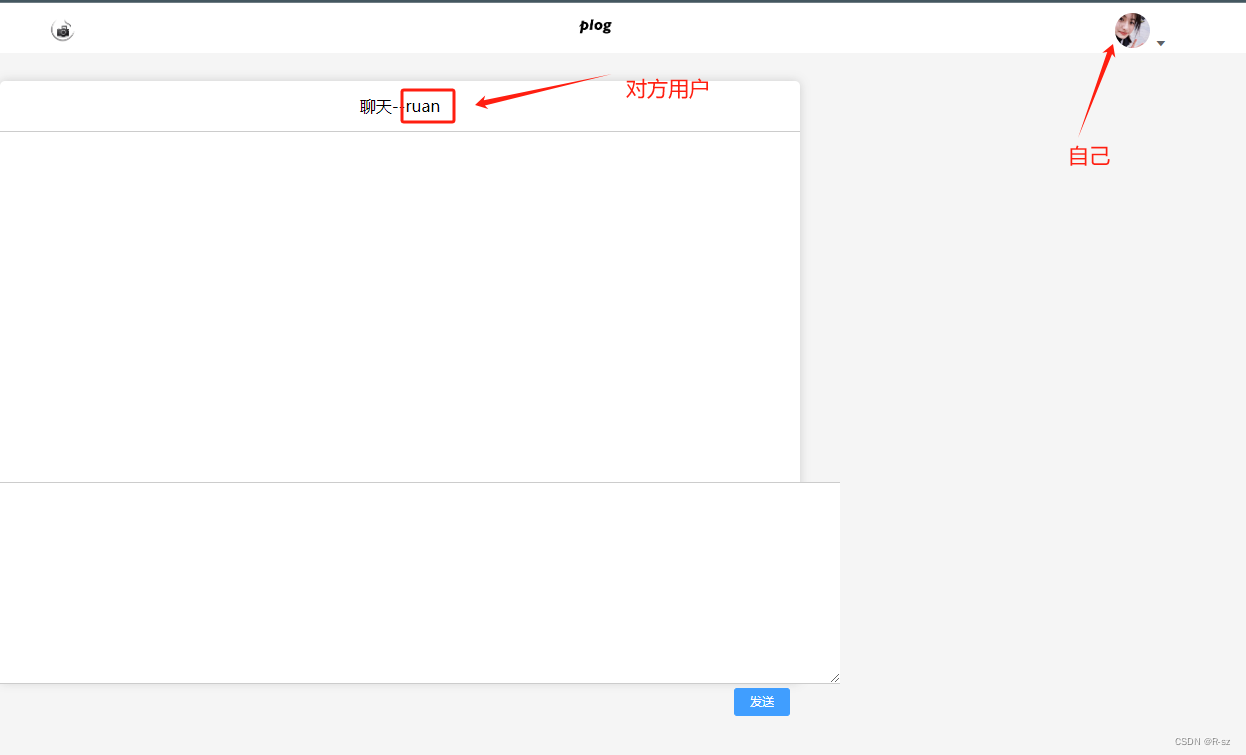
数据的截图
# 字段 说明 # Gender 性别 # Age 年龄 # Height 身高 # Weight 体重 # family_history_with_overweight 家族肥胖史 # FAVC 是否频繁食用高热量食物 # FCVC 食用蔬菜的频次 # NCP 食用主餐的次数 # CAEC 两餐之间的食品消费:always(总是);frequently(经常);sometimes(有时候) # SMOKE 是否吸烟 # CH2O 每日耗水量 # SCC 高热量饮料消耗量 # FAF 运动频率 # TUE 使用电子设备的时间 # CALC 酒精消耗量:0(无); frequently(经常);sometimes(有时候) # MTRANS 日常交通方式:Automobile(汽车);Bike(自行车);Motorbike(摩托车);Public Transportation(公共交通);Walking(步行) # 0be1dad 肥胖水平# 肥胖水平中各字段意思 # Ormal_Weight 正常 # Insufficient Weight 体重不足 # Obesity_Type_I 肥胖类型 I # Obesity_Type_ll 肥胖类型 II # Obesity_Type_lll 肥胖类型 III # Overweight_Level_I 一级超重 # Overweight_Level_Il 二级超重
# 了解了各个字段的含义后,我们来看问题 # 问题描述 # 相关性分析 # 群体特征分析 # 构建肥胖风险预测模型 # 数据可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pylab as pl
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder,LabelEncoder,StandardScaler
from scipy.stats import spearmanr
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_reportdata = pd.read_csv("obesity_level.csv")
pd.set_option("display.max_columns",1000)
print(data.head(5))导入需要用到的第三方库,导入数据
# 知道了问题后我们先对数据进行预处理
print(data.info())
print(data.isnull().sum())
data = data.drop('id',axis=1)
data['Age'] = data['Age'].astype('int64')# 没有缺失值,因此我们来看数据
# 首先ID这一列对我们的分析没有任何帮助,我们将其删除
# 由于年龄应该是整数,但是数据集中年龄存在小数,我们将其转换为整数
处理之后,我们来看第一个问题,相关性分析,想到什么——热力图(斯皮尔曼相关系数)
columns = ['Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight','FAVC', 'FCVC', 'NCP', 'CAEC', 'SMOKE', 'CH2O', 'SCC', 'FAF', 'TUE','CALC', 'MTRANS']for col in columns:if data[col].dtype == object:df = pd.crosstab(data[col],data['0be1dad'])pl.figure()sns.heatmap(df,cmap='coolwarm',annot=True,fmt='2g')plt.xlabel(col)plt.ylabel('0be1dad')# plt.tight_layout()# plt.xticks(rotation=60)plt.title(col+'与肥胖水平之间的相关性')else:data[col+ '_bins'] = pd.qcut(data[col],q=5,duplicates='drop')df =data.groupby([col+ '_bins','0be1dad']).size().unstack()df.plot(kind='bar',stacked=True)plt.xlabel(col)plt.ylabel('0be1dad')# plt.tight_layout()# plt.xticks(rotation=60)plt.title(col + '与肥胖水平之间的相关性')plt.show()
由于图像绘制较多,因此我选择部分图像进行展示





从途中我们可以看出各个特征与肥胖水平之间的相关性,但是图片可以得到的数据有限,具体欸到相关性强弱还得需要通过数据来分析。首先我们先将分类变量转换为数值型变量。
le = LabelEncoder()
for col in columns:if data[col].dtype == object:data[col] = le.fit_transform(data[col])print(data.head())
# 计算斯皮尔曼秩相关系数
for i in columns:correlation, p_value = spearmanr(data[i],data['0be1dad'])print("变量"+i+"与变量0be1dad之间的斯皮尔曼秩相关系数",correlation)print("p值",p_value) 变量Gender与变量0be1dad之间的斯皮尔曼秩相关系数 0.014658850601937863
p值 0.03468814382118435
变量Age与变量0be1dad之间的斯皮尔曼秩相关系数 0.2859097257571513
p值 0.0
变量Height与变量0be1dad之间的斯皮尔曼秩相关系数 0.0549005296297657
p值 2.465342094292171e-15
变量Weight与变量0be1dad之间的斯皮尔曼秩相关系数 0.40279883619705414
p值 0.0
变量family_history_with_overweight与变量0be1dad之间的斯皮尔曼秩相关系数 0.2863193269279612
p值 0.0
变量FAVC与变量0be1dad之间的斯皮尔曼秩相关系数 0.015215732134776854
p值 0.028363458172357518
变量FCVC与变量0be1dad之间的斯皮尔曼秩相关系数 0.06676140706468933
p值 6.036927997520049e-22
变量NCP与变量0be1dad之间的斯皮尔曼秩相关系数 -0.13504675225801754
p值 4.508309933218467e-85
变量CAEC与变量0be1dad之间的斯皮尔曼秩相关系数 0.24046194989929878
p值 8.204819691934083e-271
变量SMOKE与变量0be1dad之间的斯皮尔曼秩相关系数 -0.011154010915639693
p值 0.10805818554147692
变量CH2O与变量0be1dad之间的斯皮尔曼秩相关系数 0.17622305494933643
p值 2.0464562531581523e-144
变量SCC与变量0be1dad之间的斯皮尔曼秩相关系数 -0.0455429294387019
p值 5.214791611958936e-11
变量FAF与变量0be1dad之间的斯皮尔曼秩相关系数 -0.09845958938837115
p值 6.944014419452994e-46
变量TUE与变量0be1dad之间的斯皮尔曼秩相关系数 -0.05047637969363524
p值 3.422014415895151e-13
变量CALC与变量0be1dad之间的斯皮尔曼秩相关系数 0.12321280727640145
p值 5.040375691868427e-71
变量MTRANS与变量0be1dad之间的斯皮尔曼秩相关系数 -0.0721085385266057
p值 2.4264780504638294e-25
斯皮尔曼秩相关系数接近1表示变量之间呈现正相关,接近-1表示变量之间呈现负相关,接近0表示变量之间无相关性。
p值是用来判断统计显著性的指标,它告诉我们观察到的相关系数是否不太可能是由随机因素造成的。如果p值小于显著性水平(如0.05),则可以拒绝原假设,即两个变量不相关,从而认为斯皮尔曼相关系数具有统计学意义。这里面的数据2.4264780504638294e-25表示科学计数法2.4264*10的负25次方。
上次周挑战由于使用了标签编码来进行处理数据,因此,这周挑战使用独热编码来处理数据
scaler = StandardScaler()
for col in columns:if data[col].dtype != object:data[col] = scaler.fit_transform(data[col].values.reshape(-1,1))encode = OneHotEncoder(sparse_output=False)
for col in columns:if data[col].dtype == object:encode_data = encode.fit_transform(data[[col]])data.drop(col,axis=1,inplace=True)encode_columns = [f"{col}_{i}"for i in range(encode_data.shape[1])]data = pd.concat([data,pd.DataFrame(encode_data,columns=encode_columns)],axis=1)由于后面模型使用了逻辑回归,因此我们要对数据进行标准化处理。
# 选择一个常用的机器学习算法来构建肥胖风险预测模型。考虑到这是一个分类问题,我们可以选择以下算法之一: # # 逻辑回归(Logistic Regression):这是一种广泛用于分类问题的算法,特别是当特征数量不是很大时。 # 决策树(Decision Tree):这是一种基于树结构的模型,易于理解和解释。 # 随机森林(Random Forest):这是一种集成算法,通过组合多个决策树来提高性能。 # 支持向量机(Support Vector Machine):这是一种强大的分类算法,特别是在特征维度较高时。 # 所以我们选择将四种模型全部输出来综合判断哪个模型更好,为了方便所以我所有模型全部使用默认参数,涉及后期的模型调优我们可以指定模型参数
Dtree = DecisionTreeClassifier()
Rtree = RandomForestClassifier()
log = LogisticRegression(max_iter=1000)
svm = SVC()models = [Dtree,Rtree,log,svm]X = data.drop('0be1dad',axis=1)
y = data['0be1dad']X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)for model in models:model.fit(X_train,y_train)y_pred = model.predict(X_test)print(model.__class__.__name__+"模型的的分类报告:")print(classification_report(y_test,y_pred))print("该模型的分数" ,+ model.score(X_test,y_test))# 经过比较,我们选择随机森林来进行特征重要性分析
Rtree.fit(X_train,y_train)
importance = Rtree.feature_importances_
feature = X.columns
sort_index = importance.argsort()plt.figure()
plt.barh(range(len(sort_index)),importance[sort_index])
plt.yticks(range(len(sort_index)),[feature[i] for i in sort_index])
plt.xlabel("特征重要性")
plt.title("特征重要性")plt.show()
DecisionTreeClassifier模型的的分类报告:
precision recall f1-score support
0rmal_Weight 0.79 0.79 0.79 907
Insufficient_Weight 0.91 0.89 0.90 755
Obesity_Type_I 0.80 0.79 0.80 858
Obesity_Type_II 0.95 0.95 0.95 1005
Obesity_Type_III 0.99 0.99 0.99 1207
Overweight_Level_I 0.65 0.70 0.67 733
Overweight_Level_II 0.71 0.67 0.69 763
accuracy 0.84 6228
macro avg 0.83 0.83 0.83 6228
weighted avg 0.84 0.84 0.84 6228
该模型的分数 0.8432883750802826
RandomForestClassifier模型的的分类报告:
precision recall f1-score support
0rmal_Weight 0.82 0.89 0.85 907
Insufficient_Weight 0.94 0.90 0.92 755
Obesity_Type_I 0.88 0.86 0.87 858
Obesity_Type_II 0.97 0.98 0.98 1005
Obesity_Type_III 1.00 1.00 1.00 1207
Overweight_Level_I 0.77 0.74 0.75 733
Overweight_Level_II 0.79 0.78 0.79 763
accuracy 0.89 6228
macro avg 0.88 0.88 0.88 6228
weighted avg 0.89 0.89 0.89 6228
该模型的分数 0.8909762363519589
LogisticRegression模型的的分类报告:
precision recall f1-score support
0rmal_Weight 0.84 0.80 0.82 907
Insufficient_Weight 0.88 0.92 0.90 755
Obesity_Type_I 0.82 0.82 0.82 858
Obesity_Type_II 0.94 0.98 0.96 1005
Obesity_Type_III 0.99 1.00 1.00 1207
Overweight_Level_I 0.73 0.73 0.73 733
Overweight_Level_II 0.72 0.68 0.70 763
accuracy 0.86 6228
macro avg 0.85 0.85 0.85 6228
weighted avg 0.86 0.86 0.86 6228
该模型的分数 0.8625561978163134
SVC模型的的分类报告:
precision recall f1-score support
0rmal_Weight 0.81 0.82 0.82 907
Insufficient_Weight 0.91 0.90 0.91 755
Obesity_Type_I 0.85 0.83 0.84 858
Obesity_Type_II 0.95 0.98 0.96 1005
Obesity_Type_III 1.00 1.00 1.00 1207
Overweight_Level_I 0.68 0.72 0.70 733
Overweight_Level_II 0.74 0.71 0.72 763
accuracy 0.86 6228
macro avg 0.85 0.85 0.85 6228
weighted avg 0.86 0.86 0.86 6228
该模型的分数 0.8638407193320488
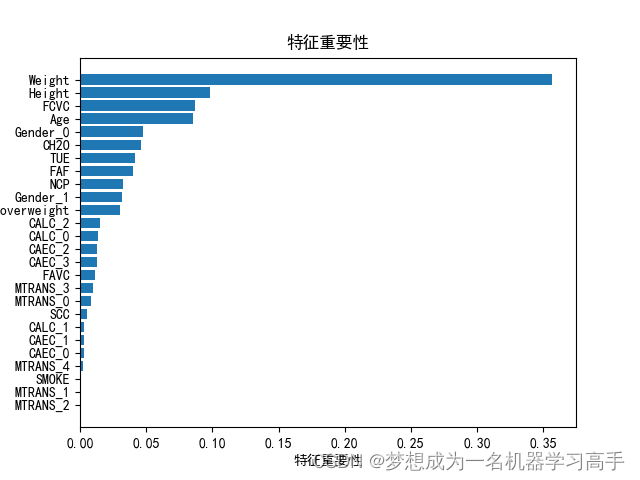
目前可暂时得出如下结论:
1、FCVC(是否频繁食用高热量食物),Age(年龄),Weight(体重),Height(身高), 对肥胖风险影响较大;
2、交通方式对肥胖风险影响几乎没有。