Softmax 函数
softmax 函数是一种激活函数,通常用作神经网络最后一层的输出函数。该函数是两个以上变量的逻辑函数的推广。
Softmax 将实数向量作为输入,并将其归一化为概率分布。 softmax函数的输出是与输入具有相同维度的向量,每个元素的范围为0到1。并且所有元素的总和等于1。
在数学上,我们将 softmax 函数定义为:
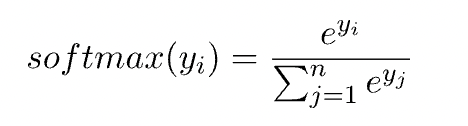

带有温度系数的Softmax函数
术语“softmax”来自“soft”和“max”这两个词。 “soft”部分表示该函数产生的概率分布比硬最大值函数更软。 “max”部分意味着它将选择输入向量中的最大值作为最可能的选择,但以软概率的方式。
例如,如果我们有一个输入向量 (0.4, 0.4, 0.5),则硬极大值函数将输出向量 (0, 0, 1)。相反,softmax 函数的输出将为 (0.32, 0.32, 0.36)。
在softmax函数中引入温度参数来控制输出概率分布的“softness”或“peakiness”。温度是我们用来控制函数输出的随机性水平的参数。在数学上,具有温度参数 T 的 softmax 函数可以定义为:
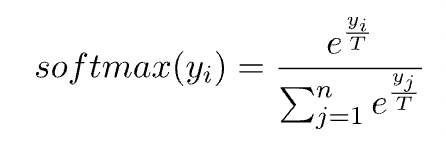
温度参数T可以取任意数值。当 T=1 时,输出分布将与标准 softmax 输出相同。 T的值越高,输出分布就会变得越“软”。例如,如果我们希望增加输出分布的随机性,我们可以增加参数T的值。
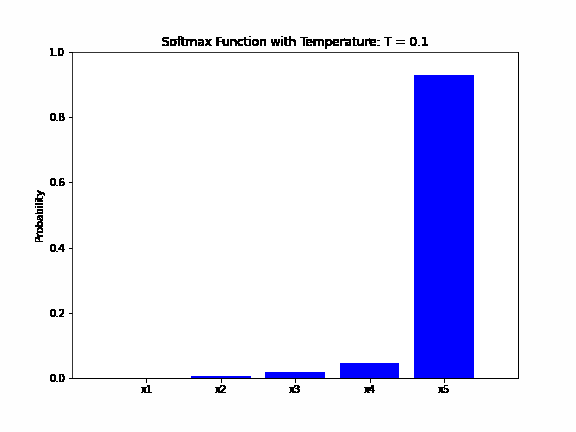
下面的动画展示了softmax函数的输出概率如何随着温度参数的变化而变化。输入向量为(0.1,0.4,0.5,0.6,0.9),温度从0.1变化到2,步长为0.1:
为什么在 Softmax 中使用温度
当我们想要在输出分布中引入更多随机性或多样性时,温度会很有用。这在用于文本生成的语言模型中特别有用,其中输出分布表示下一个单词标记的概率。如果我们的模型经常过于自信,它可能会产生非常重复的文本。
例如,温度是 GPT-2、GPT-3、BERT 等语言模型中使用的超参数,用于控制生成文本的随机性。当前版本的 ChatGPT(gpt-3.5-turbo 模型)也使用带有 softmax 函数的温度。
ChatGPT 拥有 175,000 个子词的词汇表,与 softmax 函数的输入和输出向量的维度数相同。 softmax 函数输出中的每个维度对应于词汇表中特定单词作为序列中下一个单词的概率。因此,ChatGPT API 有一个温度参数,可以取 0 到 2 之间的值来控制生成文本的随机性和创造性。默认值为 1。
在openAI的playground中,温度系数的定义和取值范围(0-2)
https://platform.openai.com/playground/chat

OpenAI原始对于温度(Temperature)参数说明:
temperature:number or null,Optional,Defaults to 1
What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
We generally recommend altering this or top_p but not both.其它
通过softmax函数得到的所有token的概率分布,怎么选择其中一个token(或者说单词),通常有以下几种常用的方法:
- 贪心解码(Greedy Decoding):直接选择概率最高的token(单词)。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。
- 随机采样(Random Sampling):按照概率分布随机选择一个token(单词)。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
- Beam Search:维护一个大小为 k 的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的 k 个token(单词),然后保留总概率最高的 k 个候选序列。这种方法可以平衡生成的质量和多样性,但是可能会导致生成的文本过于保守和不自然。
以上方法都有各自的问题,而 top-k 采样和 top-p 采样是介于贪心解码和随机采样之间的方法,也是目前大模型解码策略中常用的方法。
Top k采样
Top-k 采样是对前面“贪心策略”的优化,它从排名前 k 的 token 中进行抽样,允许其他分数或概率较高的token 也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
top-k 采样的思路是,在每一步,只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。例如,如果 k=2,那么我们只从女孩、鞋子中选择一个单词,而不考虑大象、西瓜等其他单词。这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
下面是 top-k 采样的例子:

Top p 采样

top-k 有一个缺陷,那就是“k 值取多少是最优的?”非常难确定。于是出现了动态设置 token 候选列表大小策略——即核采样(Nucleus Sampling)。
top-p 采样的思路是,在每一步,只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的单词。这种方法也被称为核采样(nucleus sampling),因为它只关注概率分布的核心部分,而忽略了尾部部分。例如,如果 p=0.9,那么我们只从累积概率达到 0.9 的最小单词集合中选择一个单词,而不考虑其他累积概率小于 0.9 的单词。这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
下图展示了 top-p 值为 0.9 的 Top-p 采样效果:

top-p 值通常设置为比较高的值(如0.75),目的是限制低概率 token 的长尾。我们可以同时使用 top-k 和 top-p。如果 k 和 p 同时启用,则 p 在 k 之后起作用。
频率惩罚和存在惩罚 Frequency and Presence Penalties
最后,让我们来讨论本文中的最后两个参数:频率惩罚和存在惩罚(frequency and presence penalties)。令人惊讶的是,这些参数是另一种让模型在质量和多样性之间进行权衡的方法。然而,temperature 参数通过在token选择(token sampling)过程中添加随机性来实现输出内容的多样性,而频率惩罚和存在惩罚则通过对已在文本中出现的token施加惩罚以增加输出内容的多样性。这使得对旧的和过度使用的token进行选择变得不太可能,从而让模型选择更新颖的token。
频率惩罚(frequency penalty)让token每次在文本中出现都受到惩罚。这可以阻止重复使用相同的token/单词/短语,同时也会使模型讨论的主题更加多样化,更频繁地更换主题。另一方面,存在惩罚(presence penalty)是一种固定的惩罚,如果一个token已经在文本中出现过,就会受到惩罚。这会导致模型引入更多新的token/单词/短语,从而使其讨论的主题更加多样化,话题变化更加频繁,而不会明显抑制常用词的重复。
就像 temperature 一样,频率惩罚和存在惩罚(frequency and presence penalties)会引导我们远离“最佳的”可能回复,朝着更有创意的方向前进。然而,它们不像 temperature 那样通过引入随机性,而是通过精心计算的针对性惩罚,为模型生成内容增添多样性在一些罕见的、需要非零 temperature 的任务中(需要对同一个提示语给出多个答案时),可能还需要考虑将小的频率惩罚或存在惩罚加入其中,以提高创造性。但是,对于只有一个正确答案且您希望一次性找到合理回复的提示语,当您将所有这些参数设为零时,成功的几率就会最高。
一般来说,如果只存在一个正确答案,并且您只想问一次时,就应该将频率惩罚和存在惩罚的数值设为零。但如果存在多个正确答案(比如在文本摘要中),在这些参数上就可以进行灵活处理。如果您发现模型的输出乏味、缺乏创意、内容重复或内容范围有限,谨慎地应用频率惩罚或存在惩罚可能是一种激发活力的好方法。但对于这些参数的最终建议与 temperature 的建议相同:在不确定的情况下,将它们设置为零是一个最安全的选择!
需要注意的是,尽管 temperature 和频率惩罚/存在惩罚都能增加模型回复内容的多样性,但它们所增加的多样性并不相同。频率惩罚/存在惩罚增加了单个回复内的多样性,这意味着一个回复会包含比没有这些惩罚时更多不同的词语、短语、主题和话题。但当你两次输入相同的提示语时,并不意味着会更可能得到两个不同的答案。这与 temperature 不同, temperature 增加了不同查询下回复的差异性:在较高的 temperature 下,当多次输入相同的提示语给模型时,会得到更多不同的回复。
我喜欢将这种区别称为回复内多样性(within-response diversity)与回复间多样性(between-response diversity)。temperature 参数同时增加了回复内和回复间的多样性,而频率惩罚/存在惩罚只增加了回复内的多样性。因此,当我们需要增加回复内容的多样性时,参数的选择应取决于我们需要增加哪种多样性。
简而言之:频率惩罚和存在惩罚增加了模型所讨论主题的多样性,并使模型能够更频繁地更换话题。频率惩罚还可以通过减少词语和短语的重复来增加词语选择的多样性。
总结
提高 temperature 可以增加多样性但会降低质量。top-p 和 top-k 可以在不损失多样性的前提下提高质量。frequency penalty 和 presence penalty 可以增加回复的词汇多样性和话题多样性。
将参数设为零的规则:
temperature:
- 对于每个提示语只需要单个答案:零。
- 对于每个提示语需要多个答案:非零。
频率惩罚和存在惩罚:
- 当问题仅存在一个正确答案时:零。
- 当问题存在多个正确答案时:可自由选择。
Top-p/Top-k:
- 在 temperature 为零的情况下:输出不受影响。
- 在 temperature 不为零的情况下:非零。
如果您使用的语言模型具有此处未列出的其他参数,将其保留为默认值始终是可以的。
当参数非0时,参数调整的技巧:
先列出那些应该设置为非零值的参数,然后去 playground 尝试一些用于测试的提示语,看看哪些效果好。但是,如果上述规则说要将参数值保持为零,则应当将其保持为零!
参考
大模型文本生成——解码策略(Top-k & Top-p & Temperature)