1.神经网络
人工神经网络,也称为神经网络,是机器学习的一个子集,也是最常见的监督学习算法之一。
它模拟了人脑的神经系统对复杂信息的处理机制,允许计算机程序解决人工智能、机器学习和深度学习领域的常见问题。
神经网络的强大之处在于它们能够学习训练集中特征与标签之间的关系,完成高速分类的预测任务。
多层感知器(Multilayer Perceptron,简称MLP)是最基础、最简单的一种人工神经网络。它通常应用于监督学习问题。
2.MLP处理数据
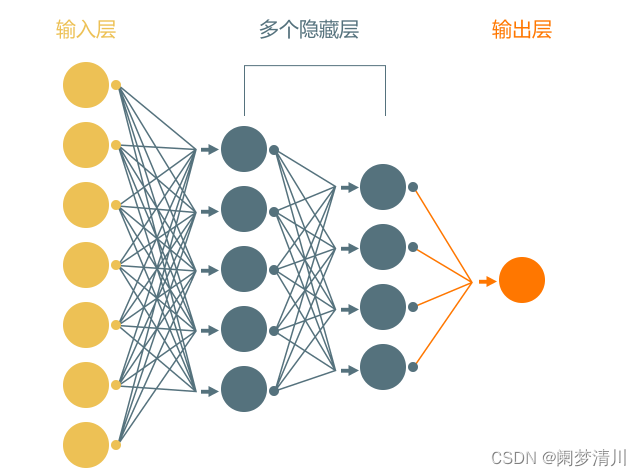
输入层就是我们的数据,隐藏层就是进行预测分析的过程。通常情况下有多个隐藏层,原始数据到达第一个隐藏层之后,第一个隐藏层把自己的预测结果返回到下一个隐藏层,第二个隐藏层根据第一个隐藏层返回的数据进行处理,逐次进行,最后到达输出层;
接下来,我们要在训练集上使用多层感知器(MLP)这个算法构造一个分类器模型;
3.搭建和训练模型
sklearn.neural_network是sklearn中的神经网络模块,我们可以使用其中的MLPClassifier类。
它为我们提供了多层感知器算法,能直接搭建和训练一个分类器模型。
(1)导入模块
从 sklearn.neural_network 模块中导入 MLPClassifier 类。
(2)创建分类器
使用MLPClassifier(),创建一个MLPClassifier对象,也就是我们的分类器模型。
我们将返回的对象存储在变量mlp中。
(3)训练分类器
接下来,就可以对mlp对象使用fit()函数,来完成模型的训练。
只需将训练集的数据,也就是文本特征train_feature和标签train_label,依次传入该函数中即可。
我们的分类器会学习传入的文本特征和标签之间的关系
4.评估模型准确率
上面的MLP算法根据我们传入进去的文本特征预测出对应的标签数据,我们让预测的数据和我们的测试集进行对比就可以了;
(1)对测试集进行预测
MLPClassifier类中提供了predict()函数,它会通过刚刚创建的多层感知器对测试集的数据进行预测。
只需对创建的分类器对象使用predict()函数,再将测试集的文本特征作为参数传入该函数中即可。
该函数会返回预测的标签数据。
(2)计算准确率
# 对测试集数据进行预测
test_pred = mlp.predict(test_feature)# 从sklearn.metrics中导入accuracy_score
from sklearn.metrics import accuracy_score# 计算预测准确率,并将结果赋值给score
score = accuracy_score(test_pred,test_label)# 输出score进行查看
print(score)5.总结
说了这么多,通俗的讲一下,我们的数据不是分为训练集特征、测试集特征、训练集标签和测试集标签这四个部分吗?我们通过上面的神经网络里面的MLP算法,把训练集的文本特征和标签进行训练,找出一定的规律,然后把测试集的文本特征传进去,根据我们得到的规律进行预测,让后我们把测试集的标签和已知的预测结果进行比较,得出准确率,就行了。








![练习 17 Web [极客大挑战 2019]PHP](https://img-blog.csdnimg.cn/direct/2ca1741a82434f4a994791762229bea2.png)
![练习14 Web [极客大挑战 2019]Upload](https://img-blog.csdnimg.cn/direct/8cbc3da0411f4b15873e2fbdc27e2c3e.png)
