文章目录
- 一、Collection
- 二、Map、Set、List的不同
- 三、List
- 1、ArrayList
- 2、LinkedList
- 四、Map
- 1、HashMap
- 2、LinkedHashMap
- 3、TreeMap
- 五、Set
一、Collection
Collection 的常用方法
- public boolean add(E e):把给定的对象添加到当前集合中 。
- public void clear():清空集合中所有的元素。
- public boolean remove(E e):把给定的对象在当前集合中删除。
- public boolean contains(E e):判断当前集合中是否包含给定的对象。
- public boolean isEmpty():判断当前集合是否为空。
- public int size():返回集合中元素的个数。
- public Object[] toArray():转换为数组。
当需要数组转换为集合时,使用 Arrays.asList(list)
Collection 的遍历方式
- 迭代器 iterator():获取当前集合迭代对象,然后调用方法
1、hasNext():当前位置是否有数据2、next():返回当前位置,并向后移动Collection<Integer> list = new ArrayList<>();list.add(1);Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}
迭代器遍历注意事项
1、迭代器不可多次获取当前元素,否则会报错,因为每一次获取都会向后移动,你一次判断多次获取,则会越界抛出异常NoSuchElementException
2、迭代器不支持集合自身方法remove(),但支持迭代器对象自身的remove()方法(集合自身的移除方法会导致一些其他元素没有遍历到,到)
Collection<Integer> list = new ArrayList<>();list.add(1);list.add(2);Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {if (iterator.next() == 2){// list.remove(1); 此代码报错,不支持iterator.remove();}}System.out.println(list); 输出 [1]
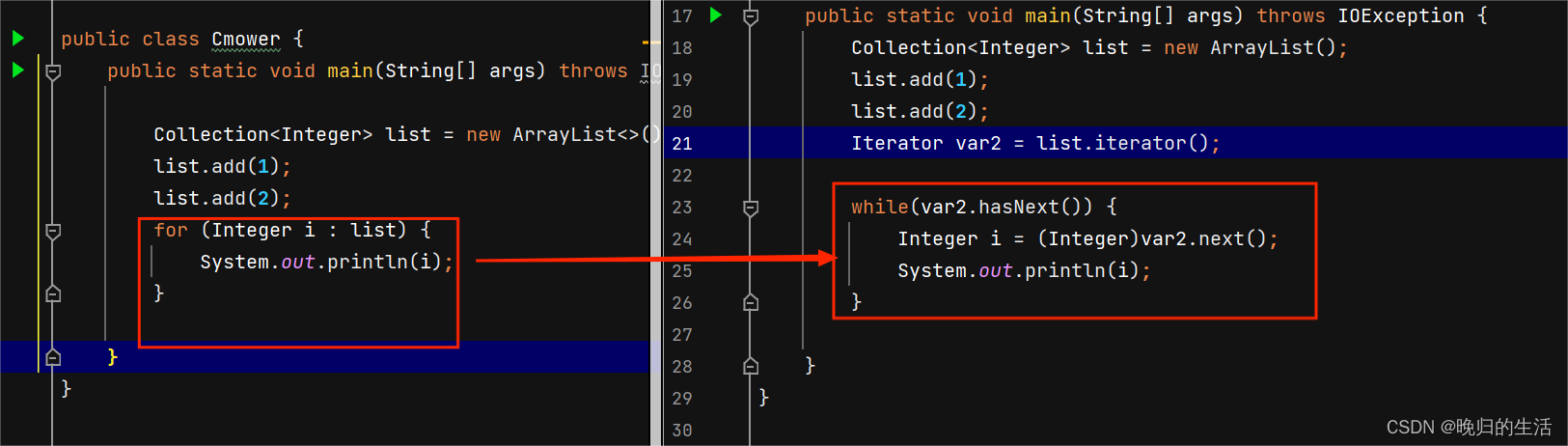
- 增强for
for(数据类型 变量名 :数组或集合){} :支持集合和数组遍历
查看反编译文件,发现增强for(数据类型 变量名 :数组或集合){} 底层是基于iterator迭代器实现的
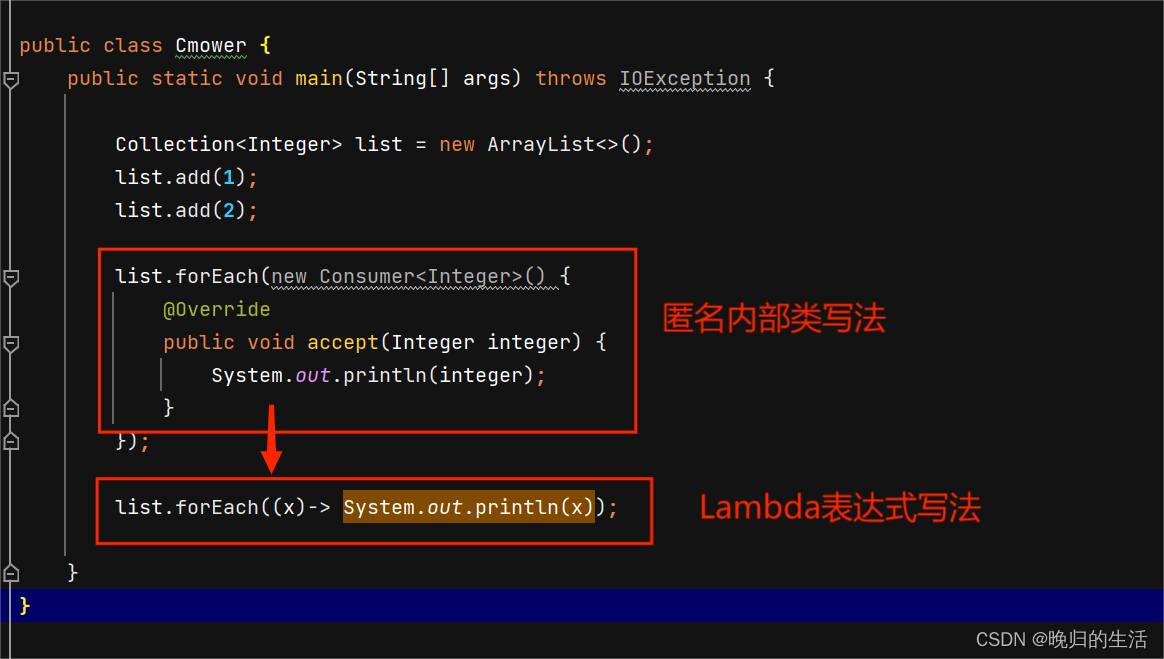
- Lambda表达式
Lambda表达式是简化函数式接口的内部类方法(函数式接口是指接口,仅且只有一个抽象类方法,被@FunctionalInterface修饰)
forEach(匿名内部类的Lambda的简化表达式)
Collection不支持普通for()遍历
二、Map、Set、List的不同
- Collection是单列集合顶级父类接口
- Map是双列集合顶级父类接口
| Map | Set | List |
|---|---|---|
| HashMap | HashSet | ArrayList |
| TreeMap | TreeSet | LinkedList |
| LinkedHashMap | LinkedHaspSet | — |
| 键值对存储数据 | 存取无序 不重复 无索引 | 存取有序 可重复 有索引 |
三、List
- List:有序、可重复、有索引
- 常用特有方法
add(int index , E e)
remove(int index)
set(int index , E e)
get(int index)
- 支持的遍历方式:迭代器遍历、增强for遍历、Lambda遍历、普通for遍历
1、ArrayList
- ArrayList是List接口实现类,存取有序、可以存储重复元素、可以使用下标操作元素,因为底层是基于数组实现的,在内存中是连续的
- 支持重复数据的插入
- 适合快速查询,但是不适合中间插入和删除操作
- ArrayList实例化后,当你插入第一个数据开始,它的数组大小会变为10;当你插入的数据超过这个数组大小,ArrayList会动态的对数组实现扩容:新数组大小 = 旧数组大小 × 1.5
默认大小
private static final int DEFAULT_CAPACITY = 10;
....
扩容方法
private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1); 扩容至原来的1.5倍if (newCapacity - minCapacity < 0) 新的容量小于指定容量的最小值newCapacity = minCapacity; 扩容至指定容量的最小值(第一次就是10)if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); 将数组复制到一个新数组中,长度为 newCapacity
}
>> 相当于除2,而 << 相当于乘2
- 常用方法
| 方法名 | 作用 |
|---|---|
| list.add(“a”) | 直接添加数据 |
| list.add(1, “b”) | 根据索引位置,添加数据 |
| list.contains(“a”) | 判断是否包含数据 |
| list.get(1) | 根据索引位置获取数据 |
| list.indexOf(“a”) | 根据数据本身返回索引位置 |
| list.set(1, “c”) | 根据索引修改数据 |
| list.remove(“a”) | 根据数据本身直接移除数据 |
| list.remove(1) | 根据索引移除数据 |
2、LinkedList
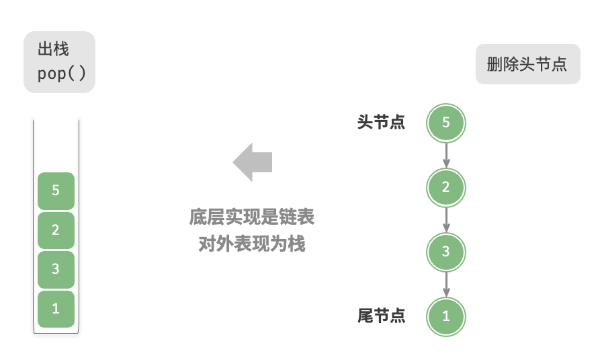
- LinkedList 实现接口 List,存取有序、支持索引操作,底层由双向链表实现,只能从一端开始遍历,查询效率低,在内存中不是连续的
- 因为链表结构,LinkedList 更适合删除插入操作,只需要修改前结点和后一个结点引用指向即可
- 可以插入重复数据
基于添加add(),分析一下源码
1、定义一个集合,并添加数据,看看内部实现
public static void main(String args[]) {LinkedList<Object> list = new LinkedList<>();list.add("a");list.add(1,"b");System.out.println(list);}
2、查看根据索引添加数据的内部实现
public void add(int index, E element) {checkPositionIndex(index); //检查索引是否越界if (index == size) //添加位置在最后一个节点linkLast(element); elselinkBefore(element, node(index)); //任意结点前插入数据}
- 1、如果索引越界则抛出异常 IndexOutOfBoundsException
- 2、索引不越界时,判断是否添加位置是否在最后一个,是则添加,不是则调用 linkBefore() 方法
3、我们看 linkBefore() 中的**node(index)**方法,
Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) { //索引在链表左边Node<E> x = first; //获取第一个结点for (int i = 0; i < index; i++) //遍历,并返回index处结点x = x.next;return x;} else { //索引在链表右边Node<E> x = last;for (int i = size - 1; i > index; i--) //遍历,并返回index处结点x = x.prev;return x;}}
看到返回值和内部代码实现,可知主要作用即返回指定元素索引处的节点。现在返回 linkBefore(element, node(index))
void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev; 获取索引处前一结点final Node<E> newNode = new Node<>(pred, e, succ); 新建一个新的结点succ.prev = newNode; 索引处的前指针指向新结点if (pred == null) 如果前结点为空,则新结点变为头节点first = newNode;elsepred.next = newNode; 否则,前结点的向后指针指向新结点size++; 长度加一modCount++; 表示修改次数加一}
看了上面代码,大致应该知道添加内部代码实现流程,其他的方法就不一一列举,有兴趣去看看源码即可
四、Map
- key不支持重复,value可以重复,如果key重复则value会被覆盖
- 常用方法:
(1)put(K key, V value)
(2)get(Object key)
(3)size()
(4)clear()
(5)isEmpty ()
(6)remove(Object key)
(7)values():获取全部值
(8)keySet() :获取全部键
(9)containsKey():是否包含键
(10)containsValue():是否包含值
(11)putAll():把一个map添加进另一个map
(12)entrySet():获取全部集合内所有对象数据
- 遍历方式:
1、键遍历获取值:可以根据keySet()获取全部键,使用增强for()遍历
2、键值对遍历获取值:可以根据entrySet()获取一个set集合数据,再使用增强for()遍历,getKey()可以获取键,getValue()获取值
3、 Lambda遍历:底层其实就是键值对遍历map.forEach((k, v) -> {System.out.println(v);});
1、HashMap
1、 HashMap 底层由哈希表(数组、链表、红黑树)实现
2、HashMap 初始默认大小是16,负载因子是0.75,当填充元素达到扩容要求时,HashMap会自动扩容,每次扩容是旧数组的两倍
3、HashMap实现接口Map,所有是无序的、不支持重复、无索引
HashMap细节:
1、HashMap添加数据,如果此时数组大小正好插满了12(16×0.75)个时,如果当前发生冲突则数组扩容,如果没有发生冲突则不扩容
2、当数组大小大于或者等于64时,才会把链表大于8的转换为红黑树
2、LinkedHashMap
LinkedHashMap:有序、不重复、无索引,底层由哈希表(数组、链表、红黑树)实现,并且维护了一个双向链表机制
3、TreeMap
按照key的大小升序排序,不重复、无索引,底层基于红黑树实现
五、Set
Set:无序、不可重复、无索引
- 常用方法:几乎都是Collection的方法
- HashSet:存取无序、不可重复、无索引操作,底层由哈希表(数组、链表、红黑树)实现
- 如果自定义对象,需要重写hashCod()和equal()方法,实现不可重复
- LinkedHashSet:存取有序、不可重复、无索引操作,底层由哈希表(数组、链表、红黑树)实现,并且维护了一个双向链表机制
- TreeSet:内部升序排序、不可重复、无索引操作,基于红黑树实现
-
数值包装类型和字符串这两种对象可以升序排序
-
其他对象不可以排序,但是可以自定义排序规则
-
排序规则
- 实现接口 Comparable,自定义compareTo()方法
- 调用有参构造器,设置Comparator对象,实现compare()方法
- 如果两则都实现了,则选择就近原则,选择Comparator对象比较