目录
一,数据分片
二,水平分片
三,创建数据库表
四,springboot项目导入依赖
五,创建类
六,bug
bug放到最后了。
一,数据分片
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。
除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
二,水平分片
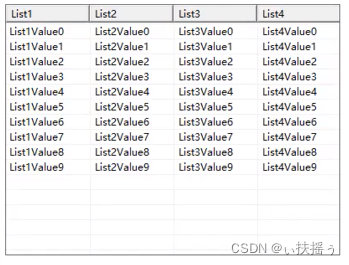
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。

三,创建数据库表
创建两个数据库,分别为ds00,ds01。两个库中分别放下面三张表。
CREATE TABLE `t_order_0` (`id` bigint(20) NOT NULL,`name` varchar(255) DEFAULT NULL COMMENT '名称',`type` varchar(255) DEFAULT NULL COMMENT '类型',`gmt_create` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;CREATE TABLE `t_order_1` (`id` bigint(20) NOT NULL,`name` varchar(255) DEFAULT NULL COMMENT '名称',`type` varchar(255) DEFAULT NULL COMMENT '类型',`gmt_create` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;CREATE TABLE `t_order_2` (`id` bigint(20) NOT NULL,`name` varchar(255) DEFAULT NULL COMMENT '名称',`type` varchar(255) DEFAULT NULL COMMENT '类型',`gmt_create` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;四,springboot项目导入依赖
全放上来了。
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- shardingsphere --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.2.0</version></dependency><!-- 驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency></dependencies>五,创建类
service层
public interface OrderService extends IService<Order> {
}@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
}entity层
@Data
@TableName("t_order")
public class Order {@TableId(type = IdType.AUTO)Long id;String name;String type;Date gmtCreate;
}多线程插入1kw条数据。
这里我想用线程池来着,但是不知道为啥就是插不进去。然后就只好用了其他写法。
@SpringBootTest
public class DemoApplicationTests {@AutowiredOrderService orderService;@Testpublic void testabs(){int num = 2000;CountDownLatch latch = new CountDownLatch(1);List<Order> orderList = new ArrayList<>();new Thread(() -> {for (long i = 1; i <= 10000000; i++) {Order order = new Order();order.setId(i);order.setName("xxx" + i);order.setType("xxx");order.setGmtCreate(new Date());orderList.add(order);}latch.countDown();}).start();try {latch.await();} catch (InterruptedException e) {}//2000条为一批,插入1000万条List<List<Order>> partition = Lists.partition(orderList, num);partition.stream().forEach(orders -> {orderService.saveBatch(orders);System.err.println("插入数据成功,rows:" + num);});}}
整个添加的过程时间有点长,大概是15分钟左右。
插入完成,查看数据库,他是按照id平均分布的,最终每张表数据量差不多是160w+

六,bug
Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required
这个是纯试出来的。
原因是我的pom.xml文件里有一个Druid的依赖,启动的时候一直启不起来,然后我把这个注掉,然后就没事了,看这篇博客shardingsphere+druid 报错roperty ‘sqlSessionFactory‘ or ‘sqlSessionTemplate‘ are required_shardingsphere property 'sqlsessionfactory' or 'sq-CSDN博客。
<!-- <dependency>-->
<!-- <groupId>com.alibaba</groupId>-->
<!-- <artifactId>druid-spring-boot-starter</artifactId>-->
<!-- <version>1.1.10</version>-->
<!-- </dependency>-->第二个就是在插入数据的时候,一直报插入匹配多个data nodes,可是并没有啊???
下面我自己写的批量插入的sql:
<!-- 批量插入 --><insert id="batchInsert" parameterType="list">insert into t_order (`name`,`type`,`gmt_create`)values <foreach collection="orderList" item="item" separator=",">(#{item.name},#{item.type},now())</foreach></insert>找半天我发现可能是,sql语句里面必须有指定分库分表的字段在里面,这个例子用的是id,那sql语句里面也得是有明确的id,然后我就在new的时候设置了他的id。然后暂时不报错了。
---o(╥﹏╥)o---