传统人工智能 模型往往依赖大量有标签数据的监督训练,而且一个模型一般只能解决一个任务,仅适用于单一场景, 这使得人工智能的研发和应用成本高,场景适应能力弱,难以规模化应用。
常见的多模态任务大致可以分为两类:
- 多模态理解任务,如视频 分类、视觉问答、跨模态检索、指代表达等;
- 多模 态生成任务[1],如以文生图和视频、歌词生成音乐、 基于对话的图片编辑等。
多模态大模型的关键技术大致包括以下四部分 (图1):
- 大规模预训练数据
- 模型架构设计
- 自监督学习任务设计
- 下游任务适配
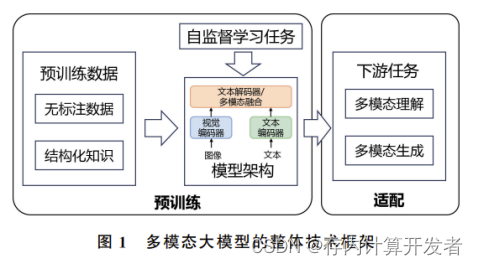
把一个已经训练好的图像分类[1] 模型的参数应用到另一个类似任务上作为初始参数,类似这样训练模型的过程称作预训练。
单流式多模态预训练模型
1,VideoBERT模型
VideoBERT 模型[5] 是一个在 BERT 模型的基础上捕捉语 言和视觉领域的结构,也是一个视频和语言表征学习的联合 模型。由于大多数视频包含同步的音频和视频信号,这两种 模态可以相互监督,以学习强自监督的视频表示[39] ,该模型 的结构如图 5 [5] 所示,其中 T表示 token。
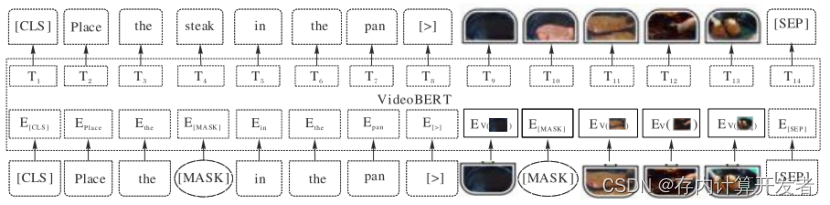
VideoBERT模型结构
2,HERO模型
HERO (Hierarchical EncodeR for Omnirepresentation learning)模型[41] 在分层结构中编码多模态输入,其中视频帧 的局部上下文由跨模态 Transformer 通过多模态融合捕获,而 全局视频上下文由时间 Transformer 捕获。它将视频剪辑的 帧和字幕句子的文本标记作为输入,再将它们送入视频嵌入 器和文本嵌入器,以提取初始表示。
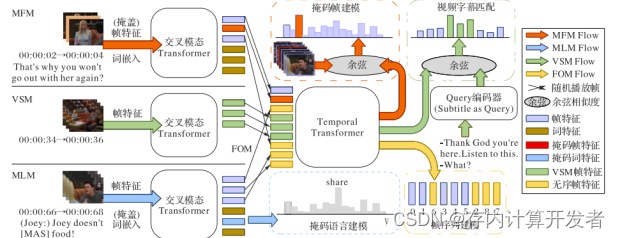
HERO模型
3.VL-BERT
VL-BERT 模型基于 Transformer 模型,以视觉和语言的嵌 入特征作为输入,对于每个输入元素,主要由 4 个嵌入层组 成,分别为标记嵌入、视觉特征嵌入、片段嵌入以及序列位置 嵌入。标记嵌入层主要是为每个特殊的元素分配特殊的标 记,即为每个视觉元素分配一个[IMG]标记。
VL-BERT 预训练模型通 过对视觉语言信息调整可应用于更多的下游任务,并在视觉 常识推理(Visual Commonsense Reasoning, VCR)任务上预训 练效果较为明显,广泛应用于视觉‒语言任务。
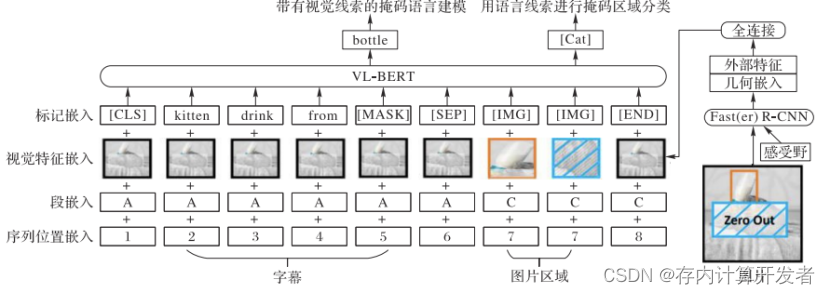
VL-BERT模型
4,ImageBERT
ImageBERT 基于 Transformer 模型,使用图像视觉标记和 文本标记作为输入,并对它们之间的关系建模,常用于图 像‒文本联合嵌入。其中,图像视觉标记是从 Faster R-CNN 模型[26] 中提取的 RoI 特征,将这些嵌入信息输入到一个多层 双向自注意力 Transformer 中,学习跨模态 Transformer 模拟视 觉区域和语言标记之间的关系[21] 。I
多模态理解
- 在多模态理解上,主要有以下几个关键进 展:
- 一 是 模 型 体 量 和 训 练 数 据 量 持 续 增 大,如 Flamingo [4]模型达到了80B 的参数量,GIT [5]模型 使用了10B级的预训练数据;
- 二是模态更丰富,如 VALOR [6]联合建模了图像、视频、文本与音频四个 模态,ImageBind [7]通过以视觉为中心进行对比学习 来连接文本、音频、视觉、红外、惯性测量单元(IMU) 信号等 六 种 模 态;
- 三 是 所 支 持 的 任 务 更 多 样,如 OFA [8]联合 建 模 了 多 种 理 解 与 生 成 任 务 (视 觉 问 答、图像生成、图像描述、文本任务、目标检测等);
- 四 是强化面向开放世界的细粒度感知,如 GLIPv2 [9]可 以实现开放词表的目标检测;
- 五是对接大语言模型 并增加指令学习,如 LLaVA [10]构造指令微调数据 集来训练大模型遵循人类指令的能力。
(2)在多模态生成上,主要进展总结为以下四 个方面:首先,近期涌现了许多大型预训练生成模 型,如 StableDiffusion [11]和 Google 的 Imagen [12] 等,它们能够基于简单的语言描述生成几乎以假乱 真的图像,实现了前所未有的生成质量和泛化能力。 其次,跨模态表示学习逐渐成为多模态生成领域的 研究重点之一,其中,CoDi [13]采用桥接对齐的方式 同时学习文本、图像、视频和音频等多种模态的表 示,为模型提供了更强大的多模态理解能力。第三, 同时融合多种生成任务能力于一体的模型开始涌 现,例如,UniDiffuser [14]基于扩散模型同时建模文 本生成图像、图像生成文本和图像文本对生成等多 项任务,NUWA [15]基于序列生成模型完成文本生成 图像、文本生成视频以及图像生成视频等多种生成 任务的建模。最后,多模态生成大模型的应用领域 也不断扩展到图像视频编辑、分子图生成、三维图像 生成以及数据增强等领域。这些进展为多模态生成 技术在解决各种现实世界问题中的应用提供了新的 机遇和潜力。 多模态大模型在多模态理解与生成上的进展进 一步支撑起了多模态交互技术的广泛应用,能够与 人类或外部环境等对象进行基于多模态输入、输出 的多轮互动交互,包括交互式多模态问答对话、交互 式内容编辑、多模态环境下的交互式决策等。得益 于在这些多模态理解、生成和交互任务上展现的强 大能力和突破性进展,多模态大模型能够支撑非常广泛的应用场景。
GPT-4的技术特性
从 GPT-1开始,OpenAI通过逐步扩大模型和 数据规模,不断优化其 GPT 系列的语言模型,推动 了人工智能技术的演进和升级(图2)。GPT-1首先 仅利用 Transformer的解码器并通过大量无标注数 据进行自监督预训练,然后通过有监督微调来解决 不同的下游任务,大大减少了任务之间的迁移困难。 GPT-2进一步扩大了模型和参数规模,尽管表现出 一定 的 通 用 性,但 仍 受 限 于 其 性 能 边 界。 随 后, GPT-3的问 世 突 破 了 之 前 版 本 的 限 制,通 过 使 用 1750亿参数规模的模型和45TB的数据量,即使无 需任何微调,也能够仅通过提示或少数样例完成多 种任务,展示出惊人的通用性。OpenAI进一步提 出了InstructGPT [16]模型,通过结合有监督的指令微 调和人类反馈的强化学习方式,实现了模型的自我优 化 和 更 新,更 好 地 遵 循 用 户 的 意 图 和 需 求。而 ChatGPT则是基于 GPT-3.5,结合了InstructGPT 的 训练方式,并加入更丰富的数据类型(如代码和思维 链数据)进行训练,从而拥有更强的逻辑推理和多轮 对话能力。 2023年,GPT-4的发布标志着多模态大模型技 术的一个新里程碑。下面将深入探讨 GPT-4的五 大突出特性,以及它如何改变我们理解和应用 AI技 术的方式。
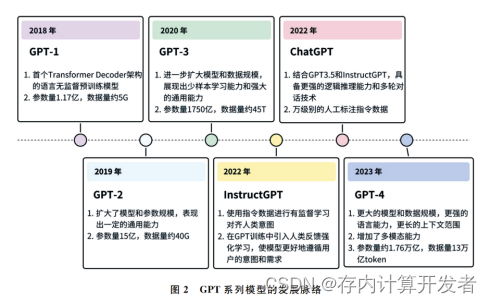
GPT-4对多模态大模型的启发
1.以语言和多模态结合的方式感知理解世界
多模态的感知理解涉及到多个模态之间的对 齐,而采取类似 GPT-4路线,通过大语言模型为主 导界面来实现多模态的对齐、融合、交互成为了目前 被广泛认可的一种多模态大模型结构范式。这是由 于文本有高效的表达效率、能够通过语义描述的方 式与其他模态建立直接的联系。此外,大语言模型 在预训练过程中学习到了非常多的世界知识,有潜 在理解多模态信息的能力。受启发于 GPT-4在结 合语言进行图像理解与推理能力上的巨大成功,训 练结合多模态大模型与大语言模型的“多模态大语 言模型”近期收到众多研究者的关注。
2.以语言和多模态结合的方式创作生成内容
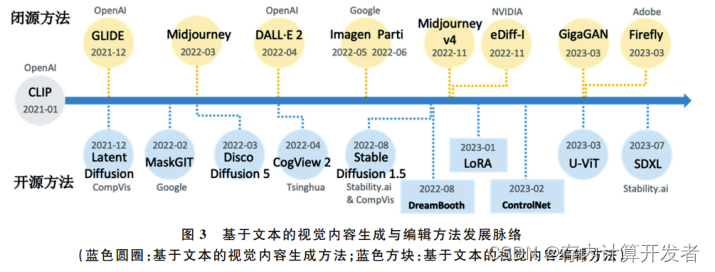
在众多生成模型中,目前多模态生成领域最为成功和引人瞩 目的模型主要包括序列生成模型和扩散生成模型 等。主流方法的发展脉络如图3所示。DALL-E [31] 是典型的图文多模态序列生成模型,其采用自回归 生成范式,在大规模数据(2.5亿个图文对)上进行 文本到图像生成的训练,在以文生图任务上取得了 突破性的生成质量和泛化能力。CogView [32]进一 步探索了多模态生成模型在下游任务上精调后的泛 化能力,在基于文本控制的样式学习、服装设计和图 像超分等任务上均取得出色的效果。
3.以语言和多模态结合的方式与人和环境交互
在与外部环境交互的过程中,GPT-4的引入为 多模态大模型提供了显著的优势。一方面,GPT-4 自身拥有庞大的内在知识库和高级的逻辑推理能 力,这些能力为多模态大模型提供了更为全面和准 确的认知和决策支持。例如,在导航任务中,模型可 以整合自然语言指令、视觉地图、声音信号等多模态 信息,通过 GPT-4的高级逻辑推理进行路径规划和 策略优化。另一方面,GPT-4在任务执行过程中的 反馈调整机制也更为先进和灵活。一旦模型在执行 任务时遇到未预见的难题或者复杂情境,它可以快 速地进行自我调整或者请求人类干预,以适应不断 变化的外部环境。这种动态的调整和优化过程不仅 提高了任务执行的成功率,也大大提升了模型的自 适应能力和鲁棒性。 在与外部知识库进行交互时,多模态大模型不 仅能通过文本查询与数据库对话,还能通过视觉和 声音等其他模态来获取和整合信息。例如,当模型 需要对一些专业性要求较高的任务进行深入解析 时,它可能会通过语言模式检索文献资料,同时也能 通过图像识别技术来分析与该任务相关的视觉素 材。通过这种方式,模型能够从多个维度获取信息, 并将这些信息整合在一起,生成一个更为全面和准确的回应。
总结
GPT-4这类大语言模型的出色语言能力为多 模态大模型的发展提供了新的方向。借助大语言 模型强大 的 语 言 理 解 和 生 成 能 力,通 过 将 其 与 视 觉、听觉、触 觉 等 真 实 世 界 的 多 模 态 信 号 结 合,多 模态大模型能够实现以语言赋能的多模态理解、多 模态生成和多模态交互。这将帮助多模态大模型 在感知世界、创作内容、与外部对象交互等能力上 产生飞 跃,推 动 实 现 通 用 的 多 模 态 人 工 智 能。然 而,在语言赋能多模态大模型的研究上仍然存在一 些挑战需要克服。例如,如何更好地利用克服多模 态大语言模型中的幻觉问题;如何结合语言和多模 态指令实现更加精细可控的多模态生成与编辑;如 何在多模态环境感知、人类语言和物理行动之间建 立映射关系,从而增强机器人等智能体的自主交互 能力等。通过不断攻克这些挑战,并促进语言大模 型和多模态大模型的发展和融合,多模态人工智能 将在更智能化和多样化的现实应用场景中发挥更 大的价值。
参考资料
- 多模态预训练模型综述
- GPT-4对多模态大模型在多模态理解、 生成、交互上的启发