目录
1.效果展示
2.原理学习
3.流程分析
4.资料
一、效果展示 -- (推理素材来源于网络,如有侵权,联系立删!)
唱歌效果(歌曲有suno生成)
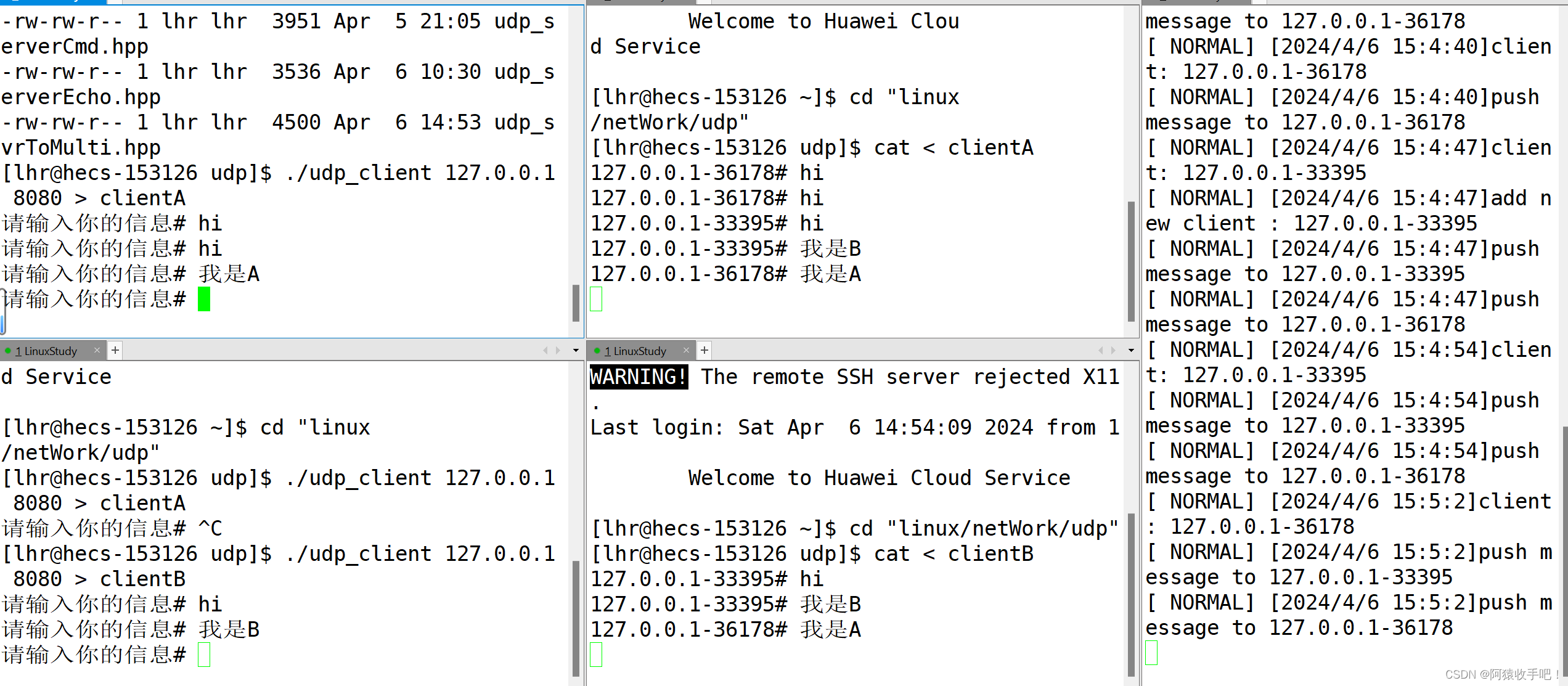
用于推理的视频素材来源于网络,如有侵权,立删
二、原理学习
目前只开源了推理代码和预训练模型;
训练代码;技术论文等尚未开源,通过模型架构图来进行分析。
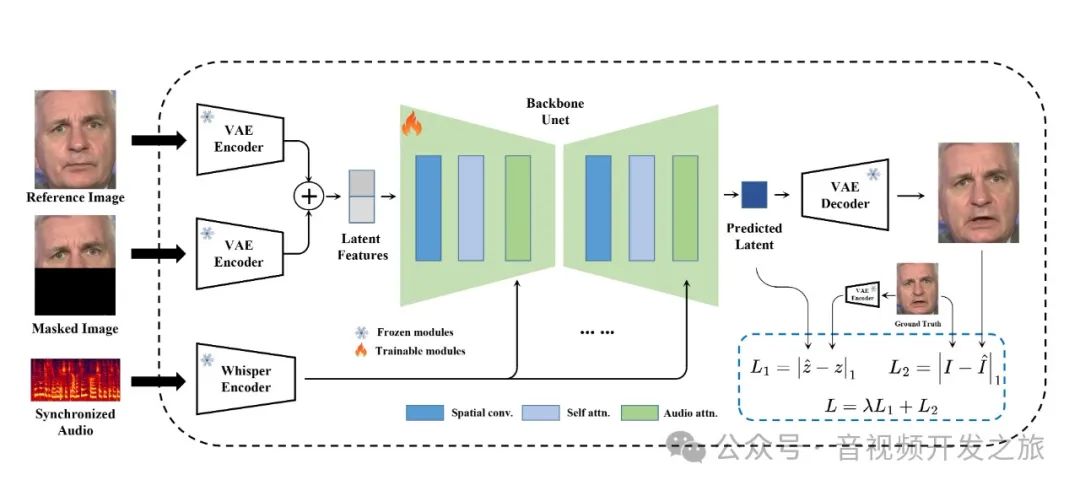
MuseTalk 在潜空间中进行训练,其中图像由冻结的 VAE 进行编码。音频由冻结的 whisper-tiny 模型编码。生成网络的架构借鉴了stable-diffusion-v1-4 的 UNet,其中音频嵌入通过交叉注意力融合到图像嵌入。
三、流程分析
推理:
python -m scripts.inference --inference_config configs/inference/test.yamltest.yaml配置如下:
task_0:video_path: "data/video/02.mp4"audio_path: "data/audio/女-悲伤情歌.wav"bbox_shift: 3
1. 从视频中提取视频帧
save_dir_full = os.path.join(args.result_dir, input_basename)os.makedirs(save_dir_full,exist_ok = True)cmd = f"ffmpeg -v fatal -i {video_path} -start_number 0 {save_dir_full}/%08d.png"os.system(cmd)input_img_list = sorted(glob.glob(os.path.join(save_dir_full, '*.[jpJP][pnPN]*[gG]')))fps = get_video_fps(video_path)
2. 对音频进行特征提取
whisper_feature = audio_processor.audio2feat(audio_path)whisper_chunks = audio_processor.feature2chunks(feature_array=whisper_feature,fps=fps)
3. 提取人脸关键点和人脸box
coord_list, frame_list = get_landmark_and_bbox(input_img_list, bbox_shift)4. 根据人脸box对图像进行裁剪,并缩放到256,进行vae编码到潜空间
i = 0input_latent_list = []for bbox, frame in zip(coord_list, frame_list):if bbox == coord_placeholder:continuex1, y1, x2, y2 = bboxcrop_frame = frame[y1:y2, x1:x2]crop_frame = cv2.resize(crop_frame,(256,256),interpolation = cv2.INTER_LANCZOS4)latents = vae.get_latents_for_unet(crop_frame)input_latent_list.append(latents)
5. 平滑第一帧和最后一帧,使得视频可以循环
# to smooth the first and the last frameframe_list_cycle = frame_list + frame_list[::-1]coord_list_cycle = coord_list + coord_list[::-1]input_latent_list_cycle = input_latent_list + input_latent_list[::-1]
6. 进行推理
############################################## inference batch by batch ##############################################print("start inference")video_num = len(whisper_chunks)batch_size = args.batch_sizegen = datagen(whisper_chunks,input_latent_list_cycle,batch_size)res_frame_list = []for i, (whisper_batch,latent_batch) in enumerate(tqdm(gen,total=int(np.ceil(float(video_num)/batch_size)))):tensor_list = [torch.FloatTensor(arr) for arr in whisper_batch]audio_feature_batch = torch.stack(tensor_list).to(unet.device) # torch, B, 5*N,384audio_feature_batch = pe(audio_feature_batch)pred_latents = unet.model(latent_batch, timesteps, encoder_hidden_states=audio_feature_batch).samplerecon = vae.decode_latents(pred_latents)for res_frame in recon:res_frame_list.append(res_frame)
7. 生成的唇形同步的256人脸头像再贴回到原图片
print("pad talking image to original video")for i, res_frame in enumerate(tqdm(res_frame_list)):bbox = coord_list_cycle[i%(len(coord_list_cycle))]ori_frame = copy.deepcopy(frame_list_cycle[i%(len(frame_list_cycle))])x1, y1, x2, y2 = bboxtry:res_frame = cv2.resize(res_frame.astype(np.uint8),(x2-x1,y2-y1))except:#print(bbox)continuecombine_frame = get_image(ori_frame,res_frame,bbox)cv2.imwrite(f"{result_img_save_path}/{str(i).zfill(8)}.png",combine_frame)
8. 合并视频帧为视频,与音轨合并输出最终视频
cmd_img2video = f"ffmpeg -y -v fatal -r {fps} -f image2 -i {result_img_save_path}/%08d.png -vcodec libx264 -vf format=rgb24,scale=out_color_matrix=bt709,format=yuv420p -crf 18 temp.mp4"print(cmd_img2video)os.system(cmd_img2video)cmd_combine_audio = f"ffmpeg -y -v fatal -i {audio_path} -i temp.mp4 {output_vid_name}"print(cmd_combine_audio)os.system(cmd_combine_audio)
四、资料
MuseTalk: https://github.com/TMElyralab/MuseTalk
感谢你的阅读
接下来我们继续学习输出AIGC相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流



![2024.4.1-[作业记录]-day06-认识 CSS(三大特性、引入方式)](https://img-blog.csdnimg.cn/direct/ef0c8ad7c6904991936436e61d77d790.png)