文章目录
- 请添加图片描述 @[TOC](文章目录)
- 📝引用# 🌠引用概念**引用**不是新定义一个变量,而是给**已存在变量取了一个别名**,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。>定义:**类型&引用变量名(对象名) = 引用实体;**例如以下代码,在变量名前加一个`&`,意思是一个引用类型,`b`是`a`的别名,也就是`a`有了一个外号,但还是`a`本身:```cppint a = 70;int& b = a; //引用:b是a的别名```我们接下来看看引用后的地址是否会发生改变:例如以下例子:```cppint main(){ int a = 70; int& b = a; //引用:b是a的别名 int& c = a; //引用:c是a的别名 c = 80; cout << a << endl; cout << &a << endl; cout << &b << endl; cout << &c << endl; return 0;}```代码运行图:在这个代码中,定义了一个变量`a`为`70`,`int& b = a`; 这里`b`是`a`的引用,给`a`取了一个外号`b`,`int& c = a`; 这里`c`是`a`的引用,又给`a`取了一个外号是`c`,因此我们对`c`还是对`b`进行修改,`a`都会发生改变,这是因为**编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间**。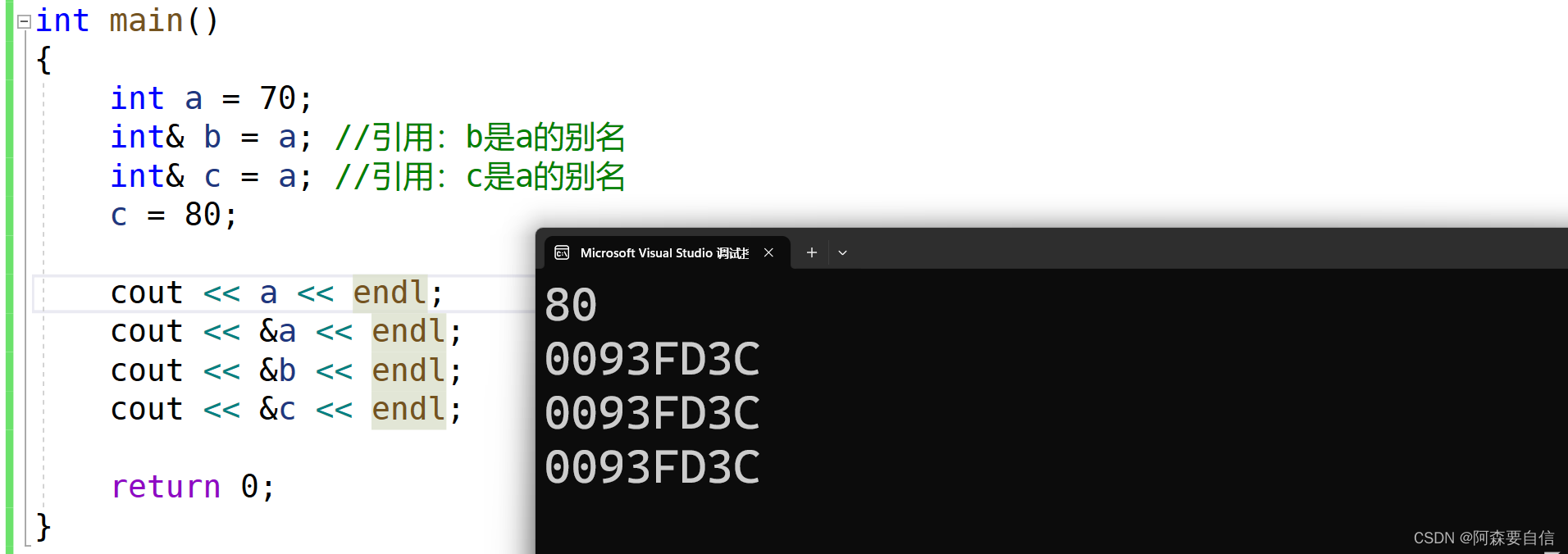>注意:**引用类型必须和引用实体是同种类型的**## 🌉引用特性1. 引用**必须在定义时初始化**:==引用必须在定义时初始化,不能在之后单独为它赋值==。```cppint a = 10; int& ra = a; // 正确,ra初始化为aint& ra; // 错误,引用必须在定义时初始化```2. 一个变量可以有多个引用```cppint a = 10;int& ref1 = a; int& ref2 = a;ref1++; // a的值变为11cout << a << endl; // 输出11ref2--; // a的值变为10cout << a << endl; // 输出10```3. 引用一旦引用一个实体,再不能引用其他实体引用本质上**就是给原变量添加一个别名,它的内存地址就是原变量的地址**。所以对引用赋值或修改,实际上就是修改原变量。而指针不同,指针可以改变指向的对象:**一级指针**可以改变指向,如p可以从指向a改为指向其他变量,**二级指针**可以改变一级指针指向的地址,如`pp`可以改变`p`指向的地址而引用更像一个`const`指针:定义后不能改变指向的对象,就像`const`指针定义后不能改变指向但可以通过这个“`const`指针”来修改原对象,就像通过`const`指针可以修改原对象```cppint a = 10;int b = 20;int& ref = a; ref = b; // 错误!引用ref已经引用a,不能再引用bcout << ref << endl; // 输出10,ref依然引用a```如图:ref引用了a,这里的值发生改变是因为b赋值给了ref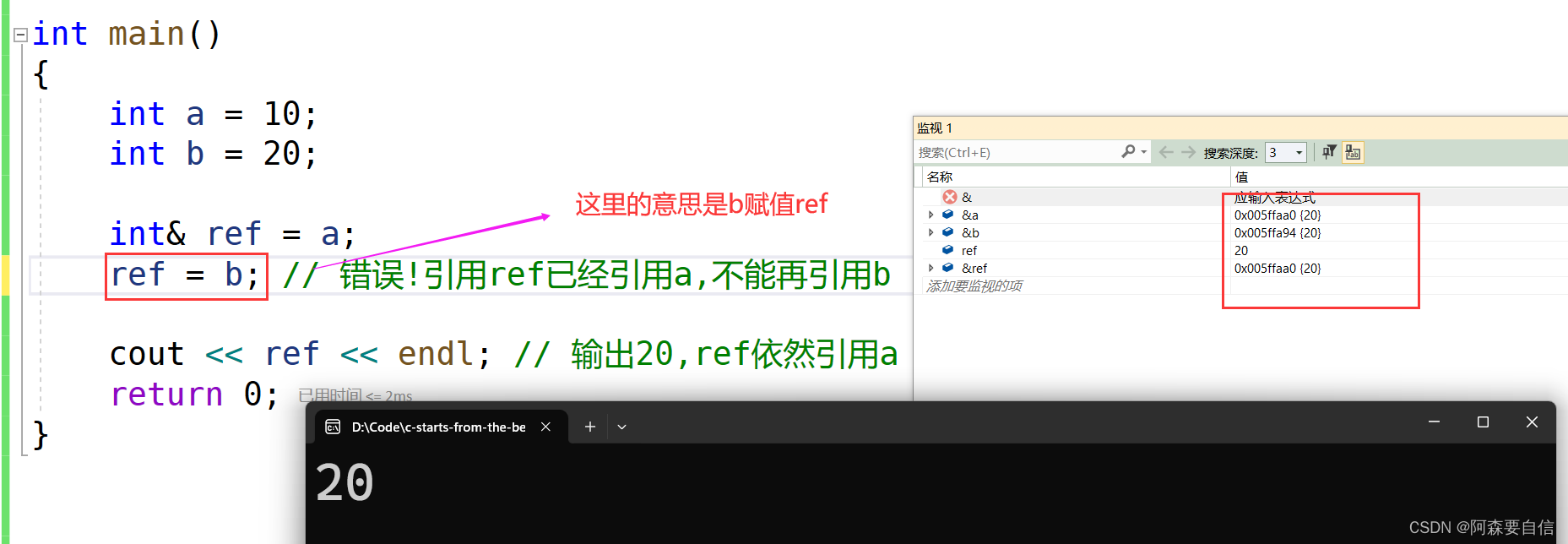# 🌠使用场景## 🌉做参数(传值与传地址)当引用用来做参数时将会对代码进行大大的优化,并且具有可读性,如:当我们看了很多遍的交换了两个数的函数:```cppvoid Swap(int* a, int* b){ int tmp = *a; *a = *b; *b = tmp;}int main(){ int ra = 88; int rb = 99; Swap(&ra, &rb); return 0;}```形参是实参的一份临时拷贝,所以如果想交换需要,传地址,不能传值。```cppvoid Swap(int& a, int& b){ int tmp = a; a = b; b = tmp;}int main(){ int ra = 88; int rb = 99; Swap(ra, rb); return 0;}````a`和`b`分别是`ra`和`rb`的别名,当你调换`a`和`b`的纸时,其实是修改了`ra`和`rb`的地址的值,这样的好处就是,当你看代码时,引用`a`和`b`给人一种感觉,就是操作`ra`和`rb`本身。这隐藏了底层是通过地址操作原变量`ra`和`rb`的实现细节。从使用者的角度看,代码读起来就像直接交换`ra`和`rb`,而不是通过**复杂的地址操作实现**。>这里使用了引用挺好的,不用担心指针的解引用,地址相关操作,但是,前面我们知道,引用一旦指向一个实体,就无法改变指向,例如,**有关链表操作**,当我们要删除一个节点,是不是要改变前面节点的指针,让他指向后面节点,而引用恰恰不能改变,因此,**引用也不是完全替代指针的**回归正题,这里还有一个小注意点:作用域的不同,因此,在Swap函数里,取别的名字都可以,任由发挥,结果都相同。```cppvoid Swap(int& x, int& x){ int tmp = x; x = y; y = tmp;}int main(){ int ra = 88; int rb = 99; Swap(ra, rb); return 0;}```## 🌉传值、传引用效率比较**以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。**```cpp#include <time.h>struct A { int a[10000]; };void TestFunc1(A a) {}void TestFunc2(A& a) {}void TestRefAndValue(){ A a; // 以值作为函数参数 size_t begin1 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc1(a); size_t end1 = clock(); // 以引用作为函数参数 size_t begin2 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc2(a); size_t end2 = clock(); // 分别计算两个函数运行结束后的时间 cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;}int main(){ TestRefAndValue(); return 0;}```**按值传递(TestFunc1):**调`用`TestFunc1(a)`时,会将`a`进行拷贝,生成一个临时对象**a_copy**。**a_copy**作为参数传递给TestFunc1`。`TestFunc1`内部操作的实际上是`a_copy`,对`a_copy`的修改不会影响实参`a`。`TestFunc1`返回时,临时对象`a_copy`会被销毁。`TestFunc1`以值方式传递结构体`A`作为参数。这会导致每次调用都会对A进行值拷贝,对于一个包含`10000`个`int`成员的大结构体,拷贝开销很大。**按引用传递(TestFunc2):**调用`TestFunc2(a)`时,不会进行值拷贝,直接传递`a`的引用。`TestFunc2`内部操作的仍然是实参`a`本身。`TestFunc2`返回时,不需要销毁任何对象。TestFunc2以引用方式传递A。这种方式下,函数内直接操作的就是实参a本身,不会有任何拷贝开销。>总结:>`TestFunc1`值传递,效率低是因为值拷贝开销大`TestFunc2`引用传递,效率高是因为避免了值拷贝,直接操作的就是实参`a`本身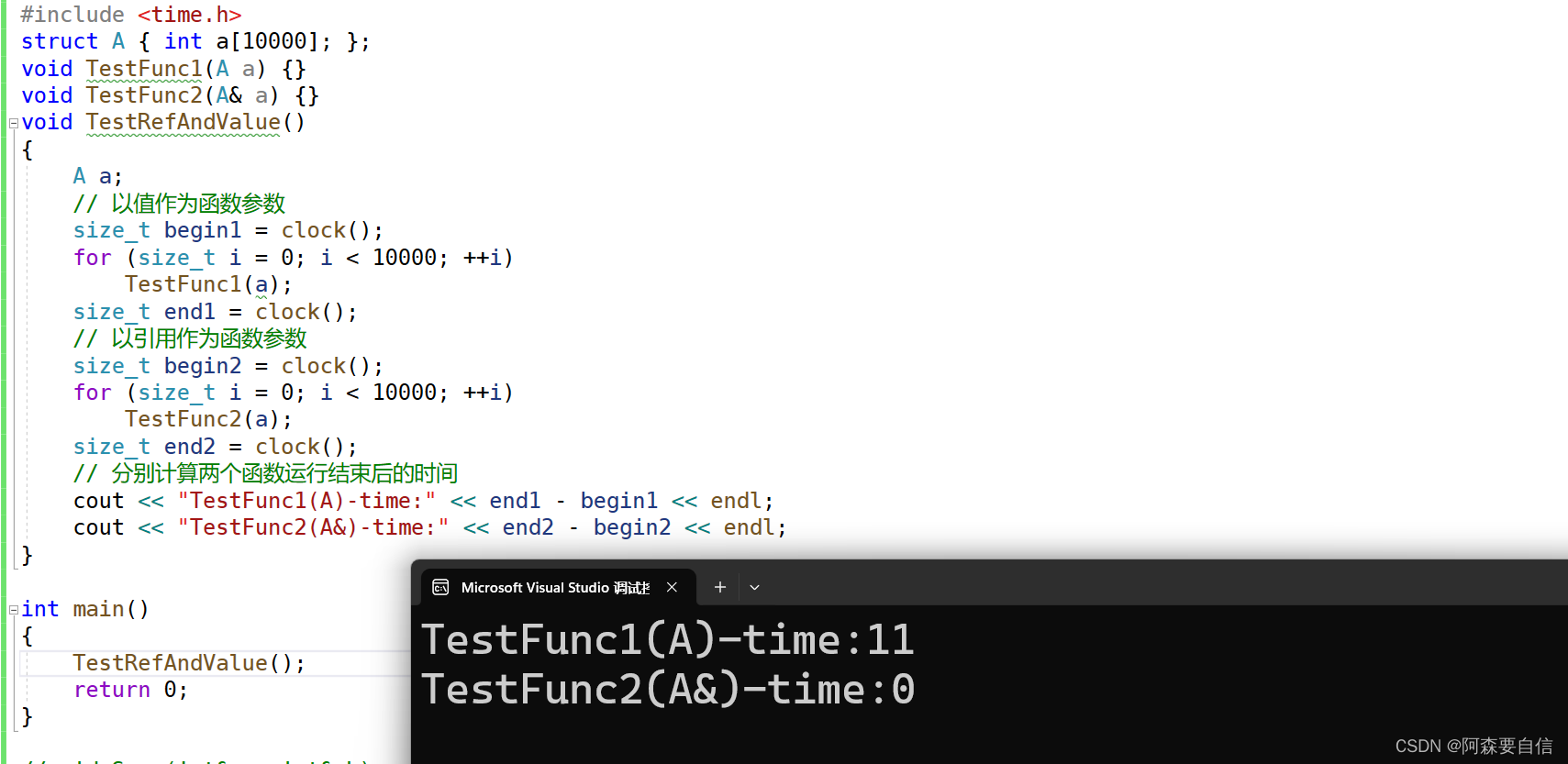>通过上述代码的比较,**发现传值和指针在作为传参以及返回值类型上效率相差很大**。# 🌠引用做返回值```cppint& Count(){static int n = 0;n++;// ...return n;}```我们先看看下面代码会输出什么结果?```cppint& Add(int a, int b){int c = a + b;return c;}int main(){int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;return 0;}```在Vs编译运行图:结果是**7**,真的是正确吗?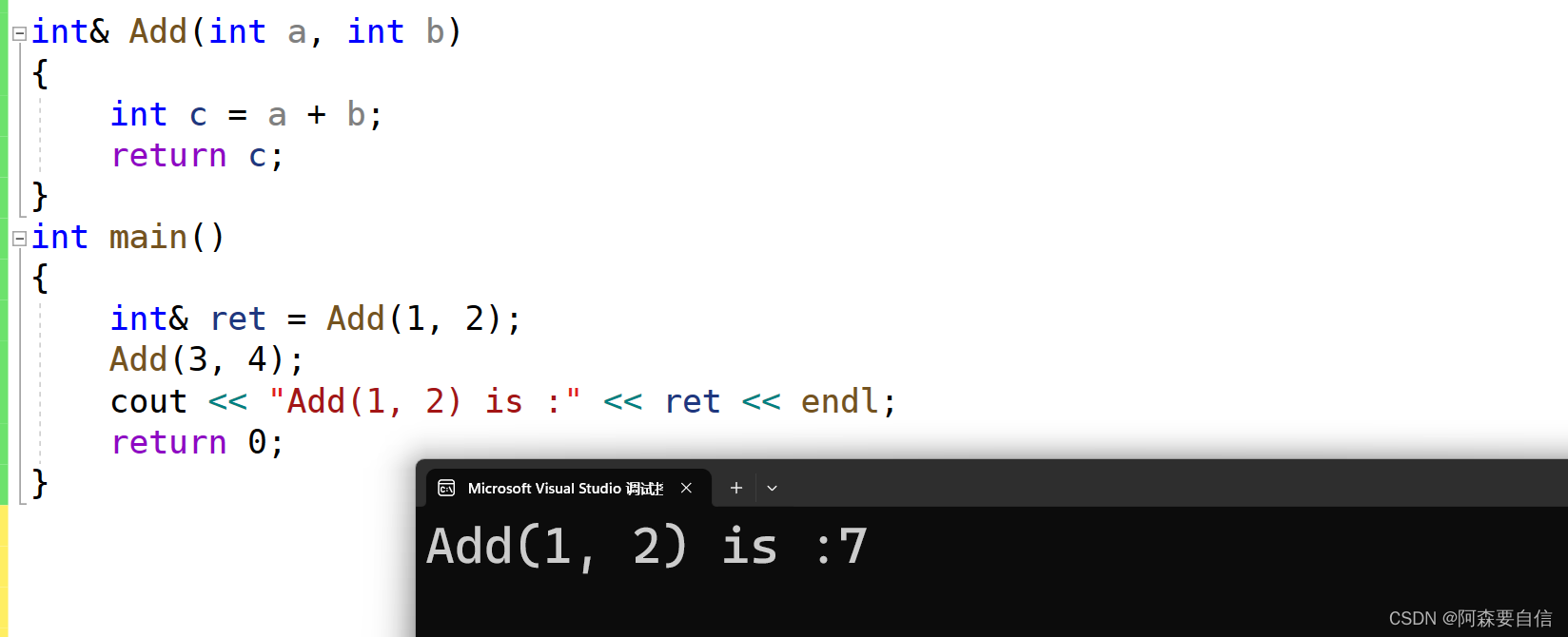>问题分析:>**如果函数返回时,返回的对象已经超出了函数作用域(即已经被销毁),那么不能返回该对象的引用,必须返回值。**>在第一个示例中:```cppint& Add(int a, int b){int c = a + b;return c;}```>这里函数返回了局部变量`c`的引用,但`c`在函数返回后就已经被销毁了,所以这是一个**未定义行为**,输出结果是**不确定**的。>而在第二个示例中:```cppint& Add(int a, int b){int c = a + b;return c;}int main(){int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;return 0;}```这里同样是返回了局部变量`c`的引用,但是在`main`函数中又调用了一次`Add`函数,这时第一次调用返回的引用`ret`已经指向了一个==不存在的对象==,所以输出结果==也是未定义==的。>函数返回引用时必须确保返回的对象在调用者作用域内仍然存在,否则就会产生未定义行为。这是`C++`中函数返回引用需要特别注意的地方。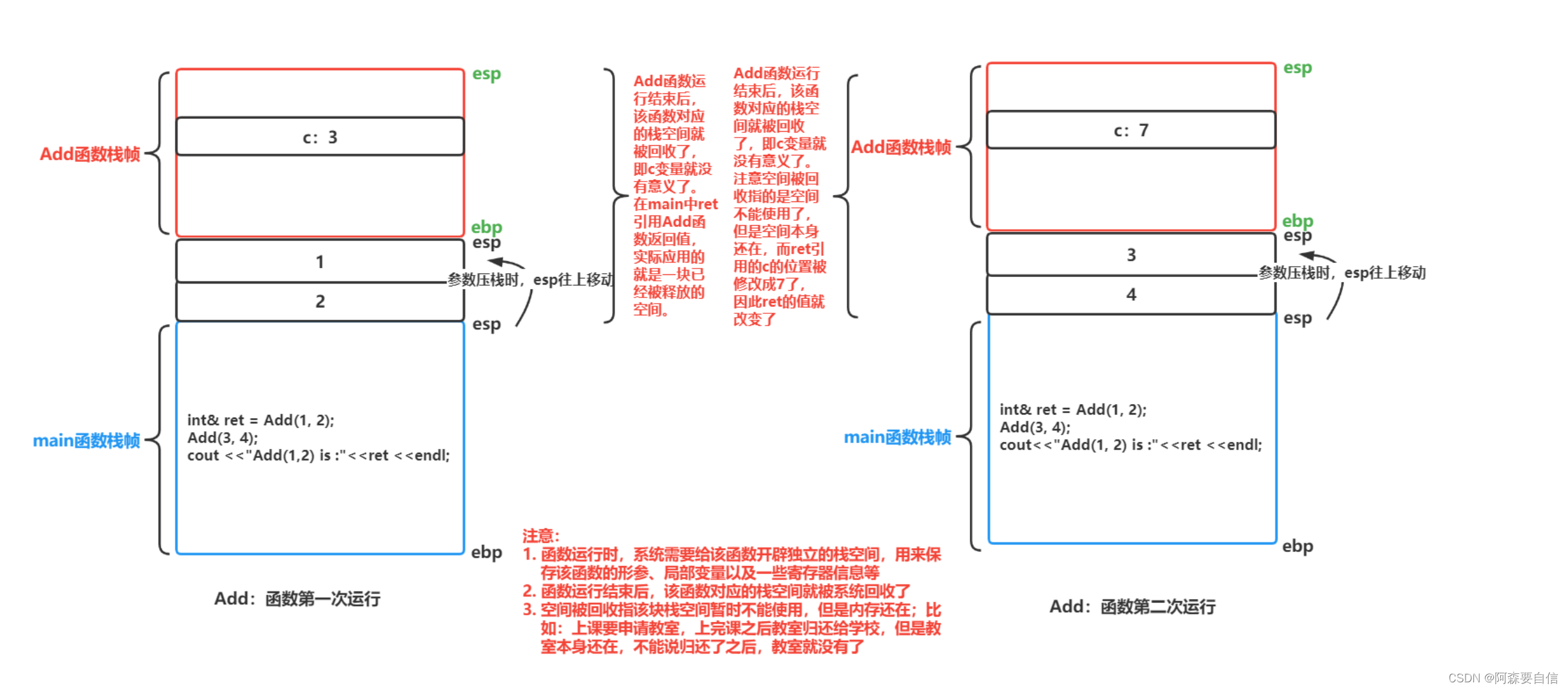答案思考:在`Visual Studio`上运行这段代码,输出结果是:```Add(1, 2) is :7```这个结果确实是**未定义**行为,但在某些情况下可能会输出`7`。之所以会出现这种情况,是因为**Visual Studio的编译器在处理这种未定义行为时可能会做一些特殊的优化或处理**,导致在某些环境下能够得到一个**看似合理**的结果。但这种行为是**不可靠**的,因为它依赖于具体的编译器实现细节。在不同的编译器或环境下,输出可能会完全不同。**正确的做法**:是要么返回值,要么返回一个在调用者作用域内仍然存在的对象的引用。这样可以确保代码的行为是可预测和可移植的。## 🌉引用和指针的区别1. **语法概念**:- **引用**是变量的别名,没有独立的存储空间,而是和其引用的实体共用同一块内存空间。- **指针**是一个独立的变量,存储了另一个变量的内存地址。2. **声明语法**:- 引用使用`&`符号声明,如`int& ref = x;`- 指针使用`*`符号声明,如`int* ptr = &x;`3. **操作方式**:- 引用直接访问和操作其引用的实体,如`ref = 10;`- 指针需要先解引用(`*`)才能访问其指向的实体,如`*ptr = 10;`4. **Null值**:- 引用不能为空(Null),必须在声明时初始化为一个有效的实体。- 指针可以为空(Null),指向空地址`0x0`。让我们看看例子来说明引用和指针的区别:假设我们有一个整型变量`x`,值为10。**使用引用:**```cppint x = 10;int& ref = x; // 声明引用ref,它是x的别名ref = 20; // 通过ref修改x的值cout << "x = " << x << endl; // 输出 x = 20````ref`是`x`的引用,它们共享同一块内存空间。通过`ref`修改值,实际上是在修改`x`的值。 输出`x`的值为20,因为`x`的值已经被修改了。**使用指针:**```cppint x = 10;int* ptr = &x; // 声明指针ptr,存储x的地址*ptr = 20; // 通过ptr解引用并修改x的值cout << "x = " << x << endl; // 输出 x = 20````ptr`是一个指向`x`的指针,存储了`x`的内存地址。通过`*ptr`解引用并修改值,实际上是在修改`x`的值。输出`x`的值为20,因为`x`的值已经被修改了。>在**底层实现**上实际是有空间的,因为**引用是按照指针方式来实现的**。```cppint main(){ int a = 10; int& ra = a; ra = 20; int* pa = &a; *pa = 20; return 0;}```我们来看下引用和指针的汇编代码对比得出:==在汇编中**引用**的底层逻辑还是**指针**,经过编译转换成汇编,还是进行指针的操作==引用和指针的不同点:1. **引用概念上定义一个变量的别名,指针存储一个变量地址**。2. **引用在定义时必须初始化,指针没有要求**3. **引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体**4. **没有NULL引用,但有NULL指针**5. 在`sizeof`中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(`32`位平台下占`4`个字节)6. **引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小**7. **有多级指针,但是没有多级引用**8. **访问实体方式不同,指针需要显式解引用,引用编译器自己处理**9. **引用比指针使用起来相对更安全**# 🌠常引用从上述代码中,我们可以得出以下关于常引用的结论:1. **常量引用**:```cppconst int a = 10;//int& ra = a; // 该语句编译时会出错,a为常量const int& ra = a;```对于常量对象`a`,我们可以使用常引用`const int& ra = a;`来引用它。这样做可以避免对常量进行修改,直接使用非常引用`int& ra = a;`会在编译时报错,因为不允许对常量进行非常引用。2. **字面量常引用**:```cpp// int& b = 10; // 该语句编译时会出错,b为常量const int& b = 10;```我们可以使用常引用`const int& b = 10;`来引用字面量常量。这样做可以避免创建临时变量, 直接使用非常引用`int& b = 10;`会在编译时报错,因为字面量不能被非常引用。3. **类型不匹配的常引用**:```cppdouble d = 12.34;//int& rd = d; // 该语句编译时会出错,类型不同const int& rd = d;```根据类型不同的变量,如`double d = 12.34;`,我们可以使用常引用`const int& rd = d;`来引用它,直接使用非常引用`int& rd = d;`会在编译时报错,因为类型不匹配。---# 🚩总结
文章目录
- 请添加图片描述 @[TOC](文章目录)
- 📝引用# 🌠引用概念**引用**不是新定义一个变量,而是给**已存在变量取了一个别名**,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。>定义:**类型&引用变量名(对象名) = 引用实体;**例如以下代码,在变量名前加一个`&`,意思是一个引用类型,`b`是`a`的别名,也就是`a`有了一个外号,但还是`a`本身:```cppint a = 70;int& b = a; //引用:b是a的别名```我们接下来看看引用后的地址是否会发生改变:例如以下例子:```cppint main(){ int a = 70; int& b = a; //引用:b是a的别名 int& c = a; //引用:c是a的别名 c = 80; cout << a << endl; cout << &a << endl; cout << &b << endl; cout << &c << endl; return 0;}```代码运行图:在这个代码中,定义了一个变量`a`为`70`,`int& b = a`; 这里`b`是`a`的引用,给`a`取了一个外号`b`,`int& c = a`; 这里`c`是`a`的引用,又给`a`取了一个外号是`c`,因此我们对`c`还是对`b`进行修改,`a`都会发生改变,这是因为**编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间**。>注意:**引用类型必须和引用实体是同种类型的**## 🌉引用特性1. 引用**必须在定义时初始化**:==引用必须在定义时初始化,不能在之后单独为它赋值==。```cppint a = 10; int& ra = a; // 正确,ra初始化为aint& ra; // 错误,引用必须在定义时初始化```2. 一个变量可以有多个引用```cppint a = 10;int& ref1 = a; int& ref2 = a;ref1++; // a的值变为11cout << a << endl; // 输出11ref2--; // a的值变为10cout << a << endl; // 输出10```3. 引用一旦引用一个实体,再不能引用其他实体引用本质上**就是给原变量添加一个别名,它的内存地址就是原变量的地址**。所以对引用赋值或修改,实际上就是修改原变量。而指针不同,指针可以改变指向的对象:**一级指针**可以改变指向,如p可以从指向a改为指向其他变量,**二级指针**可以改变一级指针指向的地址,如`pp`可以改变`p`指向的地址而引用更像一个`const`指针:定义后不能改变指向的对象,就像`const`指针定义后不能改变指向但可以通过这个“`const`指针”来修改原对象,就像通过`const`指针可以修改原对象```cppint a = 10;int b = 20;int& ref = a; ref = b; // 错误!引用ref已经引用a,不能再引用bcout << ref << endl; // 输出10,ref依然引用a```如图:ref引用了a,这里的值发生改变是因为b赋值给了ref# 🌠使用场景## 🌉做参数(传值与传地址)当引用用来做参数时将会对代码进行大大的优化,并且具有可读性,如:当我们看了很多遍的交换了两个数的函数:```cppvoid Swap(int* a, int* b){ int tmp = *a; *a = *b; *b = tmp;}int main(){ int ra = 88; int rb = 99; Swap(&ra, &rb); return 0;}```形参是实参的一份临时拷贝,所以如果想交换需要,传地址,不能传值。```cppvoid Swap(int& a, int& b){ int tmp = a; a = b; b = tmp;}int main(){ int ra = 88; int rb = 99; Swap(ra, rb); return 0;}````a`和`b`分别是`ra`和`rb`的别名,当你调换`a`和`b`的纸时,其实是修改了`ra`和`rb`的地址的值,这样的好处就是,当你看代码时,引用`a`和`b`给人一种感觉,就是操作`ra`和`rb`本身。这隐藏了底层是通过地址操作原变量`ra`和`rb`的实现细节。从使用者的角度看,代码读起来就像直接交换`ra`和`rb`,而不是通过**复杂的地址操作实现**。>这里使用了引用挺好的,不用担心指针的解引用,地址相关操作,但是,前面我们知道,引用一旦指向一个实体,就无法改变指向,例如,**有关链表操作**,当我们要删除一个节点,是不是要改变前面节点的指针,让他指向后面节点,而引用恰恰不能改变,因此,**引用也不是完全替代指针的**回归正题,这里还有一个小注意点:作用域的不同,因此,在Swap函数里,取别的名字都可以,任由发挥,结果都相同。```cppvoid Swap(int& x, int& x){ int tmp = x; x = y; y = tmp;}int main(){ int ra = 88; int rb = 99; Swap(ra, rb); return 0;}```## 🌉传值、传引用效率比较**以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。**```cpp#include <time.h>struct A { int a[10000]; };void TestFunc1(A a) {}void TestFunc2(A& a) {}void TestRefAndValue(){ A a; // 以值作为函数参数 size_t begin1 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc1(a); size_t end1 = clock(); // 以引用作为函数参数 size_t begin2 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc2(a); size_t end2 = clock(); // 分别计算两个函数运行结束后的时间 cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;}int main(){ TestRefAndValue(); return 0;}```**按值传递(TestFunc1):**调`用`TestFunc1(a)`时,会将`a`进行拷贝,生成一个临时对象**a_copy**。**a_copy**作为参数传递给TestFunc1`。`TestFunc1`内部操作的实际上是`a_copy`,对`a_copy`的修改不会影响实参`a`。`TestFunc1`返回时,临时对象`a_copy`会被销毁。`TestFunc1`以值方式传递结构体`A`作为参数。这会导致每次调用都会对A进行值拷贝,对于一个包含`10000`个`int`成员的大结构体,拷贝开销很大。**按引用传递(TestFunc2):**调用`TestFunc2(a)`时,不会进行值拷贝,直接传递`a`的引用。`TestFunc2`内部操作的仍然是实参`a`本身。`TestFunc2`返回时,不需要销毁任何对象。TestFunc2以引用方式传递A。这种方式下,函数内直接操作的就是实参a本身,不会有任何拷贝开销。>总结:>`TestFunc1`值传递,效率低是因为值拷贝开销大`TestFunc2`引用传递,效率高是因为避免了值拷贝,直接操作的就是实参`a`本身>通过上述代码的比较,**发现传值和指针在作为传参以及返回值类型上效率相差很大**。# 🌠引用做返回值```cppint& Count(){static int n = 0;n++;// ...return n;}```我们先看看下面代码会输出什么结果?```cppint& Add(int a, int b){int c = a + b;return c;}int main(){int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;return 0;}```在Vs编译运行图:结果是**7**,真的是正确吗?>问题分析:>**如果函数返回时,返回的对象已经超出了函数作用域(即已经被销毁),那么不能返回该对象的引用,必须返回值。**>在第一个示例中:```cppint& Add(int a, int b){int c = a + b;return c;}```>这里函数返回了局部变量`c`的引用,但`c`在函数返回后就已经被销毁了,所以这是一个**未定义行为**,输出结果是**不确定**的。>而在第二个示例中:```cppint& Add(int a, int b){int c = a + b;return c;}int main(){int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;return 0;}```这里同样是返回了局部变量`c`的引用,但是在`main`函数中又调用了一次`Add`函数,这时第一次调用返回的引用`ret`已经指向了一个==不存在的对象==,所以输出结果==也是未定义==的。>函数返回引用时必须确保返回的对象在调用者作用域内仍然存在,否则就会产生未定义行为。这是`C++`中函数返回引用需要特别注意的地方。答案思考:在`Visual Studio`上运行这段代码,输出结果是:```Add(1, 2) is :7```这个结果确实是**未定义**行为,但在某些情况下可能会输出`7`。之所以会出现这种情况,是因为**Visual Studio的编译器在处理这种未定义行为时可能会做一些特殊的优化或处理**,导致在某些环境下能够得到一个**看似合理**的结果。但这种行为是**不可靠**的,因为它依赖于具体的编译器实现细节。在不同的编译器或环境下,输出可能会完全不同。**正确的做法**:是要么返回值,要么返回一个在调用者作用域内仍然存在的对象的引用。这样可以确保代码的行为是可预测和可移植的。## 🌉引用和指针的区别1. **语法概念**:- **引用**是变量的别名,没有独立的存储空间,而是和其引用的实体共用同一块内存空间。- **指针**是一个独立的变量,存储了另一个变量的内存地址。2. **声明语法**:- 引用使用`&`符号声明,如`int& ref = x;`- 指针使用`*`符号声明,如`int* ptr = &x;`3. **操作方式**:- 引用直接访问和操作其引用的实体,如`ref = 10;`- 指针需要先解引用(`*`)才能访问其指向的实体,如`*ptr = 10;`4. **Null值**:- 引用不能为空(Null),必须在声明时初始化为一个有效的实体。- 指针可以为空(Null),指向空地址`0x0`。让我们看看例子来说明引用和指针的区别:假设我们有一个整型变量`x`,值为10。**使用引用:**```cppint x = 10;int& ref = x; // 声明引用ref,它是x的别名ref = 20; // 通过ref修改x的值cout << "x = " << x << endl; // 输出 x = 20````ref`是`x`的引用,它们共享同一块内存空间。通过`ref`修改值,实际上是在修改`x`的值。 输出`x`的值为20,因为`x`的值已经被修改了。**使用指针:**```cppint x = 10;int* ptr = &x; // 声明指针ptr,存储x的地址*ptr = 20; // 通过ptr解引用并修改x的值cout << "x = " << x << endl; // 输出 x = 20````ptr`是一个指向`x`的指针,存储了`x`的内存地址。通过`*ptr`解引用并修改值,实际上是在修改`x`的值。输出`x`的值为20,因为`x`的值已经被修改了。>在**底层实现**上实际是有空间的,因为**引用是按照指针方式来实现的**。```cppint main(){ int a = 10; int& ra = a; ra = 20; int* pa = &a; *pa = 20; return 0;}```我们来看下引用和指针的汇编代码对比得出:==在汇编中**引用**的底层逻辑还是**指针**,经过编译转换成汇编,还是进行指针的操作==引用和指针的不同点:1. **引用概念上定义一个变量的别名,指针存储一个变量地址**。2. **引用在定义时必须初始化,指针没有要求**3. **引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体**4. **没有NULL引用,但有NULL指针**5. 在`sizeof`中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(`32`位平台下占`4`个字节)6. **引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小**7. **有多级指针,但是没有多级引用**8. **访问实体方式不同,指针需要显式解引用,引用编译器自己处理**9. **引用比指针使用起来相对更安全**# 🌠常引用从上述代码中,我们可以得出以下关于常引用的结论:1. **常量引用**:```cppconst int a = 10;//int& ra = a; // 该语句编译时会出错,a为常量const int& ra = a;```对于常量对象`a`,我们可以使用常引用`const int& ra = a;`来引用它。这样做可以避免对常量进行修改,直接使用非常引用`int& ra = a;`会在编译时报错,因为不允许对常量进行非常引用。2. **字面量常引用**:```cpp// int& b = 10; // 该语句编译时会出错,b为常量const int& b = 10;```我们可以使用常引用`const int& b = 10;`来引用字面量常量。这样做可以避免创建临时变量, 直接使用非常引用`int& b = 10;`会在编译时报错,因为字面量不能被非常引用。3. **类型不匹配的常引用**:```cppdouble d = 12.34;//int& rd = d; // 该语句编译时会出错,类型不同const int& rd = d;```根据类型不同的变量,如`double d = 12.34;`,我们可以使用常引用`const int& rd = d;`来引用它,直接使用非常引用`int& rd = d;`会在编译时报错,因为类型不匹配。---# 🚩总结
 >注意:引用类型必须和引用实体是同种类型的## 🌉引用特性1. 引用必须在定义时初始化:引用必须在定义时初始化,不能在之后单独为它赋值。
>注意:引用类型必须和引用实体是同种类型的## 🌉引用特性1. 引用必须在定义时初始化:引用必须在定义时初始化,不能在之后单独为它赋值。 # 🌠使用场景## 🌉做参数(传值与传地址)当引用用来做参数时将会对代码进行大大的优化,并且具有可读性,如:当我们看了很多遍的交换了两个数的函数:
# 🌠使用场景## 🌉做参数(传值与传地址)当引用用来做参数时将会对代码进行大大的优化,并且具有可读性,如:当我们看了很多遍的交换了两个数的函数: