Java 源码解析,集合篇
- 一:故事背景
- 二:数据结构
- 2.1 线性结构
- 2.2 非线性结构
- 三:集合分类
- 3.1 结构图
- 四:详细分析
- 4.1 List
- 4.1.1 ArrayList
- 4.1.1.1 底层结构
- 4.1.1.2 主要特点
- 4.1.2 LinkedList
- 4.1.2.1 底层结构
- 4.1.2.2 主要特点
- 4.1.3 Vector和Stack
- 4.1.3.1 Vector
- 4.1.3.1 Stack
- 五:总结提升
一:故事背景
本文讲解的源码如未经特殊说明,均JDK1.8为准
- 不知道大家是否听过这么一句话。程序=算法+数据结构。算法指的是解决问题或者指定任务的步骤和规则的有序集合。而数据结构指的是组织和存储数据的方式。
- 大家可能学过数据结构,可能也经常会使用Java中的集合类。可这些集合类的源码,你真的研究过吗?这篇文章会带着你去学习Java中常用的集合类。从宏观到微观的方式,从使用到源码的方式,带你深入理解Java各个集合类的源码,让你不仅能用集合类,更能用好,能自己去创造集合类。
二:数据结构
想要理解Java中集合类底层使用的数据结构,就要先了解有什么数据结构。本篇文章我们不多做解释,将常见数据结构以及概念罗列,为我们下面分析Java集合源码做铺垫。
我将数据结构分为了两类,分别是线性结构和非线性结构。
2.1 线性结构
线性结构是一种简单的数据结构,其中数据元素之间存在一对一的关系,即每个元素有且只有一个直接前驱和一个直接后继元素,除了第一个元素没有前驱,最后一个元素没有后继。
- 数组(Array):一组连续存储的数据元素,通过索引访问元素,具有固定大小。
- 链表(Linked List):由节点组成的数据结构,每个节点包含数据和指向下一个节点的引用。
- 栈(Stack):一种具有后进先出(Last-In-First-Out,LIFO)特性的数据结构,只能在栈顶进行插入和删除操作。
- 队列(Queue):一种具有先进先出(First-In-First-Out,FIFO)特性的数据结构,只能在队列的一端插入,在另一端删除。
2.2 非线性结构
非线性结构是指数据元素之间存在多对多的关系,即一个元素可以有多个前驱和后继元素,或者存在层次关系,不像线性结构那样简单的一维排列。
- 树(Tree):由节点组成的层次结构,每个节点可以有多个子节点,但每个节点只有一个父节点。
- 图(Graph):由节点(顶点)和边组成,节点之间的关系可以是任意的,可以是双向的,形成复杂的网络结构。
- 堆(Heap):一种特殊的树结构,常用于优先队列的实现,有最大堆和最小堆两种形式。
三:集合分类
上文讲了常见的数据结构有这么多,那么Java中的集合类都有哪些呢?每个类使用了那种,那几种数据结构呢?今天我们就一起来盘一盘。
3.1 结构图
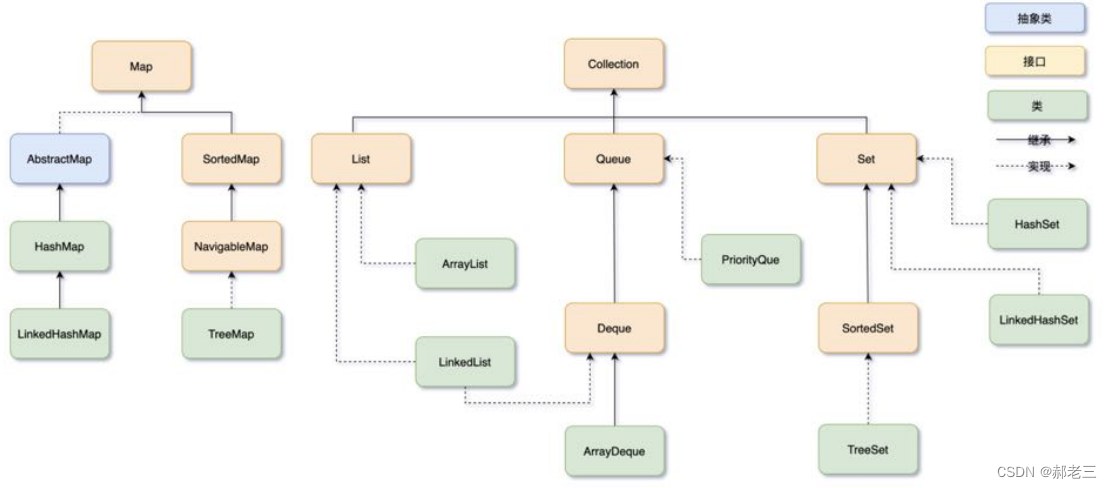
Java集合框架主要分为了两类:
- 以键值对为首的Map类型,其中典型代表为 HashMap
- 以Collection(收集、聚集)结构为首的。主要有List、Set、Queue、组成。其中List典型代表为 ArrayList和LinkedList、Set代表为HashSet、Queue代表为双端队列ArrayDeque与优先级队列PriorityQueue
四:详细分析
其实这些集合类主要的功能就是用来盛放数据。既然是用来盛放数据那就好办了。
- 应用层面:我们可以在 增、删、改、查、的四个角度,分析这些不同。
- 底层层面:我们可以结合数据结构,分析不同的集合类使用的数据结构,结合这些结构的特点,分析这些不同集合类的效率。
接下来的讲解中,我们不会对各个集合类的增删改查的用法多做研究,而是主要从数据结构与主要特点两个方面进行讲解,更多的从源码、从设计的角度去学习这些集合类。
4.1 List
List 的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作。
4.1.1 ArrayList
4.1.1.1 底层结构
ArrayList的底层是由数组进行实现的,其内部维护了一个Object类型的数组,数据实际是存在此数组内。
无参构造:
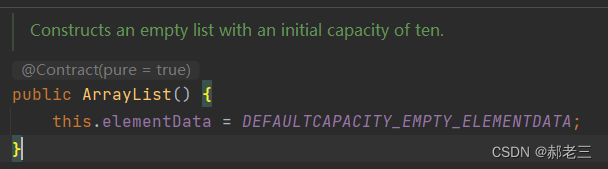
这里的elementData就是用来存储数据的底层数组:
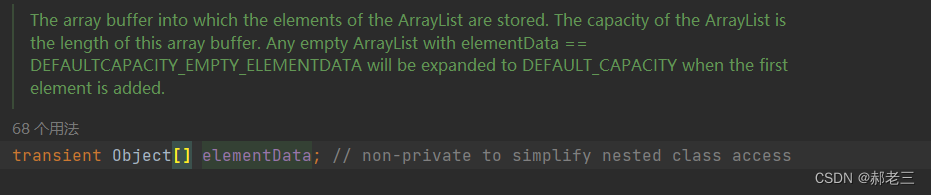
而DEFAULTCAPACITY_EMPTY_ELEMENTDATA是初始化数组的时候的默认值,默认是空。

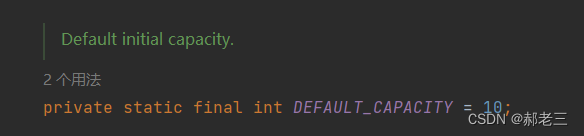
这里大家可能有点小疑问,不对啊,之前我听说ArrayList的默认容量是10,怎么你这里说是空呢。这里就要提到其另外一个特点:
ArrayList是懒加载的,在第一次进行插入数据的时候,才会去开辟空间:
具体怎么扩容,我们放在下面主要特点里去分析。
4.1.1.2 主要特点
-
底层由数组实现,支持随机存取(通过下标直接存取)
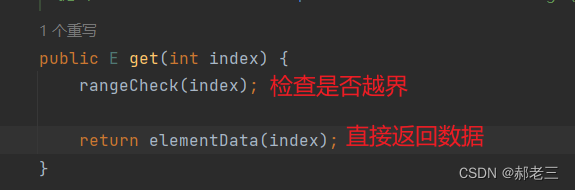
上文我们已经看了ArrayList底层的数组,数组的特点就是支持随机存取,取出数据的时间复杂度为O1。这里我们可以看看ArrayList的获取数据的方法:
-
从尾部插入删除元素最快,中间插入删除较慢,头部插入删除最慢。
这个特点也与数组的特点有关,由于数组是按照顺序存储的,所以在插入或者删除数据的时候,必须要将插入或者删除位置之后的数组进行移动。数组长度固定的情况下,操作的数组越靠前,需要移动的数据就越多。 -
内部数组容量不足时会自动扩容,元素量非常大的时候,效率较低。
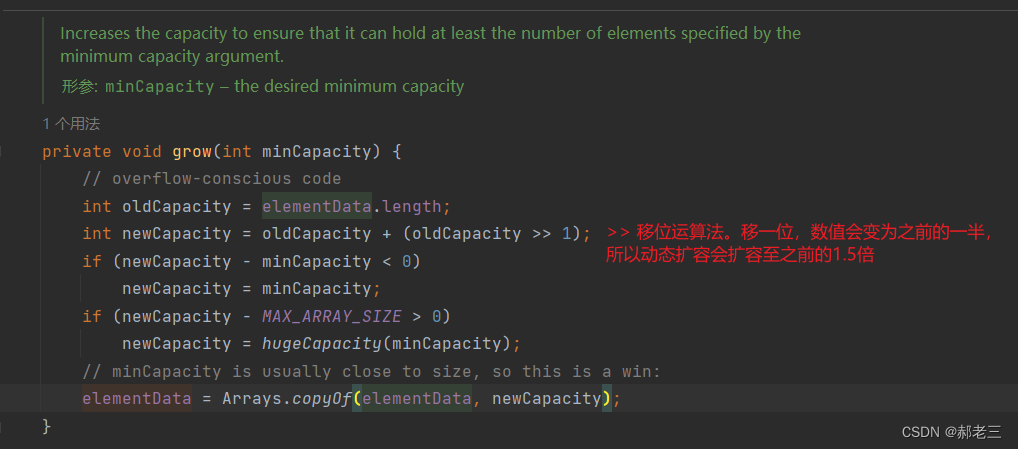
自动扩容机制,是ArrayList的一个重要特点。每次插入数据的时候都会去检查是否需要扩容,并且扩容为原来容量的1.5倍。
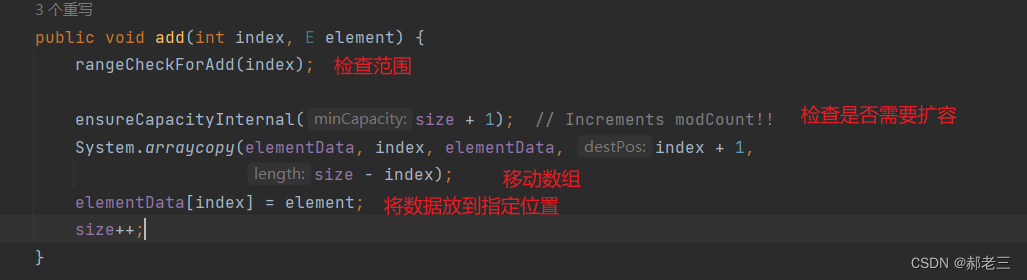
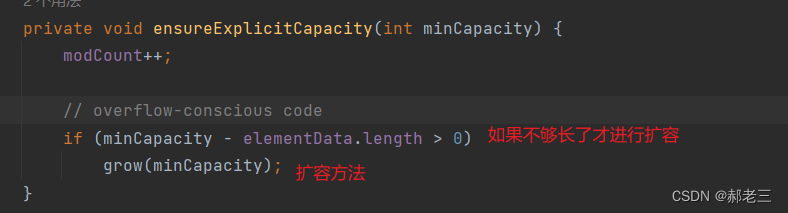
我们主要看检查是否需要扩容这部分
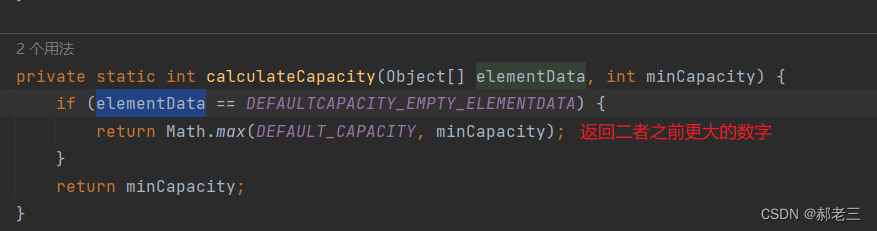
 calculateCapacity方法内部,就是用来检查当前elementData 是否为空,决定是不是要设置为初始容量,这里验证了我们上文所说,只有在第一次Add的时候才会进行实际创建空间。
calculateCapacity方法内部,就是用来检查当前elementData 是否为空,决定是不是要设置为初始容量,这里验证了我们上文所说,只有在第一次Add的时候才会进行实际创建空间。
判断是否需要扩容以及扩容的详细逻辑:
4.1.2 LinkedList
4.1.2.1 底层结构
LinkedList的底层是一个双向链表结构。通过前后指针维护数据之间的相互关系。其是通过一个内部类进行实现的,内部类里存放了具体的数据,并且维护了前后指针。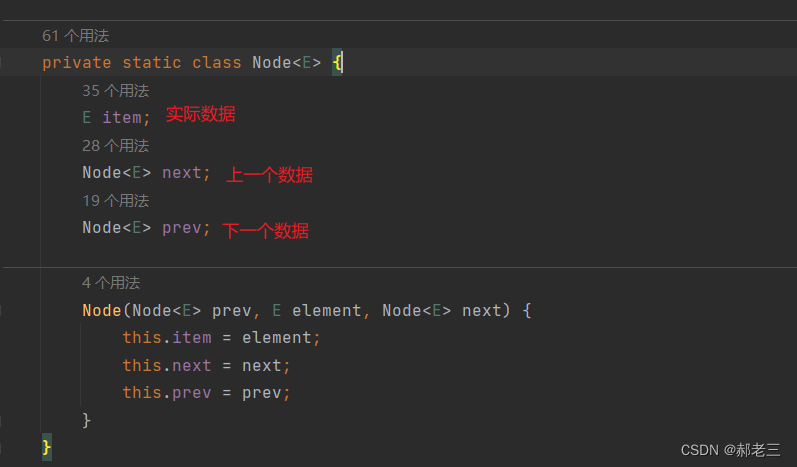
4.1.2.2 主要特点
-
双向链表结构,无法随机存取,只能从一端开始遍历
双向链表的结构,我们上文已经讲过了,在数据上增加前后指针,使得可以通过指针相互找到。这样的话,在计算机里进行存储就无需逻辑顺序与物理顺序一致。无法随机存取。链表想要在拿到指定位置的数据的话,必须要通过指针进行遍历,找到对应数据所在位置。
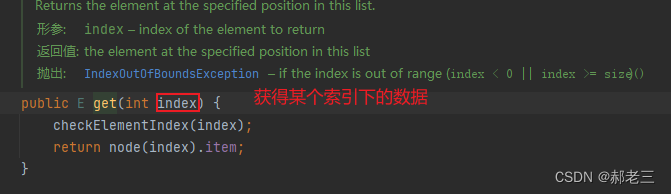
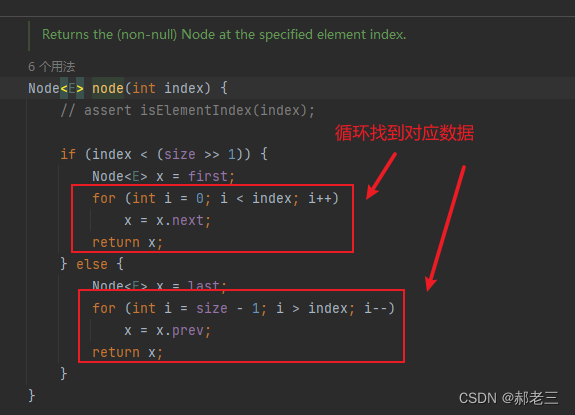
这里LinkedList做了一个优化,传入索引之后,其不会直接从头开始遍历,而是判断其是存在于前半区,还是后半区。如果在前半区就从前半部分向后开始遍历,后半区从后半区向前遍历。也就是说LinkedList查找在中间部分的数据效率最低 -
任意位置插入和删除元素非常方便,只需改变应用即可
需要注意的是,我们这里说的任意位置,是在确定位置的基础上的,找到对应位置,还是无法避免循环。但是与ArrayList相比,LinkedList找到之后,只需要调整前后指针,替换数据即可,不涉及到数据的批量移动。
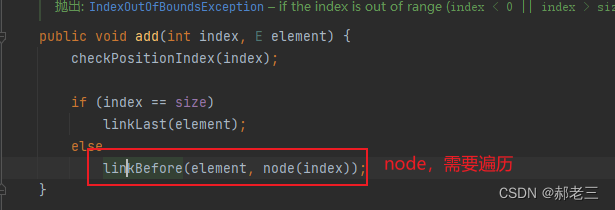
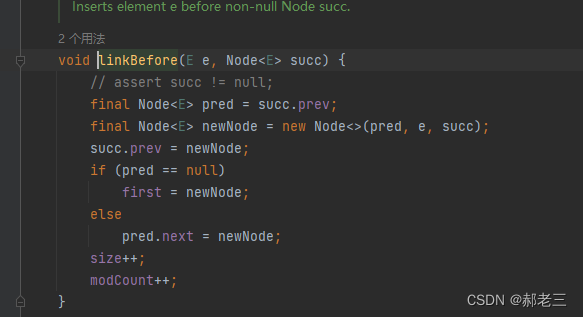
找到数据之后,调整指针与具体数据即可。 -
需要更多的空间存储上一个节点和下一个节点的引用
这个就比较容易理解了,因为LinkedList增加了前后指针,指向前后的数据,这些指针会占用额外的存储空间。正是这些指针体现了链表的这种特性。
4.1.3 Vector和Stack
4.1.3.1 Vector
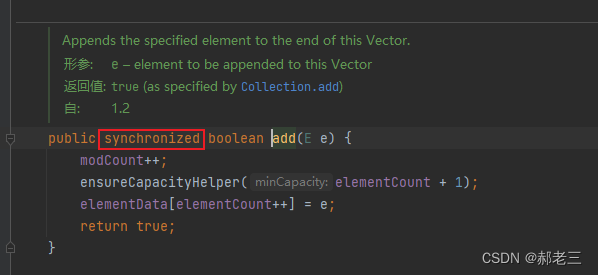
List 的实现类还有一个 Vector,是一个元老级的类,比 ArrayList 出现得更早。ArrayList 和 Vector 非常相似,只不过 Vector 是线程安全的,像 get、set、add 这些方法都加了 synchronized 关键字,因为synchronized锁属于重量级锁,会阻塞其它线程,导致执行执行效率会比较低,所以现在已经很少用了
4.1.3.1 Stack
Stack 是 Vector 的一个子类,本质上也是由动态数组实现的,只不过还实现了先进后出的功能(在 get、set、add 方法的基础上追加了 pop「返回并移除栈顶的元素」、peek「只返回栈顶元素」等方法),所以叫栈。
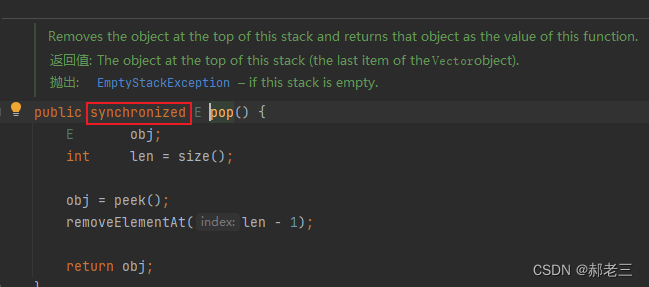
这些我们就不在深入探讨。在实际项目的使用中,如何设计到并发情况下的线程安全问题,关于List,Java提供了线程安全的并发集合容器类CopyOnWriteArrayList。关于这部分,我会出一个详细文章与锁相结合进行讲解,总结。
五:总结提升
本文讲解了重点的集合框架,从源码的层面和数据结构的层面进行了详细分析,通过本文的学习,希望大家对集合框架有一个细致的了解。接下来我会更新常用的并发容器,结合多线程的知识进行分析。