目录
一、集群的作用
二、Redis集群的数据分片
三、集群的工作原理编辑
四、搭建Redis群集模式
1.准备环境
1.1 首先安装redis
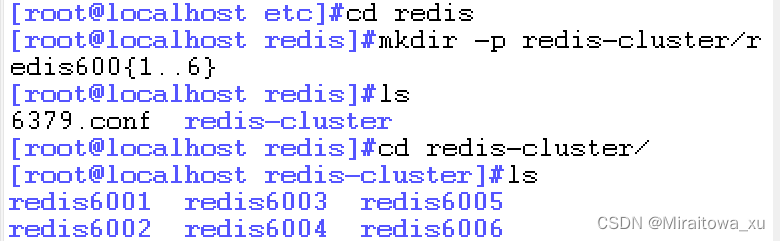
1.2 在etc下创建redis
1.3再在redis中创建redis-cluster/redis600{1..6}文件
1.4 做个for循环
1.5 开启群集功能
1.6启动redis节点
1.7 启动集群
1.8 测试集群
总结
一、集群的作用
(1)数据分区:数据分区(或称数据分片)是集群最核心的功能。 集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。 Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
(2)高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
二、Redis集群的数据分片
Redis集群引入了哈希槽的概念
Redis集群有16384个哈希槽(编号0-16383)
集群的每个节点负责一部分哈希槽
每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
三、集群的工作原理
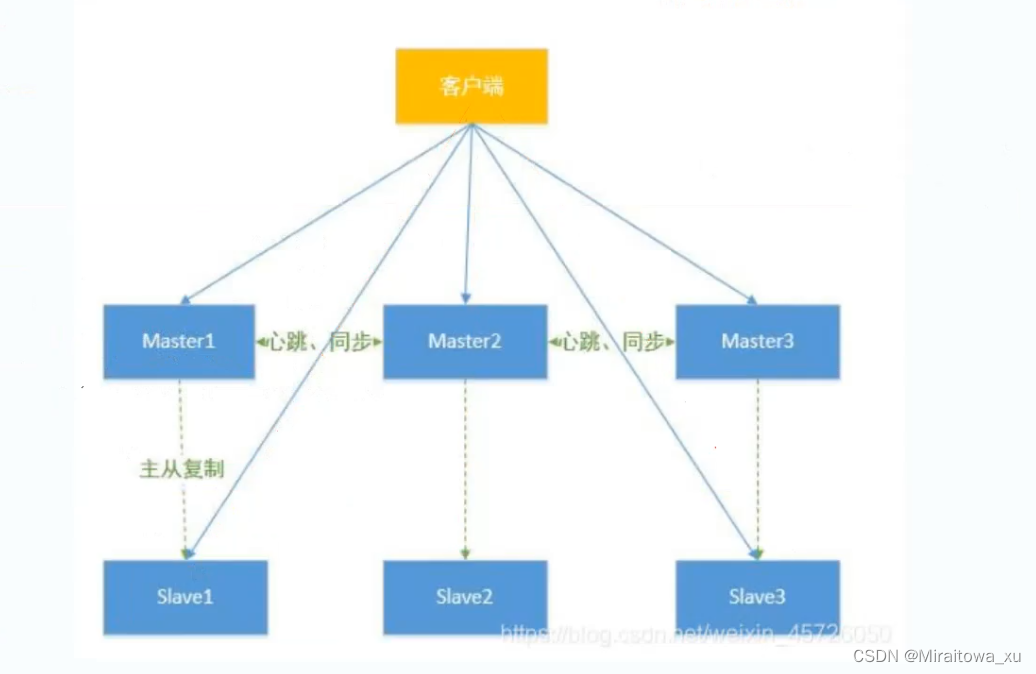
Master节点:
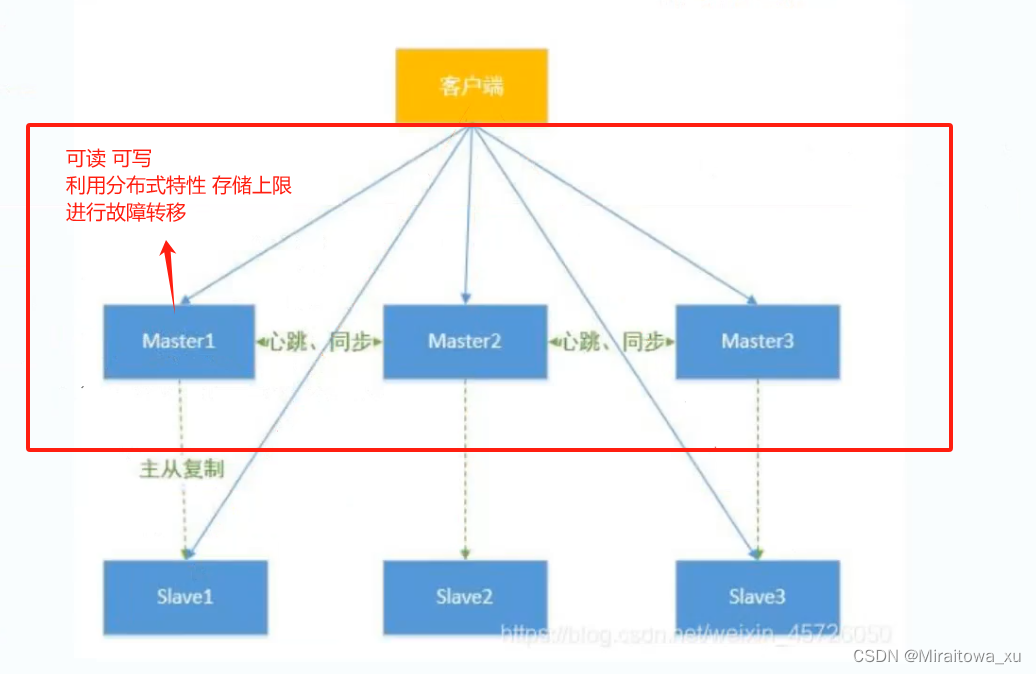
Master的功能:
- 读写可以负载均衡
- 自动故障转移
- 突破了单机存储限制
Slave节点:

四、搭建Redis群集模式
1.准备环境
redis的集群一般需要6个节点,3主3从。
方便起见,这里所有节点在同一台服务器上模拟:
以端口号进行区分:3个主节点端口号:6001/6002/6003,对应的从节点端口号:6004/6005/6006。
1.1 首先安装redis
cd /opt
##上传tar包[root@localhost opt]#ls
redis-5.0.7.tar.gz rhyum install -y gcc gcc-c++ make ##安装编译环境[root@localhost opt]#tar xf redis-5.0.7.tar.gz ##解压
[root@localhost opt]#cd redis-5.0.7/ ##切换目录
[root@localhost redis-5.0.7]#ls
[root@localhost redis-5.0.7]#make ##编译安装
[root@localhost redis-5.0.7]#make prefix=/usr/local/redis install1.2 在etc下创建redis

![]()
1.3再在redis中创建redis-cluster/redis600{1..6}文件
1.4 做个for循环
for i in {1..6}
do
cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
done

1.5 开启群集功能
其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
在redis.conf中修改配置文件
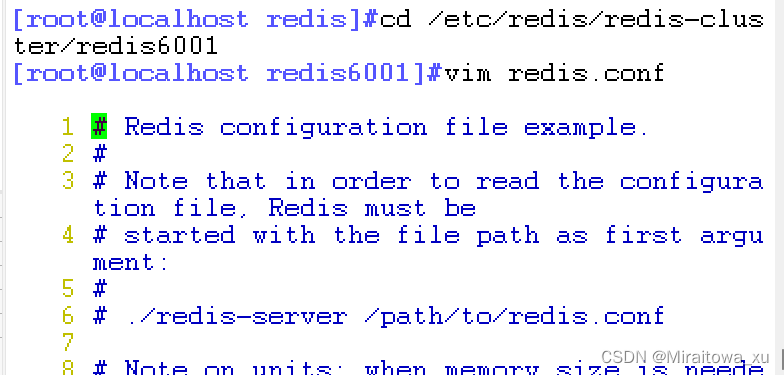
#bind 127.0.0.1 #69行,注释掉bind 项,默认监听所有网卡
protected-mode no #88行,修改,关闭保护模式
port 6001 #92行,修改,redis监听端口,
daemonize yes #136行,开启守护进程,以独立进程启动
cluster-enabled yes #832行,取消注释,开启群集功能
cluster-config-file nodes-6001.conf #840行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #846行,取消注释群集超时时间设置
appendonly yes #699行,修改,开启AOF持久化




其他也是如此操作为了简单我们可以直接复制覆盖

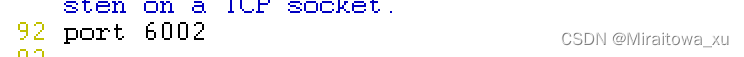
![]()
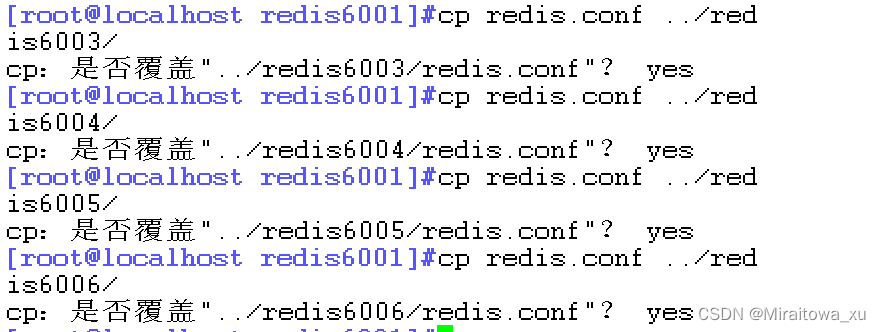
然后一个一个修改配置文件即可

步骤如上:
- 92行修改redis监听端口
- 840行群集名称文件设置
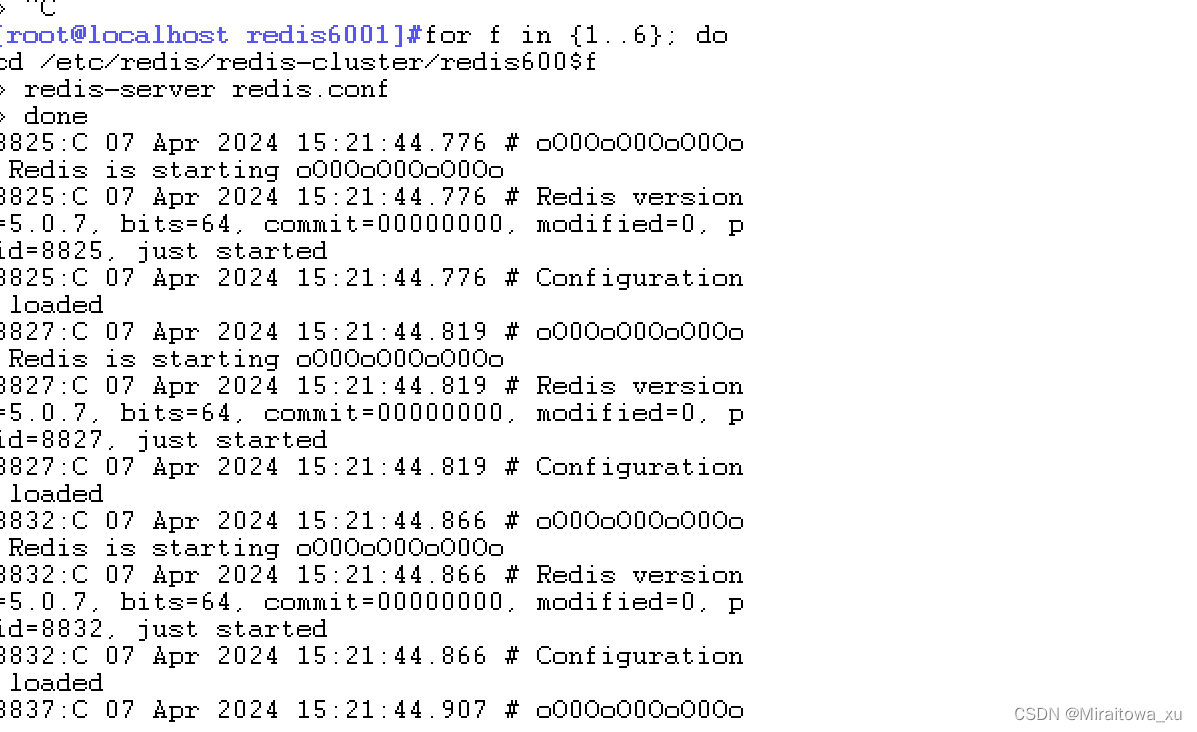
1.6启动redis节点
分别进入那六个文件夹,执行命令:redis-server redis.conf ,来启动redis节点
for d in {1..6}
do
cd /etc/redis/redis-cluster/redis600$d
redis-server redis.conf
done
ps -ef | grep redis
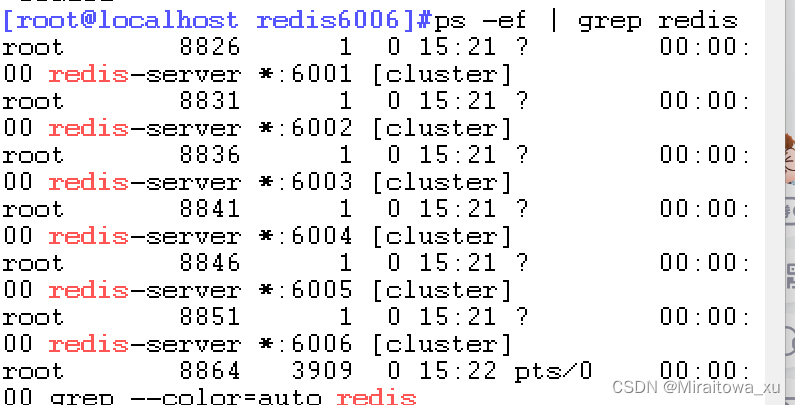
1.7 启动集群
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1也可以使用IP地址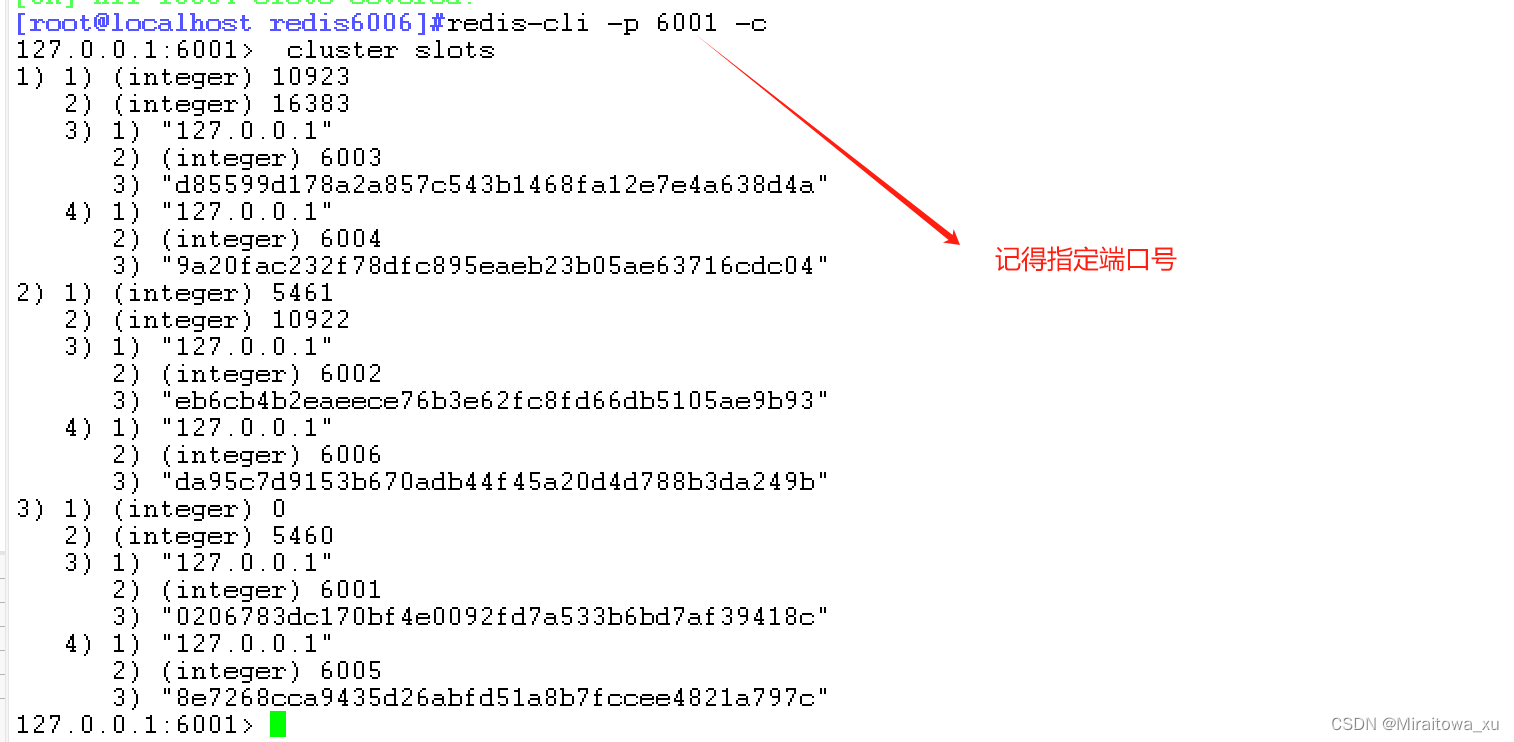
1.8 测试集群
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 54612) (integer) 10922 #哈希槽编号范围3) 1) "127.0.0.1"2) (integer) 6003 #主节点IP和端口号3) "fdca661922216dd69a63a7c9d3c4540cd6baef44"4) 1) "127.0.0.1"2) (integer) 6004 #从节点IP和端口号3) "a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 02) (integer) 54603) 1) "127.0.0.1"2) (integer) 60013) "0e5873747a2e26bdc935bc76c2bafb19d0a54b11"4) 1) "127.0.0.1"2) (integer) 60063) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
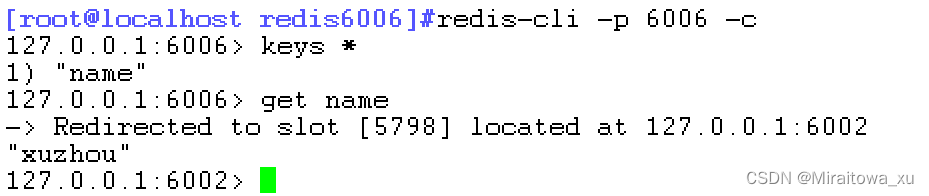
3) 1) (integer) 109232) (integer) 163833) 1) "127.0.0.1"2) (integer) 60023) "816ddaa3d1469540b2ffbcaaf9aa867646846b30"4) 1) "127.0.0.1"2) (integer) 60053) "f847077bfe6722466e96178ae8cbb09dc8b4d5eb"设置名字

对应的slave节点也有这条数据,但是别的节点没有s
总结
群集的作用:
- 解决因服务器容量不足以容纳用户大量的写请求。
- 高并发写导致单台服务器阻塞,进而导致性能瓶颈问题。
数据如何进行存储:
使用hash算法
16384hash槽
每一个槽位512字节