一、前言
本篇文章将解析 QWen1.5 系列模型的微调代码,帮助您理解其中的关键技术要点。通过阅读本文,您将能够更好地掌握这些关键技术,并应用于自己的项目中。
开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)
二、术语介绍
2.1. LoRA微调
LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任务的可训练参数数量。
2.2.参数高效微调(PEFT)
仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。
三、前置条件
3.1.下载完整qwen1.5项目
方式一:直接下载
地址:
GitHub - QwenLM/Qwen1.5: Qwen1.5 is the improved version of Qwen, the large language model series developed by Qwen team, Alibaba Cloud.
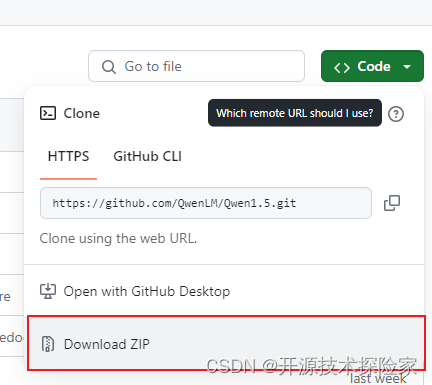
方式二:使用git克隆项目
git clone https://github.com/QwenLM/Qwen1.5.git
3.2.下载微调代码
PS:不想下载完整代码的同学,可以只下载finetune.py文件
https://github.com/QwenLM/Qwen1.5/blob/main/examples/sft/finetune.py
代码如下:
# This code is based on the revised code from fastchat based on tatsu-lab/stanford_alpaca.from dataclasses import dataclass, field
import json
import logging
import os
import pathlib
from typing import Dict, Optional, List
import torch
from torch.utils.data import Dataset
from deepspeed import zero
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import Trainer, BitsAndBytesConfig, deepspeed
from transformers.trainer_pt_utils import LabelSmoother
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from accelerate.utils import DistributedTypeIGNORE_TOKEN_ID = LabelSmoother.ignore_indexTEMPLATE = "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content']}}{% if loop.last %}{{ '<|im_end|>'}}{% else %}{{ '<|im_end|>\n' }}{% endif %}{% endfor %}"local_rank = Nonedef rank0_print(*args):if local_rank == 0:print(*args)@dataclass
class ModelArguments:model_name_or_path: Optional[str] = field(default="Qwen/Qwen-7B")@dataclass
class DataArguments:data_path: str = field(default=None, metadata={"help": "Path to the training data."})eval_data_path: str = field(default=None, metadata={"help": "Path to the evaluation data."})lazy_preprocess: bool = False@dataclass
class TrainingArguments(transformers.TrainingArguments):cache_dir: Optional[str] = field(default=None)optim: str = field(default="adamw_torch")model_max_length: int = field(default=8192,metadata={"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."},)use_lora: bool = False@dataclass
class LoraArguments:lora_r: int = 64lora_alpha: int = 16lora_dropout: float = 0.05lora_target_modules: List[str] = field(default_factory=lambda: ["q_proj","k_proj","v_proj","o_proj","up_proj","gate_proj","down_proj",])lora_weight_path: str = ""lora_bias: str = "none"q_lora: bool = Falsedef maybe_zero_3(param):if hasattr(param, "ds_id"):assert param.ds_status == ZeroParamStatus.NOT_AVAILABLEwith zero.GatheredParameters([param]):param = param.data.detach().cpu().clone()else:param = param.detach().cpu().clone()return param# Borrowed from peft.utils.get_peft_model_state_dict
def get_peft_state_maybe_zero_3(named_params, bias):if bias == "none":to_return = {k: t for k, t in named_params if "lora_" in k}elif bias == "all":to_return = {k: t for k, t in named_params if "lora_" in k or "bias" in k}elif bias == "lora_only":to_return = {}maybe_lora_bias = {}lora_bias_names = set()for k, t in named_params:if "lora_" in k:to_return[k] = tbias_name = k.split("lora_")[0] + "bias"lora_bias_names.add(bias_name)elif "bias" in k:maybe_lora_bias[k] = tfor k, t in maybe_lora_bias:if bias_name in lora_bias_names:to_return[bias_name] = telse:raise NotImplementedErrorto_return = {k: maybe_zero_3(v) for k, v in to_return.items()}return to_returndef safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str, bias="none"
):"""Collects the state dict and dump to disk."""# check if zero3 mode enabledif deepspeed.is_deepspeed_zero3_enabled():state_dict = trainer.model_wrapped._zero3_consolidated_16bit_state_dict()else:if trainer.args.use_lora:state_dict = get_peft_state_maybe_zero_3(trainer.model.named_parameters(), bias)else:state_dict = trainer.model.state_dict()if trainer.args.should_save and trainer.args.local_rank == 0:trainer._save(output_dir, state_dict=state_dict)def preprocess(messages,tokenizer: transformers.PreTrainedTokenizer,max_len: int,
) -> Dict:"""Preprocesses the data for supervised fine-tuning."""texts = []for i, msg in enumerate(messages):texts.append(tokenizer.apply_chat_template(msg,chat_template=TEMPLATE,tokenize=True,add_generation_prompt=False,padding=True,max_length=max_len,truncation=True,))input_ids = torch.tensor(texts, dtype=torch.int)target_ids = input_ids.clone()target_ids[target_ids == tokenizer.pad_token_id] = IGNORE_TOKEN_IDattention_mask = input_ids.ne(tokenizer.pad_token_id)return dict(input_ids=input_ids, target_ids=target_ids, attention_mask=attention_mask)class SupervisedDataset(Dataset):"""Dataset for supervised fine-tuning."""def __init__(self, raw_data, tokenizer: transformers.PreTrainedTokenizer, max_len: int):super(SupervisedDataset, self).__init__()rank0_print("Formatting inputs...")messages = [example["messages"] for example in raw_data]data_dict = preprocess(messages, tokenizer, max_len)self.input_ids = data_dict["input_ids"]self.target_ids = data_dict["target_ids"]self.attention_mask = data_dict["attention_mask"]def __len__(self):return len(self.input_ids)def __getitem__(self, i) -> Dict[str, torch.Tensor]:return dict(input_ids=self.input_ids[i],labels=self.target_ids[i],attention_mask=self.attention_mask[i],)class LazySupervisedDataset(Dataset):"""Dataset for supervised fine-tuning."""def __init__(self, raw_data, tokenizer: transformers.PreTrainedTokenizer, max_len: int):super(LazySupervisedDataset, self).__init__()self.tokenizer = tokenizerself.max_len = max_lenrank0_print("Formatting inputs...Skip in lazy mode")self.tokenizer = tokenizerself.raw_data = raw_dataself.cached_data_dict = {}def __len__(self):return len(self.raw_data)def __getitem__(self, i) -> Dict[str, torch.Tensor]:if i in self.cached_data_dict:return self.cached_data_dict[i]ret = preprocess([self.raw_data[i]["messages"]], self.tokenizer, self.max_len)ret = dict(input_ids=ret["input_ids"][0],labels=ret["target_ids"][0],attention_mask=ret["attention_mask"][0],)self.cached_data_dict[i] = retreturn retdef make_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer,data_args,max_len,
) -> Dict:"""Make dataset and collator for supervised fine-tuning."""dataset_cls = (LazySupervisedDataset if data_args.lazy_preprocess else SupervisedDataset)rank0_print("Loading data...")train_data = []with open(data_args.data_path, "r") as f:for line in f:train_data.append(json.loads(line))train_dataset = dataset_cls(train_data, tokenizer=tokenizer, max_len=max_len)if data_args.eval_data_path:eval_data = []with open(data_args.eval_data_path, "r") as f:for line in f:eval_data.append(json.loads(line))eval_dataset = dataset_cls(eval_data, tokenizer=tokenizer, max_len=max_len)else:eval_dataset = Nonereturn dict(train_dataset=train_dataset, eval_dataset=eval_dataset)def train():global local_rankparser = transformers.HfArgumentParser((ModelArguments, DataArguments, TrainingArguments, LoraArguments))(model_args,data_args,training_args,lora_args,) = parser.parse_args_into_dataclasses()# This serves for single-gpu qlora.if (getattr(training_args, "deepspeed", None)and int(os.environ.get("WORLD_SIZE", 1)) == 1):training_args.distributed_state.distributed_type = DistributedType.DEEPSPEEDlocal_rank = training_args.local_rankdevice_map = Noneworld_size = int(os.environ.get("WORLD_SIZE", 1))ddp = world_size != 1if lora_args.q_lora:device_map = {"": int(os.environ.get("LOCAL_RANK") or 0)} if ddp else "auto"if len(training_args.fsdp) > 0 or deepspeed.is_deepspeed_zero3_enabled():logging.warning("FSDP or ZeRO3 is incompatible with QLoRA.")model_load_kwargs = {"low_cpu_mem_usage": not deepspeed.is_deepspeed_zero3_enabled(),}compute_dtype = (torch.float16if training_args.fp16else (torch.bfloat16 if training_args.bf16 else torch.float32))# Load model and tokenizerconfig = transformers.AutoConfig.from_pretrained(model_args.model_name_or_path,cache_dir=training_args.cache_dir,)config.use_cache = Falsemodel = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path,config=config,cache_dir=training_args.cache_dir,device_map=device_map,quantization_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=compute_dtype,)if training_args.use_lora and lora_args.q_loraelse None,**model_load_kwargs,)tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path,cache_dir=training_args.cache_dir,model_max_length=training_args.model_max_length,padding_side="right",use_fast=False,)if training_args.use_lora:lora_config = LoraConfig(r=lora_args.lora_r,lora_alpha=lora_args.lora_alpha,target_modules=lora_args.lora_target_modules,lora_dropout=lora_args.lora_dropout,bias=lora_args.lora_bias,task_type="CAUSAL_LM",)if lora_args.q_lora:model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=training_args.gradient_checkpointing)model = get_peft_model(model, lora_config)# Print peft trainable paramsmodel.print_trainable_parameters()if training_args.gradient_checkpointing:model.enable_input_require_grads()# Load datadata_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args, max_len=training_args.model_max_length)# Start trainertrainer = Trainer(model=model, tokenizer=tokenizer, args=training_args, **data_module)# `not training_args.use_lora` is a temporary workaround for the issue that there are problems with# loading the checkpoint when using LoRA with DeepSpeed.# Check this issue https://github.com/huggingface/peft/issues/746 for more information.if (list(pathlib.Path(training_args.output_dir).glob("checkpoint-*"))and not training_args.use_lora):trainer.train(resume_from_checkpoint=True)else:trainer.train()trainer.save_state()safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir, bias=lora_args.lora_bias)if __name__ == "__main__":train()四、技术要点
4.1.微调训练的一般流程
1.数据准备
2.加载模型
3.数据预处理
4.LoRA 权重配置
5.训练超参数配置
6.微调模型
7.保存LoRA权重
4.2. finetune.py代码执行流程
4.2.1.数据准备
[{"type": "chatml","messages": [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "您是谁"},{"role": "assistant","content": "我是人见人爱,车见车载的叮当猫,我非常乐意解决您的问题。"}],"source": "unknown"
},
{"type": "chatml","messages": [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "您身份是啥"},{"role": "assistant","content": "我是人见人爱,车见车载的叮当猫。"}],"source": "unknown"
},
{"type": "chatml","messages": [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "你的名字是什么"},{"role": "assistant","content": "我是叮当猫。"}],"source": "unknown"
}]
4.2.2.解析命令行参数

核心技术点一:@dataclass
@dataclass 装饰器可以自动为类添加一些特定的方法和功能,从而减少了编写重复代码的工作量。以下是 @dataclass 装饰器的作用:
- 自动生成特殊方法:@dataclass 装饰器会自动为类生成 __init__、__repr__、__eq__ 等特殊方法的实现。这意味着你不再需要手动编写这些方法,从而简化了代码。
- 字段声明:通过在类的属性上添加类型注解,@dataclass 装饰器会将这些属性自动转换为实例变量,并生成相应的特殊方法的实现。这样,你可以方便地定义类的字段,并在实例化对象时自动初始化这些字段。
- 默认值:@dataclass 装饰器允许你为字段提供默认值,这样在创建对象时,如果没有为字段指定值,则会使用默认值。
- 可变性:@dataclass 装饰器的默认行为是生成可变的数据类,这意味着你可以修改实例的属性。如果你希望创建不可变的数据类,可以在类上使用 frozen=True 参数。
示例代码:
from dataclasses import dataclass@dataclass
class Person:name: strage: intcountry: str = "Unknown"# 创建一个 Person 对象
person = Person("Alice", 25, "USA")# 打印对象
print(person) # 输出: Person(name='Alice', age=25, country='USA')# 比较对象
other_person = Person("Alice", 25, "USA")
print(person == other_person) # 输出: True核心技术点二:HfArgumentParser
用于解析命令行参数并生成配置对象(config object)。它是基于 Python 的 argparse 模块进行构建的,并提供了一些额外的功能,以便更方便地处理与模型训练和推理相关的参数。
使用 HfArgumentParser 可以实现以下功能:
- 解析命令行参数:HfArgumentParser 可以解析命令行参数,并将其转换为配置对象。通过预定义参数列表和类型注解,它可以自动处理参数的解析和类型转换。
- 自动生成帮助信息:根据预定义的参数列表,HfArgumentParser 可以自动生成参数的帮助信息。这使得用户可以很容易地了解可用的参数选项及其用途。
- 集成默认配置:HfArgumentParser 可以与默认配置对象集成,使得用户只需指定感兴趣的参数,而不必重复定义所有参数。它会将默认配置与用户提供的参数合并,生成最终的配置对象。
- 配置对象验证:HfArgumentParser 可以对生成的配置对象进行验证,确保它们满足预定义的条件。这有助于避免配置错误和潜在的问题。
示例代码:
from dataclasses import dataclass, field
from transformers import HfArgumentParser@dataclass()
class MyConfig:ip: str = field(default=None, metadata={"help": "Listening IP."})port: int = field(default=None, metadata={"help": "Listening Port."})if __name__ == '__main__':parser = HfArgumentParser(MyConfig)config = parser.parse_args_into_dataclasses()[0]print(config.ip)print(config.port)调用结果:

4.2.3.加载模型和分词器

4.2.3.LoRA 权重配置


核心技术点一:get_peft_model
使用get_peft_model函数和给定的配置来获取一个PEFT模型
LoraConfig参数说明:
lora_r:LoRA的秩,影响LoRA矩阵的大小
lora_alpha:LoRA适应的比例因子
target_modules: #指定将LoRA应用到的模型模块
lora_dropout:在LoRA模块中使用的dropout率
bias:设置bias的使用方式
task_type: # 任务类型,这里设置为因果(自回归)语言模型
核心技术点二:print_trainable_parameters
使用model.print_trainable_parameters()打印出模型中可训练的参数


4.2.4.加载数据

此处代码有些问题,我改成了

4.2.5.数据预处理

# 使用分词器对训练数据进行处理,即将文本进行分词并转换成对应的标识符
# 将目标标识符中的特殊标记<|endoftext|>用-100来标识
# 构建注意力掩码序列,用于指示哪些标识符需要模型的关键
4.2.6.训练超参数配置


在一开始解析命令行参数的时候,即完成了训练超参数的配置
output_dir:指定模型输出和保存的目录
num_train_epochs:训练的总轮数
gradient_accumulation_steps:梯度累积步数
per_device_train_batch_size:每个GPU设备上的训练批量大小
learning_rate:学习率
fp16:启用混合精度训练,可以提高训练速度,同时减少内存使用
logging_steps:指定日志记录的步长,用于跟踪训练进度
max_steps:最大训练步长
......
4.2.7.微调模型

4.2.8.保存Lora权重