一、项目实践步骤

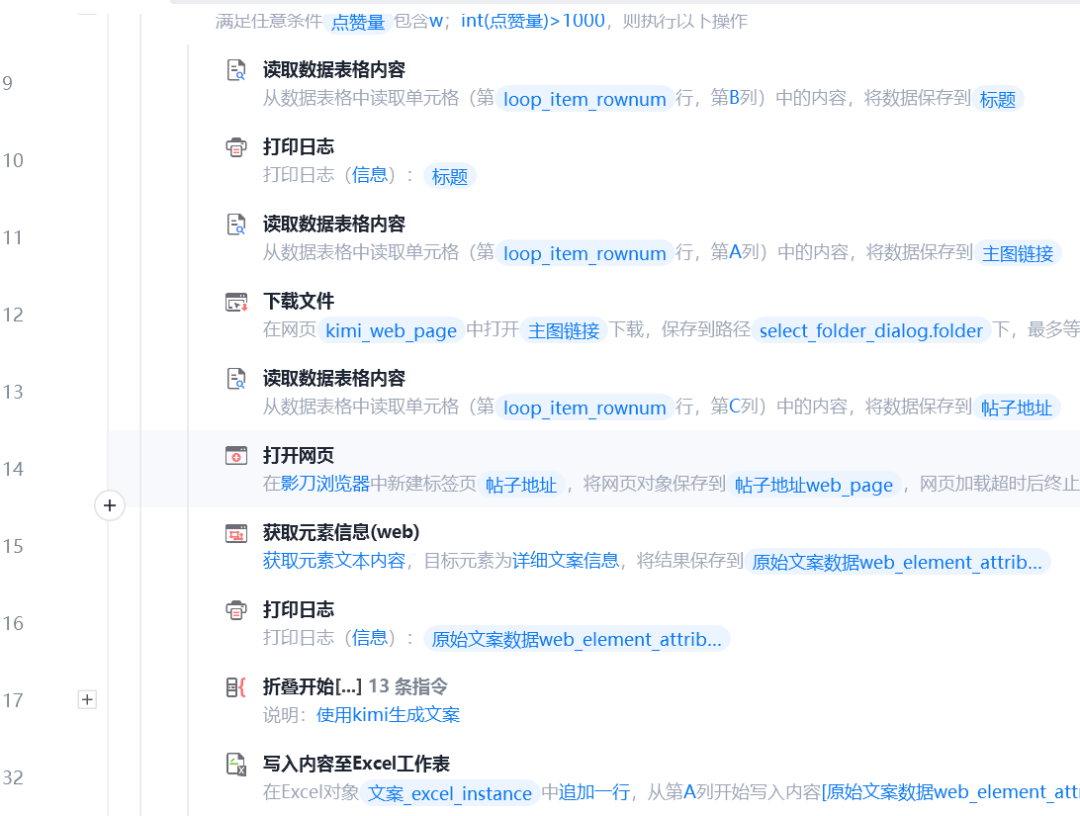
图 1 构建模型和完成训练的程序图
二、实验背景
2.1数据集介绍
我们使用安全帽检测数据集。安全帽检测数据集包含数据集共包括40000张训练图像和1000张测试图像,每张训练图像对应 xml标注文件:


图 2 安全帽 数据集图像示例
业务难点:
- 精度要求高 由于涉及安全问题,需要精度非常高才能保证对施工场所人员的安全督导。需要专门针对此目标的检测算法进行优化。
- 精度要求高 监控受拍摄角度、光线变化、天气影响,有时会存在遮挡,导致安全帽显示不全,对检测具有一定的干扰。
- 小目标检测 由于实际使用过程中,人员离镜头较远,因此需要模型对小目标的检测有较低的漏检率。
2.2实验环境
本次实验,采用PaddlePaddle环境训练模型,利用PaddlePaddle的可视化插件VisualDL进行训练模型过程的可视化。
另附代码见附录和.ipynb 文件。
2.3实验设置
本次实验,采用YOLOV3作为安全帽检测的基线模型,以COCO指标作为评估指标。
2.3.1 YOLOV3
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并预测出物体的类别和位置坐标。
与R-CNN系列算法不同,YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,不需要分成两阶段来完成检测任务。另外,YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
Joseph Redmon等人在2015年提出YOLO(You Only Look Once,YOLO)算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。
YOLOv3模型设计思想
YOLOv3算法的基本思想可以分成两部分:
按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
YOLOv3算法训练过程的流程图如 图3 所示:

图3:YOLOv3算法训练流程图
图3 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的1/32
图3 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
三、项目流程
 |
3.1 准备数据
数据切分 将训练集和验证集按照8.5:1.5的比例划分。 PaddleX中提供了简单易用的API,方便用户直接使用进行数据划分。
!paddlex --split_dataset --format voc --dataset_dir /home/aistudio/work/dataset --val_value 0.15使用pdx.dataset加载和处理数据集
train_dataset = pdx.datasets.VOCDetection(data_dir='/home/aistudio/work/dataset',file_list='/home/aistudio/work/dataset/train_list.txt',label_list='/home/aistudio/work/dataset/labels.txt',transforms=train_transforms,shuffle=True)数据集处理
数据增强选择
| 训练预处理1(a1) | 验证预处理 |
| MixupImage(mixup_epoch=-1) | Resize(target_size=480, interp='CUBIC') |
| RandomDistort() | Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) |
| RandomExpand(im_padding_value=[123.675, 116.28, 103.53]) | |
| RandomCrop() | |
| RandomHorizontalFlip() | |
| BatchRandomResize(target_sizes=[320, 352, 384, 416, 448, 480, 512, 544, 576, 608],interp='RANDOM') | |
| Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) |
train_transforms = T.Compose([T.MixupImage(mixup_epoch=-1), T.RandomDistort(),T.RandomExpand(im_padding_value=[123.675, 116.28, 103.53]), T.RandomCrop(),T.RandomHorizontalFlip(), T.BatchRandomResize(target_sizes=[384, 416, 448, 480, 512, 544, 576, 608, 640, 672],interp='RANDOM'), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])3.2 搭建网络
本次实验基于 PaddlePaddle搭建了 yolov3,其详细代码如下:
Yolov3的anchor
cluster_yolo_anchor__all__ = ['YOLOAnchorCluster']class BaseAnchorCluster(object):def __init__(self, num_anchors, cache, cache_path):"""Base Anchor ClusterArgs:num_anchors (int): number of clusterscache (bool): whether using cachecache_path (str): cache directory path"""super(BaseAnchorCluster, self).__init__()self.num_anchors = num_anchorsself.cache_path = cache_pathself.cache = cachedef print_result(self, centers):raise NotImplementedError('%s.print_result is not available' %self.__class__.__name__)def get_whs(self):whs_cache_path = os.path.join(self.cache_path, 'whs.npy')shapes_cache_path = os.path.join(self.cache_path, 'shapes.npy')if self.cache and os.path.exists(whs_cache_path) and os.path.exists(shapes_cache_path):self.whs = np.load(whs_cache_path)self.shapes = np.load(shapes_cache_path)return self.whs, self.shapeswhs = np.zeros((0, 2))shapes = np.zeros((0, 2))samples = copy.deepcopy(self.dataset.file_list)for sample in tqdm(samples):im_h, im_w = sample['image_shape']bbox = sample['gt_bbox']wh = bbox[:, 2:4] - bbox[:, 0:2]wh = wh / np.array([[im_w, im_h]])shape = np.ones_like(wh) * np.array([[im_w, im_h]])whs = np.vstack((whs, wh))shapes = np.vstack((shapes, shape))if self.cache:os.makedirs(self.cache_path, exist_ok=True)np.save(whs_cache_path, whs)np.save(shapes_cache_path, shapes)self.whs = whsself.shapes = shapesreturn self.whs, self.shapesdef calc_anchors(self):raise NotImplementedError('%s.calc_anchors is not available' %self.__class__.__name__)def __call__(self):self.get_whs()centers = self.calc_anchors()return centersclass YOLOAnchorCluster(BaseAnchorCluster):def __init__(self,num_anchors,dataset,image_size,cache=True,cache_path=None,iters=300,gen_iters=1000,thresh=0.25):"""YOLOv5 Anchor ClusterReference:https://github.com/ultralytics/yolov5/blob/master/utils/autoanchor.pyArgs:num_anchors (int): number of clustersdataset (DataSet): DataSet instance, VOC or COCOimage_size (list or int): [h, w], being an int means image height and image width are the same.cache (bool): whether using cache。 Defaults to True.cache_path (str or None, optional): cache directory path. If None, use `data_dir` of dataset. Defaults to None.iters (int, optional): iters of kmeans algorithm. Defaults to 300.gen_iters (int, optional): iters of genetic algorithm. Defaults to 1000.thresh (float, optional): anchor scale threshold. Defaults to 0.25."""self.dataset = datasetif cache_path is None:cache_path = self.dataset.data_dirif isinstance(image_size, int):image_size = [image_size] * 2self.image_size = image_sizeself.iters = itersself.gen_iters = gen_itersself.thresh = threshsuper(YOLOAnchorCluster, self).__init__(num_anchors, cache, cache_path)def print_result(self, centers):whs = self.whsx, best = self.metric(whs, centers)bpr, aat = (best > self.thresh).mean(), (x > self.thresh).mean() * self.num_anchorslogging.info('thresh=%.2f: %.4f best possible recall, %.2f anchors past thr' %(self.thresh, bpr, aat))logging.info('n=%g, img_size=%s, metric_all=%.3f/%.3f-mean/best, past_thresh=%.3f-mean: '% (self.num_anchors, self.image_size, x.mean(), best.mean(),x[x > self.thresh].mean()))logging.info('%d anchor cluster result: [w, h]' % self.num_anchors)for w, h in centers:logging.info('[%d, %d]' % (w, h))def metric(self, whs, centers):r = whs[:, None] / centers[None]x = np.minimum(r, 1. / r).min(2)return x, x.max(1)def fitness(self, whs, centers):_, best = self.metric(whs, centers)return (best * (best > self.thresh)).mean()def calc_anchors(self):self.whs = self.whs * self.shapes / self.shapes.max(1, keepdims=True) * np.array([self.image_size[::-1]])wh0 = self.whsi = (wh0 < 3.0).any(1).sum()if i:logging.warning('Extremely small objects found. %d of %d ''labels are < 3 pixels in width or height' %(i, len(wh0)))wh = wh0[(wh0 >= 2.0).any(1)]logging.info('Running kmeans for %g anchors on %g points...' %(self.num_anchors, len(wh)))s = wh.std(0)centers, dist = kmeans(wh / s, self.num_anchors, iter=self.iters)centers *= sf, sh, mp, s = self.fitness(wh, centers), centers.shape, 0.9, 0.1pbar = tqdm(range(self.gen_iters),desc='Evolving anchors with Genetic Algorithm')for _ in pbar:v = np.ones(sh)while (v == 1).all():v = ((np.random.random(sh) < mp) * np.random.random() *np.random.randn(*sh) * s + 1).clip(0.3, 3.0)new_centers = (centers.copy() * v).clip(min=2.0)new_f = self.fitness(wh, new_centers)if new_f > f:f, centers = new_f, new_centers.copy()pbar.desc = 'Evolving anchors with Genetic Algorithm: fitness = %.4f' % fcenters = np.round(centers[np.argsort(centers.prod(1))]).astype(int).tolist()return centers# YOLO检测模型的预置anchor生成anchors = train_dataset.cluster_yolo_anchor(num_anchors=9, image_size=480)anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]# 初始化模型,并进行训练# 可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/tree/release/2.0.0/tutorials/train#visualdl可视化训练指标num_classes = len(train_dataset.labels)model = pdx.det.YOLOv3(num_classes=num_classes,backbone='DarkNet53',anchors=anchors.tolist() if isinstance(anchors, np.ndarray) else anchors,anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],label_smooth=True,ignore_threshold=0.6)3.3 训练配置
接下来,定义训练函数,为防止过拟合,达到更好效果,使用学习率衰减策略。
初始参数如下:
| Epochs | Batch_size | warmup_start_lr | Shuffle | warmup_steps | lr_decay_epochs |
| 200 | 16 | 0.0 | True | 500 | [85, 135] |
model.train(num_epochs=200, # 训练轮次train_dataset=train_dataset, # 训练数据eval_dataset=eval_dataset, # 验证数据train_batch_size=16, # 批大小#pretrain_weights='COCO', # 预训练权重,刚开始训练的时候取消该注释,注释resume_checkpointlearning_rate=0.005 / 12, # 学习率warmup_steps=500, # 预热步数warmup_start_lr=0.0, # 预热起始学习率save_interval_epochs=5, # 每5个轮次保存一次,有验证数据时,自动评估lr_decay_epochs=[85, 135], # step学习率衰减save_dir='output/yolov3_darknet53', # 保存路径resume_checkpoint='output/yolov3_darknet53', # 断点继续训练use_vdl=True) # 其用visuadl进行可视化训练记录- num_epochs:训练轮次,模型将在训练数据上迭代多少个轮次。
- train_dataset:训练数据集对象,包含训练数据的路径、标签等信息。
- eval_dataset:验证数据集对象,包含验证数据的路径、标签等信息。
- train_batch_size:训练时每个批次的样本数量。
- learning_rate:学习率,控制模型参数更新的步长。
- warmup_steps:预热步数,模型在训练开始时将学习率逐渐增加到设定的学习率,以便更好地初始化模型权重。
- warmup_start_lr:预热起始学习率,预热步数开始时的学习率。
- save_interval_epochs:保存间隔轮次,每隔多少个轮次保存一次模型。
- lr_decay_epochs:学习率衰减轮次,指定在哪些轮次将学习率进行衰减。
- save_dir:保存路径,训练过程中模型的保存位置。
- resume_checkpoint:断点继续训练,如果之前已经训练过模型,并且保存了断点文件,可以指定断点文件的路径,以在之前训练的基础上继续训练。
- use_vdl:是否使用VisualDL进行可视化训练记录。VisualDL是一个可视化工具,用于分析和展示训练过程中的指标和结果。
综合来看,使用模型对安全帽数据集进行训练,通过VisualDL工具对训练过程进行可视化。训练过程中会保存分阶段的模型参数,并最终保存整个训练好的模型。
3.4模型优化(进阶)
精度提升 为了进一步提升模型的精度,可以通过coco_error_analysis
精度优化思路侧重在模型迭代过程中优化精度
(1) 基线模型选择
相较于二阶段检测模型,单阶段检测模型的精度略低但是速度更快。考虑到是部署到GPU端,本案例选择单阶段检测模型YOLOV3作为基线模型,其骨干网络选择DarkNet53。训练完成后,模型在验证集上的精度如下:
| 模型 | 推理时间 (ms/image) | map(Iou-0.5) | (coco)mmap | 安全帽AP(Iou-0.5) |
| baseline: YOLOv3 + DarkNet53 + cluster_yolo_anchor + img_size(480) | 50.34 | 61.6 | 39.2 | 94.58 |
(2) 基线模型效果分析与优化
使用PaddleX提供的paddlex.det.coco_error_analysis接口对模型在验证集上预测错误的原因进行分析,分析结果以图表的形式展示如下:
| allclass | head |
 |  |
| person | helmet |
 |  |
分析图表展示了7条Precision-Recall(PR)曲线,每一条曲线表示的Average Precision (AP)比它左边那条高,原因是逐步放宽了评估要求。以helmet类为例,各条PR曲线的评估要求解释如下:
- C75: 在IoU设置为0.75时的PR曲线, AP为0.681。
- C50: 在IoU设置为0.5时的PR曲线,AP为0.946。C50与C75之间的白色区域面积代表将IoU从0.75放宽至0.5带来的AP增益。
- Loc: 在IoU设置为0.1时的PR曲线,AP为0.959。Loc与C50之间的蓝色区域面积代表将IoU从0.5放宽至0.1带来的AP增益。蓝色区域面积越大,表示越多的检测框位置不够精准。
- Sim: 在Loc的基础上,如果检测框与真值框的类别不相同,但两者同属于一个亚类,则不认为该检测框是错误的,在这种评估要求下的PR曲线, AP为0.961。Sim与Loc之间的红色区域面积越大,表示子类间的混淆程度越高。VOC格式的数据集所有的类别都属于同一个亚类。
- Oth: 在Sim的基础上,如果检测框与真值框的亚类不相同,则不认为该检测框是错误的,在这种评估要求下的PR曲线,AP为0.961。Oth与Sim之间的绿色区域面积越大,表示亚类间的混淆程度越高。VOC格式的数据集中所有的类别都属于同一个亚类,故不存在亚类间的混淆。
- BG: 在Oth的基础上,背景区域上的检测框不认为是错误的,在这种评估要求下的PR曲线,AP为0.970。BG与Oth之间的紫色区域面积越大,表示背景区域被误检的数量越多。
- FN: 在BG的基础上,漏检的真值框不认为是错误的,在这种评估要求下的PR曲线,AP为1.00。FN与BG之间的橙色区域面积越大,表示漏检的真值框数量越多。
从分析图表中可以看出,head、helmet两类检测效果较好,但仍然存在漏检的情况,特别是person存在很大的漏检问题;此外,通过helmet中C75指标可以看出,其相对于C50的0.946而言有些差了,因此定位性能有待进一步提高。为进一步理解造成这些问题的原因,将验证集上的预测结果进行了可视化,然后发现数据集标注存在以下问题:
本数据集主要考虑到头部和安全帽的检测,因此在人检测时,有个图片中标注了,而有的图片中没有标注,从而导致学习失效,引发person漏检。
head与helmet大多数情况标注较好,但由于部分拍摄角度导致有的图片中的head和helmet发生重叠以及太小导致学习有困难。
(2.1)尝试替换backbone: DarkNet53 --> ResNet50_vd_dcn
考虑到漏检问题,一般是特征学习不够,无法识别出物体,因此基于这个方向尝试替换backbone.
在指标上的提升如下:
| 模型 | 推理时间 (ms/image) | map(Iou-0.5) | (coco)mmap | 安全帽AP(Iou-0.5) |
| YOLOv3 + ResNet50_vd_dcn + cluster_yolo_anchor+img_size(480) | 53.81 | 61.7 | 39.1 | 95.35 |
(2.2)通过尝试放大图片,不同的网络结构以及定位的优化策略
考虑到定位问题,通过尝试放大图片,不同的网络结构以及定位的优化策略: 利用cluster_yolo_anchor生成聚类的anchor或开启iou_aware。最终得到上线模型PPYOLOV2的精度如下:
| 模型 | 推理时间 (ms/image) | map(Iou-0.5) | (coco)mmap | 安全帽AP(Iou-0.5) |
| PPYOLOV2 + ResNet50_vd_dcn + img_size(608) | 81.52 | 61.6 | 41.3 | 95.32 |
其中helmet类误差分析如下图:
 |
从分析表中可以看出:
- C75指标效果明显改善,定位更加准确:从0.681提升到0.742。
- 其中BG到FN的差距从0.03降低到了0.02,说明漏检情况有所改善。
- 其中Loc与Sim的差距从0.002降低到了0.001,说明混淆程度也下降了。
- 其中Oth与BG的差距从0.019降低到了0.015,说明检测错误下降了。
- 本项目优化整体分析可归纳为以下几点:
- 通过选用适当更优的骨干网络可以改善漏检的情况,因此漏检方面的优化可以考虑先从骨干网络替换上开始——当然必要的数据清洗也是不可缺少的,要是数据集本身漏标,则会从根本上影响模型的学习。
- 通过放大图像,可以对一些中小目标的物体检测起到一定的优化作用。
- 通过聚类anchor以及iou_aware等操作可以提高模型的定位能力,直接体现是再高Iou上也能有更好的表现。
五、实验感想
在本次实验中,在加入了RandomHorizontalFlip、RandomDistort、RandomCrop、RandomExpand、BatchRandomResize、MixupImage这几种数据增强方法后,对模型的优化是有一定的积极作用了,在取消这些预处理后,模型性能会有一定的下降。
在训练初期都加上这些预处理方法,到后期模型超参数以及相关结构确定最优之后,再进行数据方面的再优化: 比如数据清洗,数据预处理方法筛选等。
在一开始运行结果不好不用灰心,通过数据增强,更换backbone,调整学习率等超参数方法,一步一步将实验结果提高
最终,也通过自己写的代码在测试集上达到了map61.6。总得来说,本次实验让我收获颇多。
六、 附录:python 代码
完整代码参见所交版本和.ipynb