文章目录
- 上下文关联
- 对话轮数
- 向量匹配 top k
- 控制生成质量的参数
- 参数设置心得
上下文关联
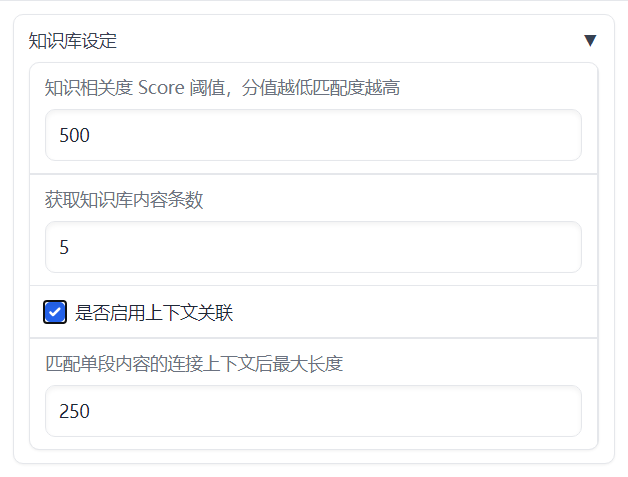
上下文关联相关参数:
- 知识相关度阈值score_threshold
- 内容条数k
- 是否启用上下文关联chunk_conent
- 上下文最大长度chunk_size
其主要作用是在所在文档中扩展与当前query相似度较高的知识库的内容,作为相关信息与query按照prompt规则组合后作为输入获得模型的回答。
- 获取查询句query嵌入:
faiss.py
def similarity_search_with_score(self, query: str, k: int = 4) -> List[Tuple[Document, float]]:"""Return docs most similar to query.Args:query: Text to look up documents similar to.k: Number of Documents to return. Defaults to 4.Returns:List of Documents most similar to the query and score for each"""embedding = self.embedding_function(query)docs = self.similarity_search_with_score_by_vector(embedding, k)return docs
- 上下文生成:
MyFAISS.py
def seperate_list(self, ls: List[int]) -> List[List[int]]:# TODO: 增加是否属于同一文档的判断lists = []ls1 = [ls[0]]for i in range(1, len(ls)):if ls[i - 1] + 1 == ls[i]:ls1.append(ls[i])else:lists.append(ls1)ls1 = [ls[i]]lists.append(ls1)return listsdef similarity_search_with_score_by_vector(self, embedding: List[float], k: int = 4) -> List[Document]:faiss = dependable_faiss_import()# (1,1024)vector = np.array([embedding], dtype=np.float32)# 默认FALSEif self._normalize_L2:faiss.normalize_L2(vector)# shape均为(1, k),这步获取与query有top-k相似度的知识库scores, indices = self.index.search(vector, k)docs = []id_set = set()store_len = len(self.index_to_docstore_id)rearrange_id_list = False# 遍历找到的k个最相似知识库的索引# k是第一次的筛选条件,score是第二次的筛选条件for j, i in enumerate(indices[0]):if i == -1 or 0 < self.score_threshold < scores[0][j]:# This happens when not enough docs are returned.continueif i in self.index_to_docstore_id:_id = self.index_to_docstore_id[i]# 执行接下来的操作else:continue# index→id→contentdoc = self.docstore.search(_id)if (not self.chunk_conent) or ("context_expand" in doc.metadata and not doc.metadata["context_expand"]):# 匹配出的文本如果不需要扩展上下文则执行如下代码if not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")doc.metadata["score"] = int(scores[0][j])docs.append(doc)continue# 其实存的都是indexid_set.add(i)docs_len = len(doc.page_content)# 跟外部变量定义的k重名了,烂# 一个知识库是分句后得到的一句话,i是当前知识库在总知识库中的位置,store_len是总知识库大小# 所以k说的是扩充上下文时最多能跨多少个知识库for k in range(1, max(i, store_len - i)):break_flag = Falseif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "forward":expand_range = [i + k]elif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "backward":expand_range = [i - k]else:# i=4922, k=1 → [4923, 4921]expand_range = [i + k, i - k]for l in expand_range:# 确保扩展上下文时不会造成重复if l not in id_set and 0 <= l < len(self.index_to_docstore_id):_id0 = self.index_to_docstore_id[l]doc0 = self.docstore.search(_id0)# 如果当前字数大于250或者是知识库跨了文件,扩充上下文过程终止# 这一句有些问题,有一端跨文件就终止,应该是两端同时跨才终止才对if docs_len + len(doc0.page_content) > self.chunk_size or doc0.metadata["source"] != \doc.metadata["source"]:break_flag = Truebreakelif doc0.metadata["source"] == doc.metadata["source"]:docs_len += len(doc0.page_content)id_set.add(l)rearrange_id_list = Trueif break_flag:break# 如果没有扩展上下文(不需要或是不能)if (not self.chunk_conent) or (not rearrange_id_list):return docsif len(id_set) == 0 and self.score_threshold > 0:return []id_list = sorted(list(id_set))# 连续必然属于同一文档,但不连续也可能在同一文档# 返回二级列表,第一级是连续的index列表,第二级是具体indexid_lists = self.seperate_list(id_list)for id_seq in id_lists:for id in id_seq:if id == id_seq[0]:_id = self.index_to_docstore_id[id]# doc = self.docstore.search(_id)doc = copy.deepcopy(self.docstore.search(_id))else:_id0 = self.index_to_docstore_id[id]doc0 = self.docstore.search(_id0)doc.page_content += " " + doc0.page_contentif not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")# indices为相关文件的索引# 因为可能会将多个连续的id合并,因此需要将同一seq内所有位于top-k的知识库的分数取最小值作为seq对应的分数doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]])doc.metadata["score"] = int(doc_score)docs.append(doc)# 注意这里docs没有按相似度排序,可以自行加个sortreturn docs
- prompt生成:
local_doc_qa.py
def get_knowledge_based_answer(self, query, vs_path, chat_history=[], streaming: bool = STREAMING):related_docs_with_score = vector_store.similarity_search_with_score(query, k=self.top_k)torch_gc()if len(related_docs_with_score) > 0:prompt = generate_prompt(related_docs_with_score, query)else:prompt = queryanswer_result_stream_result = self.llm_model_chain({"prompt": prompt, "history": chat_history, "streaming": streaming})def generate_prompt(related_docs: List[str],query: str,prompt_template: str = PROMPT_TEMPLATE, ) -> str:context = "\n".join([doc.page_content for doc in related_docs])prompt = prompt_template.replace("{question}", query).replace("{context}", context)return prompt
对话轮数
其实就是要存多少历史记录,如果为0的话就是在执行当前对话时不考虑历史问答
- 模型内部调用时使用,以chatglm为例:
chatglm_llm.py
def _generate_answer(self,inputs: Dict[str, Any],run_manager: Optional[CallbackManagerForChainRun] = None,generate_with_callback: AnswerResultStream = None) -> None:history = inputs[self.history_key]streaming = inputs[self.streaming_key]prompt = inputs[self.prompt_key]print(f"__call:{prompt}")# Create the StoppingCriteriaList with the stopping stringsstopping_criteria_list = transformers.StoppingCriteriaList()# 定义模型stopping_criteria 队列,在每次响应时将 torch.LongTensor, torch.FloatTensor同步到AnswerResultlistenerQueue = AnswerResultQueueSentinelTokenListenerQueue()stopping_criteria_list.append(listenerQueue)if streaming:history += [[]]for inum, (stream_resp, _) in enumerate(self.checkPoint.model.stream_chat(self.checkPoint.tokenizer,prompt,# 为0时history返回[]history=history[-self.history_len:-1] if self.history_len > 0 else [],max_length=self.max_token,temperature=self.temperature,top_p=self.top_p,top_k=self.top_k,stopping_criteria=stopping_criteria_list)):
向量匹配 top k
虽然放在了模型配置那一页,但实际上还是用来控制上下文关联里面的内容条数k的,不知道为什么写了两遍。。。
控制生成质量的参数
这些参数没有在前端显式地给出,而是写死在了模型定义里
- 模型定义,以chatglm为例:
chatglm_llm.py
class ChatGLMLLMChain(BaseAnswer, Chain, ABC):max_token: int = 10000temperature: float = 0.01# 相关度top_p = 0.4# 候选词数量top_k = 10checkPoint: LoaderCheckPoint = None# history = []history_len: int = 10
参数设置心得
- score_threshold和k设太小会找不到问题对应的原文件,太大找到一堆不相关的
- chunk_size设太小不能在原文件里找到问题对应的原文,太大无法有效归纳出答案
- temperature和top_p默认值下生成的答案基本固定,但也很死板;过大的temperature导致回答的事实不稳定;过大的top_p导致回答的语言风格不稳定;调整top_k没发现结果有什么变化