前言
昨天投简历时遇到了这样的一个笔试。本以为会是数据结构算法之类的没想到直接发了一个word直接提需求,感觉挺有意思就写了这篇文章,感兴趣的朋友可以看看。

1. 网页内容解析
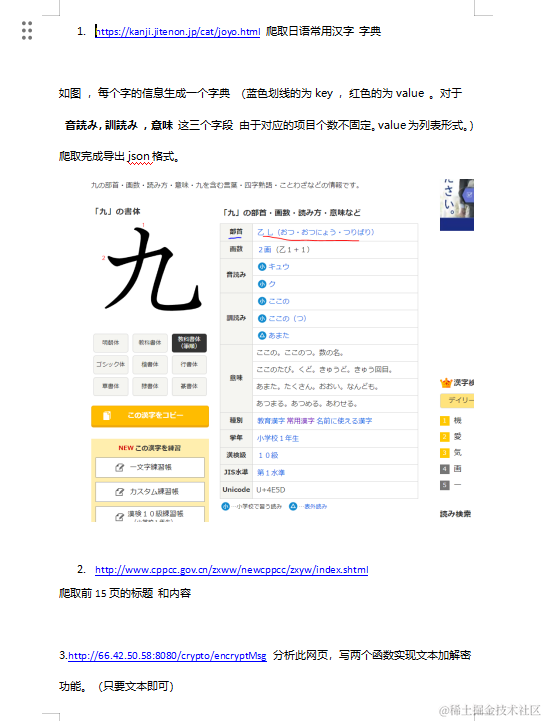
首先,我们通过请求网页获取到日本常用汉字的链接列表。然后,针对每个汉字链接,我们提取网页中相应部分的 HTML 内容。
首先分析页面结构
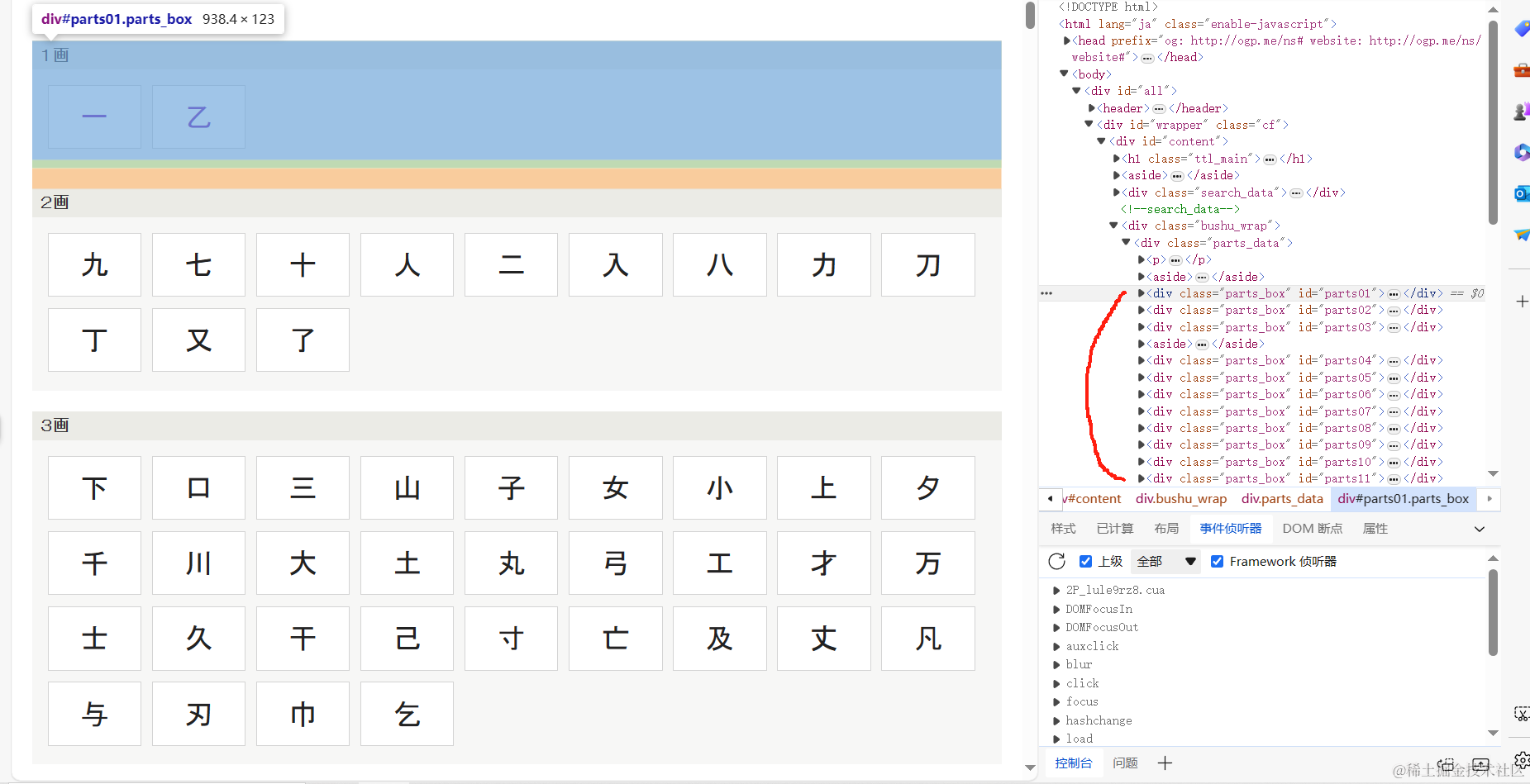
发现这些汉字有着相同的规律,先将.parts_box类标签拿到之后再用css选择器拿到对应的汉字标签.
url = 'https://kanji.jitenon.jp/cat/joyo.html'
response = requests.get(url)
response.encoding = 'utf-8'
html_content = response.textcss_selector = '#content > div.bushu_wrap > div > .parts_box '
parsed_elements = parse_css(html_content, css_selector)
urllist = []
for element in parsed_elements:chineslinks = element.select(".search_parts > li > a")for chineslink in chineslinks:chines = {}chines['link'] = chineslink['href']chines['name'] = chineslink.texturllist.append(chines)
首先,我用了Python的requests库发送了一个HTTP请求,抓取了目标网站的内容。然后,用了BeautifulSoup库进行HTML解析,找到了我需要的信息。通过一个简单的CSS选择器,我成功地定位到了汉字链接的位置。
接着,我遍历了这些链接,将它们逐个存储在了一个名为urllist的列表中。每个链接都包含着汉字的名称和对应的链接地址。
2.详情页解析
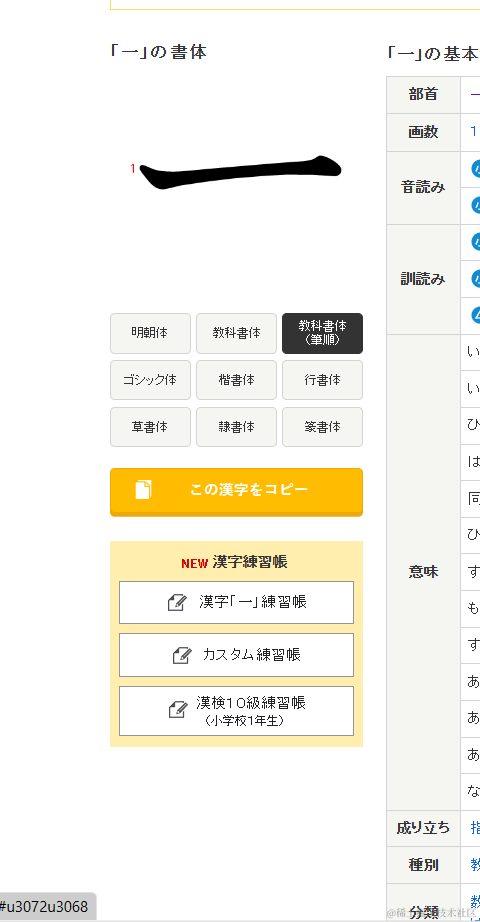
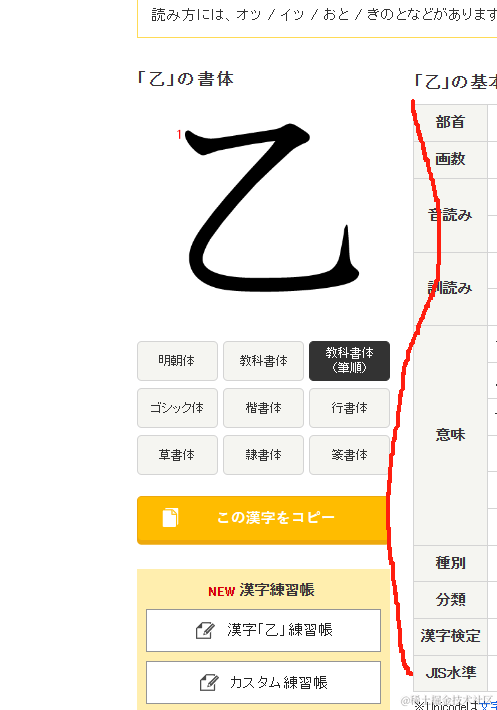
通过对比前两字可以发现每个字的介绍里的属性都有可能不一样,因此这里的思路是先拿到这部分标签的整体text,然后通过正则去进行筛选匹配。在进行字符拼接时加上分隔符,为之后的对转成列表形式时的字符分割做准备。
def get_detailed(chines):url = chines['link']response = requests.get(url)response.encoding = 'utf-8'html_content = response.textcss_selector = '#content > article > div.search_data > div > div.kanji_wrap > div.kanji_right > div > section > table >tbody > tr 'parsed_elements = parse_css(html_content, css_selector)text = ''separator = '%' # 定义分隔符for element in parsed_elements:# print(element.text)text =text+ ' '.join(element.stripped_strings)+ separatorfont = {}font['name'] = chines['name']## fontkey = element.select(".ruby_switch")[0].text# fontvaule = element.select(".ruby_switch > span")# print(fontkey)# print(text)def extract_text_between_patterns(text, start_patterns, end_patterns):"""从文本中提取两个模式之间的文本。参数:text (str): 待提取文本。start_patterns (list): 匹配文本起始的模式列表。end_patterns (list): 匹配文本结束的模式列表。返回:list: 匹配的文本列表,如果没有匹配项则返回None。"""matches = [] # 存储匹配结果的列表for start_pattern in start_patterns:for end_pattern in end_patterns:# 查找所有起始模式的位置start_matches = [match.end() for match in re.finditer(start_pattern, text)]# 查找所有结束模式的位置end_matches = [match.start() for match in re.finditer(end_pattern, text)]# 遍历每个起始位置和结束位置的组合for start_match in start_matches:for end_match in end_matches:if start_match < end_match: # 确保结束位置在起始位置之后subtext = text[start_match:end_match] # 提取子文本# 检查子文本中是否包含其他模式if not any(pattern in subtext for pattern in start_patterns[1:] + end_patterns):# 添加匹配的子文本到结果列表中,并保留第一个关键词matches.append(text[text.find(start_pattern):end_match].strip())break # 找到一个匹配后退出当前循环return matches if matches else None # 返回匹配结果列表,如果列表为空则返回None# 定义关键字列表start_patterns = ['部首', '画数', '音 読 み', '訓 読 み', '意味', '成 り 立 ち', '種別', '分類', '学年', '漢字 検定', 'JIS 水準']end_patterns = ['画数', '音 読 み', '訓 読 み', '意味', '成 り 立 ち', '種別', '分類', '学年', '漢字 検定', 'JIS 水準']# 调用函数进行提取results = extract_text_between_patterns(text, start_patterns, end_patterns)# print(results)# for i in range(len(results)):# print(results[i])def create_dict(data, patterns):hanzi_dict = {}for item in data:for pattern in patterns:if pattern in item:key, value = item.split(pattern, 1)hanzi_dict[pattern.strip()] = value.strip()breakreturn hanzi_dict# 测试patterns = ['部首', '画数', '音 読 み', '訓 読 み', '意味', '成 り 立 ち', '種別', '分類', '学年', '漢字 検定', 'JIS 水準']# 解析数据hanzi_dict = create_dict(results, patterns)# 遍历hanzi_dictfor key, value in hanzi_dict.items():parts = hanzi_dict[key].split('%')parts.pop() # 移除最后一个空字符串if len(parts) == 1:hanzi_dict[key] = str(parts[0])continuehanzi_dict[key] = partsreturn hanzi_dict
汉字详情页解析函数 get_detailed
该函数的主要目的是解析汉字的详情页,从中提取出部首、画数、音读み等关键信息,并以字典的形式返回。
-
输入参数:
chines:一个包含汉字链接和名称的字典,包括键'link'和'name'。
-
功能:
- 通过给定的链接获取汉字的详情页HTML内容。
- 使用CSS选择器定位到包含关键信息的元素。
- 提取目标信息并整理成字典格式。
-
详细步骤:
- 发送HTTP请求以获取详情页HTML内容,并将其编码为UTF-8格式。
- 使用预定义的CSS选择器来定位页面上包含关键信息的元素。
- 将解析得到的HTML元素提取出文本信息,并按照指定的分隔符连接成一个长字符串。
- 使用自定义的函数
extract_text_between_patterns从长字符串中提取出具体信息,并整理成字典格式。 - 最后,返回包含关键信息的字典。
-
关键函数:
extract_text_between_patterns:从长字符串中提取出具体信息的函数,它根据指定的起始和结束模式来匹配文本,并返回匹配的结果列表。
-
返回值:
- 一个字典,包含部首、画数、音读み等关键信息。
3.保存JSON
通过循环遍历urllist中的每个汉字链接,然后调用get_detailed函数来获取每个汉字的详细信息。获取到的信息被打印输出,并且添加到了名为ans的列表中。
接着,将整个ans列表保存为一个JSON文件,以便将获取到的汉字详细信息持久化存储下来。JSON文件的保存路径为当前目录下的ans.json文件,并且使用UTF-8编码格式,以确保能够正确地保存包含非ASCII字符的内容。
ans = []
for chines in urllist:chines = get_detailed(chines)print(chines)ans.append(chines)# 将ans保存为json文件
with open('ans.json', 'w', encoding='utf-8') as f:json.dump(ans, f, ensure_ascii=False, indent=4)


![[Windows] Wireshark v3.6.1 【网络抓包工具】](https://img-blog.csdnimg.cn/img_convert/2a2ab0a1aa95527c01da1c4e71c0a0e4.png)