系列文章目录
文章目录
- 系列文章目录
- 前言
前言
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。

借助 explain 执行计划来分析索引失效的具体场景。explain 使用如下,只需要在查询的 SQL 前面添加上 explain 关键字即可。
示例:
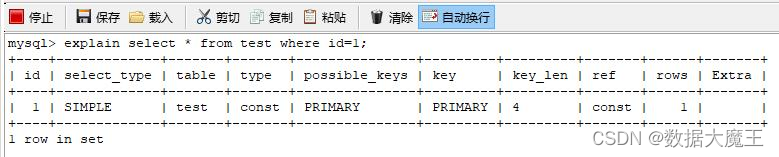
以上查询结果的列中,我们最主要观察 key 这一列,key 这一列表示实际使用的索引,如果为 NULL 则表示未使用索引,反之则使用了索引。
以上所有结果列说明如下:
id — 选择标识符,id 越大优先级越高,越先被执行;
select_type — 表示查询的类型;
table — 输出结果集的表;
partitions — 匹配的分区;
type — 表示表的连接类型;
possible_keys — 表示查询时,可能使用的索引;
key — 表示实际使用的索引;
key_len — 索引字段的长度;
ref— 列与索引的比较;
rows — 大概估算的行数;
filtered — 按表条件过滤的行百分比;
Extra — 执行情况的描述和说明。
其中最重要的就是 type 字段,type 值类型如下:
all — 扫描全表数据;
index — 遍历索引;
range — 索引范围查找;
index_subquery — 在子查询中使用 ref;
unique_subquery — 在子查询中使用 eq_ref;
ref_or_null — 对 null 进行索引的优化的 ref;
fulltext — 使用全文索引;
ref — 使用非唯一索引查找数据;
eq_ref — 在 join 查询中使用主键或唯一索引关联;<