文章目录
- 文本的tokenization
- 向量化
- 1.one-hot编码
- 2.word embedding
- 3.API
文本的tokenization
tokenization就是通常说的分词,分出的每一个词我们把它称为token。
常见的分词工具有很多,比如:
- jieba分词
- 清华大学的分词工具THULAC
中文分词的方法:
- 把句子转化为词语
- 把句子转化为单个字
向量化
因为文本不能够直接被模型计算,所以需要将其转化为向量。
把文本转化为向量有两种方法:
①转化为one-hot编码
②转化为word embedding
1.one-hot编码
在one-hot编码中,每一个token使用一个长度为N的向量表示,N表示为词典的数量。
即:把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典,假设我们有一个文档:”深度学习“,那么进行one-hot处理后的结果如下:
| token | one-hot encoding |
|---|---|
| 深 | 1000 |
| 度 | 0100 |
| 学 | 0010 |
| 习 | 0001 |
补充:
-
句子可以切分为单个字、词来表示,但是有时候也可以切分为2个、3个或者多个词来表示,N-gram就是按n个词语划分文本的方法,其中N表示能够被一起使用的词的数量。
-
在传统的机器学习中,使用N-gram方法往往能够取得非常好的效果,但是在深度学习中比如RNN中会自带N-gram的效果。
2.word embedding
word embedding是深度学习中表示文本常用的一种方法,和one-hot编码不同。word embedding使用了浮点型的稠密矩阵来表示token。根据词典大小,我们的向量通常使用不同的维度,例如100,260,300等。其中,向量中的每一个数都是一个超参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
假设我们的文本中有20000个词语,如果使用one-hot编码,那么我们会有20000 * 20000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000 * x维度,如果维度x为300的话,得到的矩阵大小就是20000 * 300
形象的表示就是:
| token | num | vector |
|---|---|---|
| 词1 | 0 | [w11,w12,w13…w1n],其中n表示维度 |
| 词2 | 1 | [w21,w22,w23…w2n] |
| 词3 | 2 | [w31,w32,w33…w3n] |
| … | … | … |
| 词m | m | [wm1,wm2,wm3…wmn],m表示词典的大小 |
注:我们会把所有的文本转化为向量,把句子用向量表示,但是在这中间,我们会先把token使用数字来表示,再把数字使用向量来表示。即:token—>num—>vector
举个栗子:
比如我们现在有一句话“欢迎来到深度学习”,根据这句话我们可以创建一个词典(如果是预训练好的模型,那词典是基于预训练语料库创建好的)
假如词典如下:
| token | index |
|---|---|
| 到 | 0 |
| 欢 | 1 |
| 度 | 2 |
| 来 | 3 |
| 深 | 4 |
| 学 | 5 |
| 习 | 6 |
| 迎 | 7 |
“欢迎来到深度学习”这句话对应的tokens是[“欢”,“迎”,“来”,“到”,“深”,“度”,“学”,“习”],对应词表得到的数字表示为[1,7,3,0,4,2,5,6],然后给定词向量维度N进行训练,每个词(字)都可以用一个维度为N的向量表示,这句话有8个字,那么这句话最终可以用一个8xN的矩阵表示
3.API
torch.nn.Embedding(num_embeddings,embedding_dim)
参数介绍:
①num_embeddings:词典的大小(数量)
②embedding_dim:embedding的维度
使用方法:
embedding = nn.Embedding(vocab_size,300) #实例化
input_embeded = embedding(input) #进行embedding的操作,input是要进行词嵌入的文本
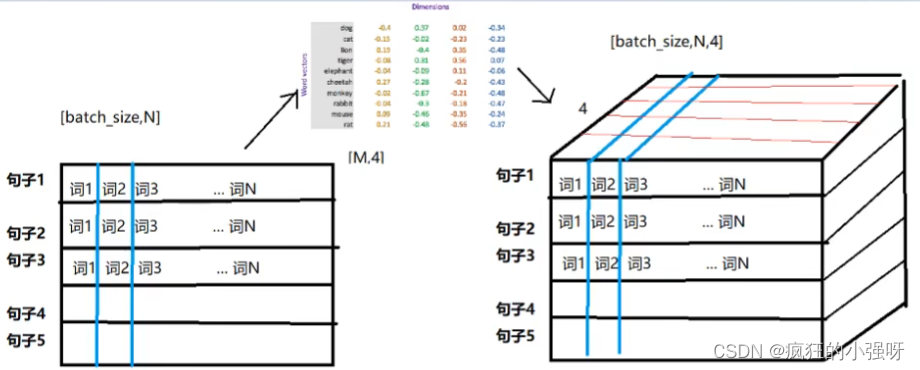
思考:每个batch中的每个句子有10个词,经过形状为[20,4]的word embedding之后,原来的句子会变成什么形状?
每个词语用长度为4的向量表示,所以,最终句子会变为[batch_size,10,4]的形状。
增加了一个维度,这个维度就是embedding的dim。