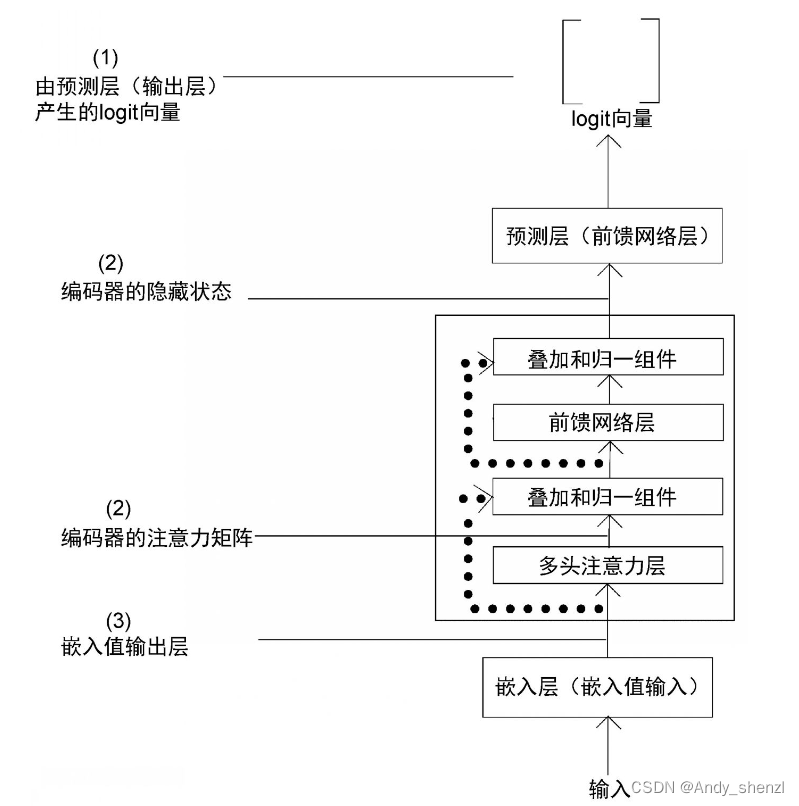
在DistilBERT模型中,我们用教师BERT模型的输出层产生的logit向量(1)训练学生BERT模型以产生同样的logit向量。除此以外,在TinyBERT模型中,我们还用教师BERT模型产生的隐藏状态和注意力矩阵(2)来训练学生BERT模型以产生相同的隐藏状态和注意力矩阵。接下来,从教师BERT模型中获取嵌入层的输出(3)来训练学生BERT模型,使其产生与教师BERT模型相同的嵌入矩阵。
因此,在TinyBERT模型中,除了将知识从教师BERT模型的输出层迁移到学生BERT模型外,我们还将中间层的知识迁移到学生网络中,这有助于学生BERT模型从教师BERT模型那里获得更多的信息。比如,注意力矩阵包含语法信息。通过迁移教师BERT模型的注意力矩阵中的知识,有助于学生BERT模型从教师BERT模型那里获得语法信息。
除此之外,在TinyBERT模型中,我们使用了一个两阶段学习框架,即在预训练阶段和微调阶段都应用知识蒸馏法。下面,我们将了解两阶段学习究竟是如何进行的。
4.1 教师−学生架构
为了理解TinyBERT模型的工作原理,我们首先了解一下预设条件和所使用的符号。下图展示了TinyBERT模型的教师−学生架构。
教师BERT模型
如上图所示,教师BERT模型由N个编码器组成。将输入句送入嵌入层,得到输入嵌入。接下来,将输入嵌入传递给编码器层。这些编码器层利用自注意力机制学习输入句的上下文关系并返回特征。然后,将该特征送入预测层。
预测层是一个前馈网络。如果执行的是掩码语言模型构建任务,那么预测层将返回词表中所有单词是掩码单词的logit向量。
我们使用预训练的BERT-base模型作为教师BERT模型。BERT-base模型包含12层编码器和12个注意力头,其所生成的特征大小(隐藏状态维度 d d d)为768。教师BERT模型包含1.1亿个参数。
学生BERT模型
如图5-13所示,学生BERT模型的架构与教师BERT模型相似,但不同的是,学生BERT模型由M 个编码器组成,且N大于M 。也就是说,教师BERT模型中的编码器层数大于学生BERT模型中的编码器层数。
我们使用具有4层编码器的BERT模型作为学生BERT模型,并将特征大小(隐藏状态维度[插图])设置为312。学生BERT模型只包含1450万个参数。
现在我们了解了TinyBERT模型的教师−学生架构,但蒸馏究竟是如何进行的?我们如何将知识从教师BERT模型迁移到学生BERT模型(TinyBERT模型)?
4.2 TinyBERT模型的蒸馏
我们已知除了从教师BERT模型的输出层(预测层)向学生BERT模型迁移知识外,也可以从其他层迁移知识。下面,让我们看看在以下各层中,蒸馏是如何进行的。
- Transformer层(编码器层)
- 嵌入层(输入层)
- 预测层(输出层)
下图显示了教师BERT模型和学生BERT模型(TinyBERT模型)的架构。
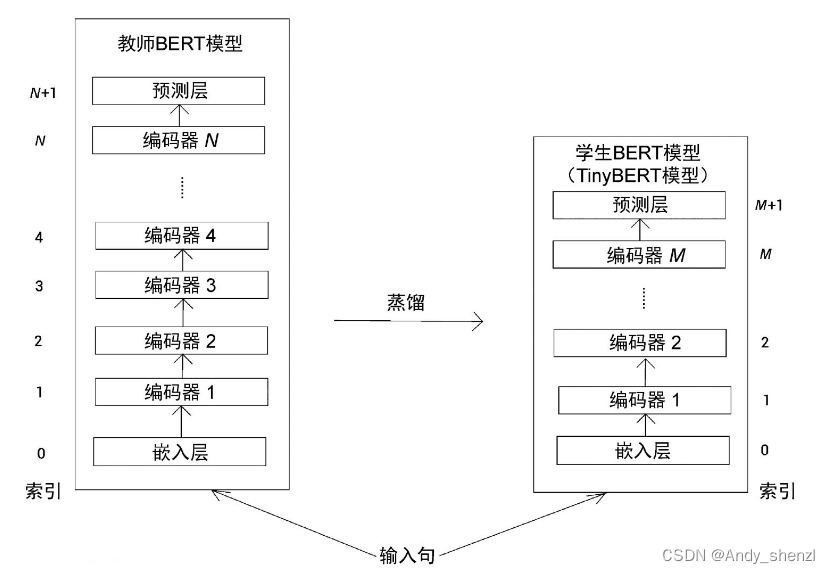
注意,在教师BERT模型中,索引0表示嵌入层,1表示第1个编码器,2表示第2个编码器。N表示第N个编码器,而N+1表示预测层。同样,在学生BERT模型中,索引0表示嵌入层,1表示第1个编码器,2表示第2个编码器。M表示第M个编码器,M+1表示预测层。
将知识从教师BERT模型迁移到学生BERT模型的过程如下。
n = g ( m ) n=g(m) n=g(m)
上面的公式表示使用映射函数g,将知识从教师BERT模型的第n层迁移到学生BERT模型的第m层。也就是说,学生BERT模型的第m层学习到了教师BERT模型的第n层的信息。
举例如下:
- 0 = g ( 0 ) 0 = g(0) 0=g(0)表示将知识从教师BERT模型的第0层(嵌入层)迁移到学生BERT模型的第0层(嵌入层);
- N + 1 = g ( M + 1 ) N+1 = g(M+1) N+1=g(M+1)表示将知识从教师BERT模型的第[插图]层(预测层)迁移到学生BERT模型的第[插图]层(预测层)。
现在,我们对TinyBERT模型中的知识蒸馏方法有了基本的认识。下面将讲解知识蒸馏是如何在每一层发生的。
4.3 Transformer层蒸馏
Transformer层就是编码器层。我们知道在编码器层,使用多头注意力来计算注意力矩阵,然后将隐藏状态的特征作为输出。在Transformer层蒸馏中,我们除了将知识从教师的注意力矩阵迁移到学生中,也将知识从教师的隐藏状态迁移到学生中。因此,Transformer层蒸馏包括两次知识蒸馏。
- 基于注意力的蒸馏
- 基于隐藏状态的蒸馏
首先,让我们了解基于注意力的蒸馏是如何工作的。
基于注意力的蒸馏
在基于注意力的蒸馏中,我们将注意力矩阵中的知识从教师BERT模型迁移到学生BERT模型。注意力矩阵含有不少有用的信息,如句子结构、指代信息等。这些信息有助于更好地理解语言。因此,将注意力矩阵的知识从教师迁移到学生中非常有用。
为了进行基于注意力的蒸馏,可以通过最小化学生BERT模型和教师BERT模型注意力矩阵的均方误差来训练学生网络。基于注意力的蒸馏损失 L a t t n L_{attn} Lattn的计算公式如下所示。
L a t t n = 1 n ∑ i = 1 h M S E ( A i S , A i T ) L_{attn} = \frac1n\sum_{i=1}^hMSE(A_i^S,A_i^T) Lattn=n1i=1∑hMSE(AiS,AiT)
因为Transformer采用多头注意力机制,所以,上面公式中的符号含义如下。
- h h h表示注意力头的数量。
- A i S A_i^S AiS表示学生网络的第 i i i个注意力头的注意力矩阵。
- A i T A_i^T AiT表示教师网络的第 i i i个注意力头的注意力矩阵。
- MSE表示均方误差。
可见,我们通过最小化学生和教师的注意力矩阵之间的均方误差来进行基于注意力的蒸馏。需要注意的是,我们使用的是一个未归一化的注意力矩阵,即未被softmax函数处理过的注意力矩阵。这是因为未归一化的注意力矩阵表现得更好且能更快地收敛。这一过程如图所示。
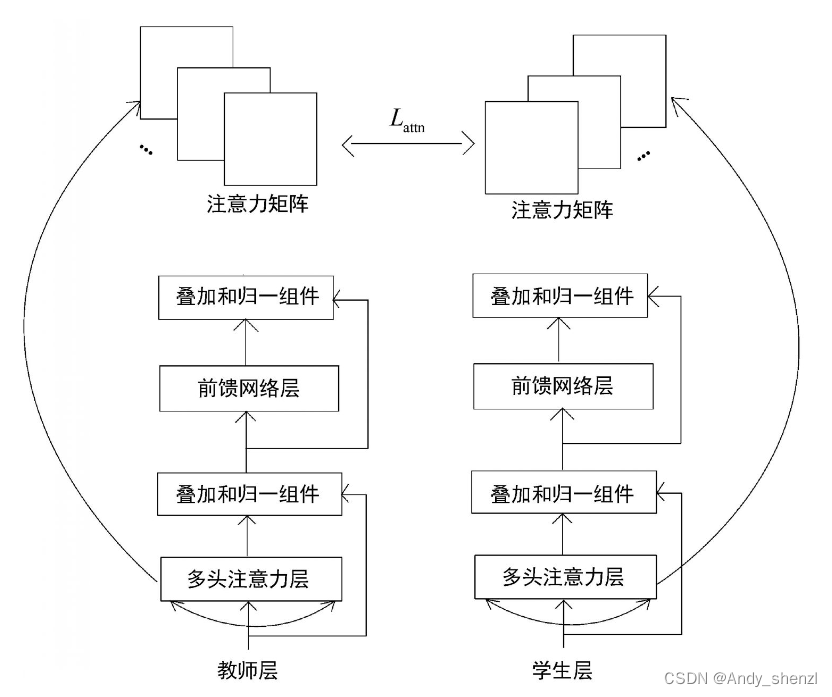
从上图中,可以看到我们是如何将注意力矩阵中的知识从教师BERT模型迁移到学生BERT模型中的。
基于隐藏状态的蒸馏
现在,让我们看看如何进行基于隐藏状态的蒸馏。隐藏状态是编码器的输出,也就是特征值。因此,在基于隐藏状态的蒸馏中,我们是将知识从教师编码器的隐藏状态迁移到学生编码器的隐藏状态。用 H S H^S HS表示学生的隐藏状态, H T H^T HT表示教师的隐藏状态。然后,通过最小化 H T H^T HT和 H S H^S HS之间的均方误差来进行蒸馏,如下所示。
L h i d n = M S E ( H S , H T ) L_{hidn} = MSE(H^S,H^T) Lhidn=MSE(HS,HT)
但 H T H^T HT和 H S H^S HS的维度是不同的。d表示 H T H^T HT的维度,而 d ‘ d^` d‘表示 H S H^S HS的维度。我们已知教师BERT模型是BERT-base模型,而学生BERT模型是TinyBERT模型,所以d总是大于 d ‘ d^` d‘。
因此,为了使学生的隐藏状态 H S H^S HS与教师的隐藏状态 H T H^T HT在同一个维度上,我们将 H S H^S HS乘以矩阵 W h W^h Wh进行线性变换。请注意, W h W^h Wh的值是在训练中学习的。我们将损失函数进行改写,如下所示。
L h i d n = M S E ( H S W h , H T ) L_{hidn} = MSE(H^SW_h,H^T) Lhidn=MSE(HSWh,HT)
从上面的公式可以看出,将 H S H^S HS与矩阵 W h W^h Wh相乘,从而对 H S H^S HS进行变换,使其与 H T H^T HT在同一维度上。如图所示,我们可以看到隐藏状态的知识是如何从教师BERT模型迁移到学生BERT模型的。
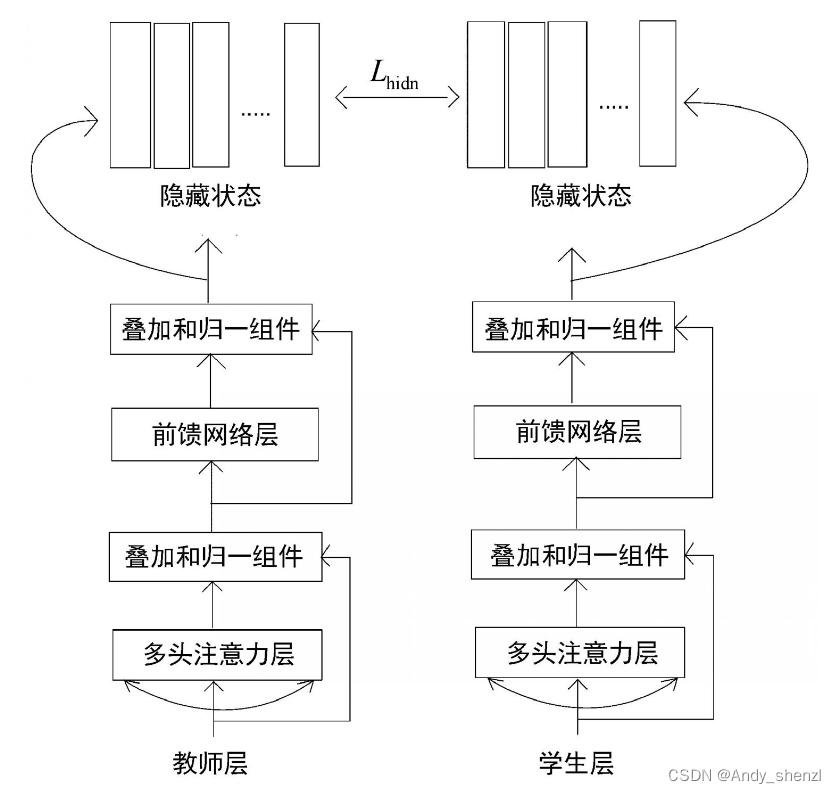
嵌入层蒸馏
在嵌入层蒸馏中,知识将从教师的嵌入层迁移到学生的嵌入层。我们用 E S E^S ES表示学生的嵌入矩阵, E T E^T ET表示教师的嵌入矩阵,那么通过最小化 E S E^S ES和 E T E^T ET之间的均方误差来训练网络进行嵌入层蒸馏,如下所示。
L e m b d = M S E ( E S , E T ) L_{embd} = MSE(E^S,E^T) Lembd=MSE(ES,ET)
同样,学生的嵌入矩阵和教师的嵌入矩阵的维度也不同。因此,需要将学生的嵌入矩阵 E S E^S ES乘以 W e W_e We,使其与教师的嵌入矩阵处于同一空间。得到的损失函数如下所示。
L e m b d = M S E ( E S W e , E T ) L_{embd} = MSE(E^SW_e,E^T) Lembd=MSE(ESWe,ET)
预测层蒸馏
在预测层蒸馏中,我们迁移的是最终输出层的知识,即教师BERT模型产生的logit向量。与DistilBERT模型的蒸馏损失相似,我们通过最小化软目标和软预测之间的交叉熵损失来进行预测层蒸馏。用 Z S Z^S ZS表示学生网络的logit向量, Z T Z^T ZT表示教师网络的logit向量,损失函数表示如下。
L p r e d = − s o f t m a x ( Z T ) ⋅ l o g − s o f t m a x ( Z S ) L_{pred} = -softmax(Z^T)· log_-softmax(Z^S) Lpred=−softmax(ZT)⋅log−softmax(ZS)
4.4 最终损失函数
包含所有层的蒸馏损失的损失函数如下所示。
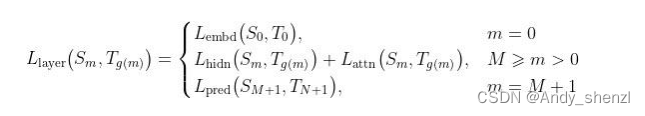
从上面的公式中,可以得出以下结论。
- 当m为0时,表示训练层是嵌入层,所以使用嵌入层损失。
- 当m大于0且小于或等于M时,表示训练层是Transformer层(编码器层),所以用隐藏状态损失和注意力层损失之和作为Transformer层的损失。
- 当m为M+1时,表示训练层是预测层,所以使用预测层损失。最终的损失函数如下所示。
最终的损失函数如下所示。
L = ∑ m = 0 M + 1 λ m L l a y e r ( S m , T g ( m ) ) L = \sum_{m=0}^{M+1}\lambda_mL_{layer}(S_m,T_{g(m)}) L=m=0∑M+1λmLlayer(Sm,Tg(m))
在上面的公式中, L l a y e r L_{layer} Llayer表示第m层的损失函数, λ m \lambda_m λm为一个超参数,它用来控制第m层的权重。我们通过最小化上面的损失函数来训练学生BERT模型(TinyBERT模型)。