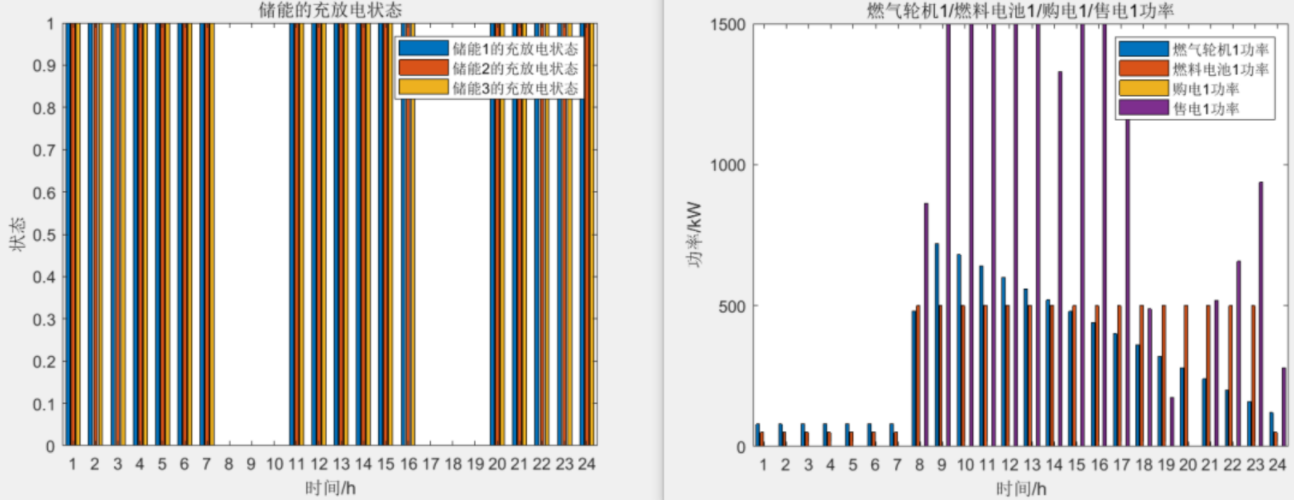
我们存储到ES中数据大致分为以下两种:
- 全文本,例如文章内容、通知内容
- 精确值,如实体Id
在对这两类值进行查询的时候,精确值类型会比较它们的二进制,其结果只有相等或者不想等。而对全文本类型进行等值比较是不太实现的,一般我们只会比较两个文本是否相似。根据上一讲的内容我们知道,要比较两个文本类型是否相似,使用相关性评分来评估的。而要得到相关性评分,我们就需要对全文本进行分词处理,然后得到统计数据才能进行评估
在es中,负责处理文本分词的是分词器,本文我们就来学习ES中分词器的组成和部分分词器的特性。
分词(Analysis)与分词器
分词是将全文本转换为一系列单词的过程,这些单词称为term或者token,而这个过程称为分词。
分词是通过**分词器(Analyzer)来实现的,**比如用于中文分词的IK分词器等。当然你也可以实现自己的分词器,例如可以简单将全文本以空格来实现分词。ES内置来一些常用的分词器,如果不能满足你的需求,你可以安装第三方的分词器或者定制化你自己的分词器。
**除了在写入的时候对数据进行分词,在对全文本进行查询的时候也需要使用相同的分词器对检索内存进行分析。例如,**查询Java Book的时候会分为java 和book两个单词,如下如所示: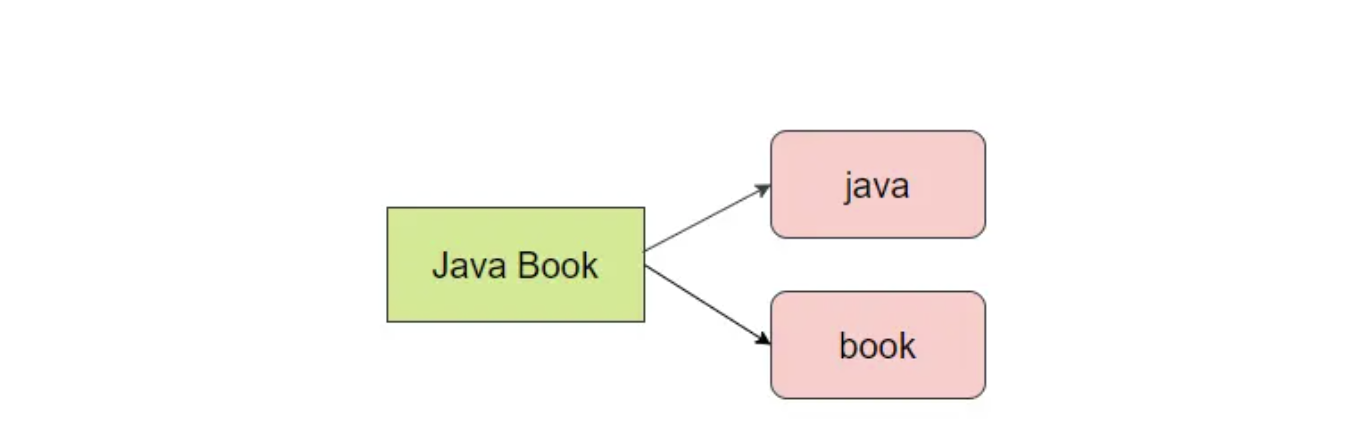
分词器的组成
分词器主要由 3 部分组成。
- Character Filter:注意对原文本进行格式处理,比如去除html标签
- Tokenizer:按照指定规则对文本进行切分,比如按空格来切分单词,同时页负责标记出每个单词的顺序、位置以及单词在原文本中开始和结束的偏移量
- Token Filter:对切分后的单词进行处理,如转换为小写、删除停顿词、增加同义词、词干化等
如下图就是分词器工作的流程,需要进行分词的文本依次通过Character Filter、Tokenizer、Token Filter,最后得出切分后的词项: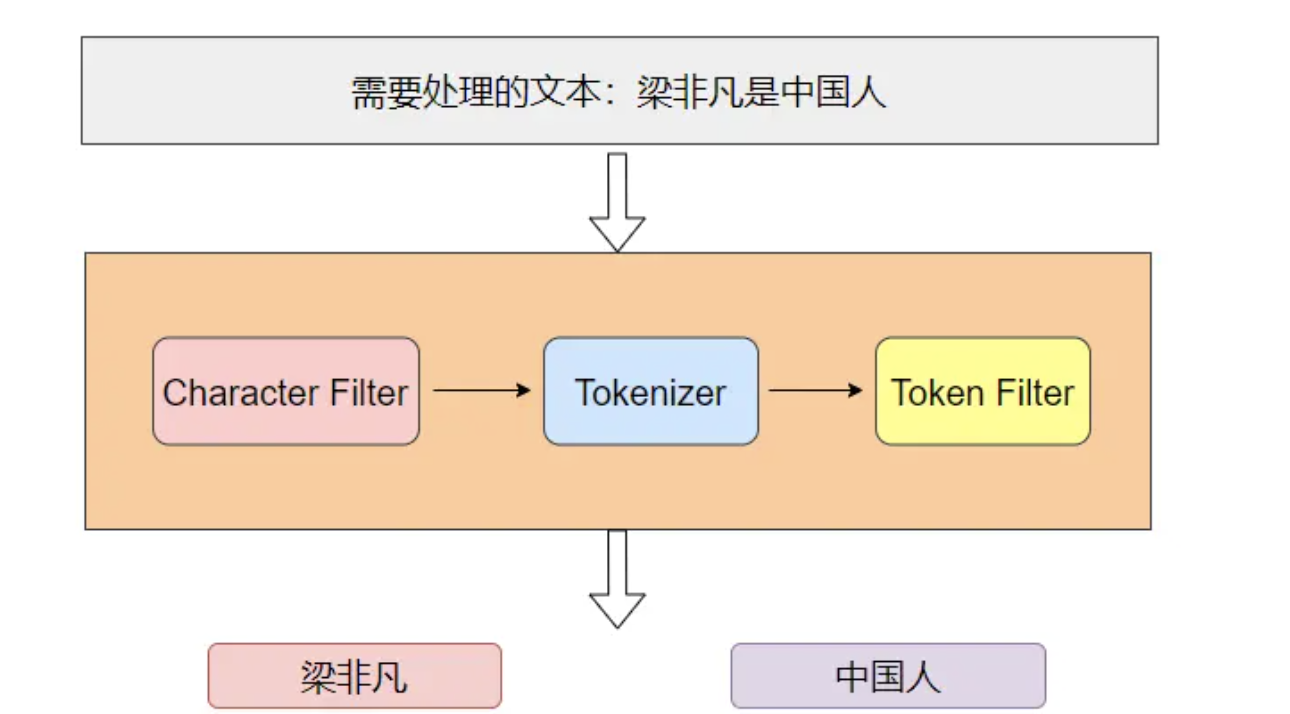
ES内置的分词器
为了方便用户使用,Es为用户提供了多个内置的分词器,常见的有以下8种。
- Standard Analyzer:这个是默认的分词器,使用Unicode文本分割算法,将文本按单词切分并且转换为小写
- Simple Analyzer:按照非字母切分并且进行小写处理
- Stop Analyzer:与 Simple Analyzer 类似,但增加了停用词过滤(如 a、an、and、are、as、at、be、but 等)。
- Whitespace Analyzer:使用空格对文本进行切分,并不进行小写转换
- Pattern n Analyzer;使用正则表达式切分,默认使用 \W+ (非字符分隔)。支持小写转换和停用词删除。
- Keyword Analyzer:不进行分词
- Language Analyzer:提供了多种常见语言的分词器。如 Irish、Italian、Latvian 等。
- Customer Analyzer:自定义分词器
下面我们通过讲解Standard Analyzer来进一步熟悉分词器的工作流程,但在这之前我要先介绍一个Es提供的API:_analyze。
_analyze Api是一个非常有用的工具,它可以帮助我们查看分词器是如何工作的。_analyze API 提供了 3 种方式来查看分词器是如何工作的。
- 使用 _analyze API 时可以直接指定 Analyzer 来进行测试,示例如下:
GET _analyze
{"analyzer": "standard","text": "Your cluster could be accessible to anyone."
}# 结果
{"tokens": [{"token": "your","start_offset": 0,"end_offset": 4,"type": "<ALPHANUM>","position": 0},{"token": "cluster","start_offset": 5,"end_offset": 12,"type": "<ALPHANUM>","position": 1}......]
}
如上示例,在这段代码中我们可以看到它将text的内容用standard分词器进行分词,text的内容按单词进行了切分并且your转为了小写。
- 对指定的索引进行测试,示例如下:
# 创建和设置索引
PUT my-index
{"mappings": {"properties": {"my_text": {"type": "text","analyzer": "standard" # my_text字段使用了standard分词器}}}
}GET my-index/_analyze
{"field": "my_text", # 直接使用my_text字段已经设置的分词器"text": "Is this déjà vu?"
}# 结果:
{"tokens": [{"token": "is","start_offset": 0,"end_offset": 2,"type": "<ALPHANUM>","position": 0},......]
}- 组合 tokenizer、filters、character filters 进行测试,示例如下:
GET _analyze
{"tokenizer": "standard", # 指定一个tokenizer"filter": [ "lowercase", "asciifolding" ], # 可以组合多个token filter# "char_filter":"html_strip", 可以指定零个Character Filter"text": "java app"
}从上面的示例可以看到,tokenizer使用了standard而token filter使用了lowercase和ascillfolding来对text的内容进行切分。用户可以组合一个tokenizer、零个或者多个token filter、零个或者多个character filter。
Standard Analyzer
Standard Analyzer 是 ES 默认的分词器,它会将输入的内容按词切分,并且将切分后的词进行小写转换,默认情况下停用词(Stop Word)过滤功能是关闭的。
可以试一下下面这个例子:
GET _analyze
{"analyzer": "standard", # 设定分词器为 standard"text": "Your cluster could be accessible to anyone."
}# 结果
{"tokens": [{"token": "your","start_offset": 0,"end_offset": 4,"type": "<ALPHANUM>","position": 0},{"token": "cluster","start_offset": 5,"end_offset": 12,"type": "<ALPHANUM>","position": 1} ......]
}如上示例,从其结果中可以看出,单词You做了小写转换,停用词be没有被去掉,并且返回结果里记录了这个单词在原文本中的开始偏移量、结束偏移以及这个词出现的位置
自定义分词器
除了使用内置的分词器外,我们还可以通过组合 Tokenizer、Filters、Character Filters 来自定义分词器。其用例如下:
PUT my-index-001
{"settings": {"analysis": {"char_filter": { # 自定义char_filter"and_char_filter": {"type": "mapping","mappings": ["& => and"] # 将 '&' 转换为 'and'}},"filter": { # 自定义 filter"an_stop_filter": {"type": "stop","stopwords": ["an"] # 设置 "an" 为停用词}},"analyzer": { # 自定义分词器为 custom_analyzer"custom_analyzer": {"type": "custom",# 使用内置的html标签过滤和自定义的my_char_filter"char_filter": ["html_strip", "and_char_filter"],"tokenizer": "standard",# 使用内置的lowercase filter和自定义的my_filter"filter": ["lowercase", "an_stop_filter"]}}}}
}GET my-index-001/_analyze
{"analyzer": "custom_analyzer","text": "Tom & Gogo bought an orange <span> at an orange shop"
}你可以在 Kibana 中运行上述的语句并且查看结果是否符合预期,Tom 和 Gogo 将会变成小写,而 & 会转为 and,an 这个停用词和这个 html 标签将会被处理掉,但 at 不会。
ES 的内置分词器可以很方便地处理英文字符,但对于中文却并不那么好使,一般我们需要依赖第三方的分词器插件才能满足日常需求。
中文分词器
中文分词不像英文分词那样可以简单地以空格来分隔,而是要分成有含义的词汇,但相同的词汇在不同的语境下有不同的含义。社区中有很多优秀的分词器,这里列出几个日常用得比较多的。
- analysis-icu是官方的插件,其将Lucene ICU module融入到es中。使用ICU函数库来处理提供处理Unicode的工具
- IK:支持自定义词典和词典热更新
- THULAC:其安装和使用官方文档中有详细的说明,本文就不再赘述了
analysis-icu分词器
analysis-icu 是官方的插件,项目在这里。ICU 的安装如下:
# 进入脚本目录,参见ES 简介和安装一节我们把es安装在ES/es_node1# 有3个节点的需要分别进入3个节点目录进行安装 !!!!!cd ES/es_node1bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-icu/analysis-icu-7.13.0.zip# 如果安装出错,并且提示你没有权限,请加上sudo:sudo bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-icu/analysis-icu-7.13.0.zipICU 的用例如下:
POST _analyze
{ "analyzer": "icu_analyzer","text": "Linus 在90年代开发出了linux操作系统"
}# 结果
{"tokens" : [......{"token" : "开发","start_offset" : 11,"end_offset" : 13,"type" : "<IDEOGRAPHIC>","position" : 4},{"token" : "出了","start_offset" : 13,"end_offset" : 15,"type" : "<IDEOGRAPHIC>","position" : 5},{"token" : "linux","start_offset" : 15,"end_offset" : 20,"type" : "<ALPHANUM>","position" : 6}......]
}通过在 Kibana 上运行上述查询语句,可以看到结果与 Standard Analyzer 是不一样的,同样你可以将得出的结果和下面的 IK 分词器做一下对比,看看哪款分词器更适合你的业务。更详细的 ICU 使用文档可以查看:ICU 文档
IK分词器
IK 的算法是基于词典的,其支持自定义词典和词典热更新。下面来安装 IK 分词器插件:
# 有3个节点的需要分别进入3个节点目录进行安装 !!!!!cd ES/es_node1# 如果因为没有权限而安装失败的话,使用sudo ./bin/elasticsearch-plugin install url 来安装./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.13.0/elasticsearch-analysis-ik-7.13.0.zip在每个节点执行完上述指令后,需要重启服务才能使插件生效。重启后,可以在 Kibana 中测试一下 IK 中文分词器的效果了。
POST _analyze
{ "analyzer": "ik_max_word","text": "Linus 在90年代开发出了linux操作系统"
}POST _analyze
{ "analyzer": "ik_smart","text": "Linus 在90年代开发出了linux操作系统"
}如上示例可以看到,IK 有两种模式:ik_max_word 和 ik_smart,它们的区别可总结为如下(以下是 IK 项目的原文)。
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌”,会穷尽各种可能的组合,适合 Term Query。
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、国歌”,适合 Phrase 查询。
关于 IK 分词器插件更详细的使用信息,你可以参考 IK 项目的文档。