前言
不知道大家有没有留意过,在使用一些app或者网站注册的时候,提示你用户名已经被占用了,比如我们熟知的《英雄联盟》有些人不知道取啥名字,干脆就叫“不知道取啥名”。

但是有这样困惑的可不止他一个,于是就出现了“不知道取啥名1”...“不知道取啥名99” 
需要更换一个,这是如何实现的呢?你可能想这不是很简单吗,去数据库里查一下有没有不就行了吗,那么假如用户数量很多,达到数亿级别呢,这又该如何是好? 
解决思路
到底有哪些方案呢? 数据库可行吗? 有什么缺点呢?缓存呢?还有什么更好的方法吗?

具体实现方案
关系型数据库
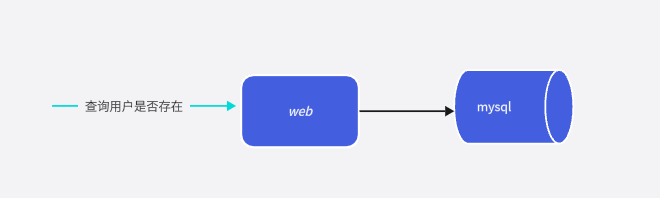 遇事不决,先想到数据库,很多时候,数据库虽说不是最好的方案,但是都可以成为一种保底方案,所以在面试的时候,如果想到不到其他方案我们可以首先想到数据库(这里所的当然是关系型数据库啦),那数据库到底应该怎么实现呢,说来也很简单,将用户信息的name列设置为唯一索引,这样有两个好处,首先索引可以提升查询的效率,同时还能利用唯一索引的特性,将用户的名字自动去重,查询的时候,直接"select id(或name) from user where name =用户名", 如果能返回查询结果,则说明用户已经存在,需要重新写新的名字,同时我还要告诉你,这句SQL这样写还能避免回表查询,这样也会在一定程度上提升查询的效率。
遇事不决,先想到数据库,很多时候,数据库虽说不是最好的方案,但是都可以成为一种保底方案,所以在面试的时候,如果想到不到其他方案我们可以首先想到数据库(这里所的当然是关系型数据库啦),那数据库到底应该怎么实现呢,说来也很简单,将用户信息的name列设置为唯一索引,这样有两个好处,首先索引可以提升查询的效率,同时还能利用唯一索引的特性,将用户的名字自动去重,查询的时候,直接"select id(或name) from user where name =用户名", 如果能返回查询结果,则说明用户已经存在,需要重新写新的名字,同时我还要告诉你,这句SQL这样写还能避免回表查询,这样也会在一定程度上提升查询的效率。
这种方案虽然实现了功能,但是这样做会带来一个比较致命的问题,那就是查询速度比较慢,亿级别数据是很大的,这时候还考虑mysql的话,他的查询速度将会非常慢,这样用户的体验将会非常不好,有人可能会说了呀,那你可以分库分表呀,是的,可以这么做,但是就算分库分表你还是得扫描整个库表,这种做法解决不了根本问题。同时数据库对并发连接和资源有限制。如果注册率继续增长,数据库服务器可能难以处理数量增加的传入请求。比如像英雄联盟这种大型游戏,突然有什么活动,用户大批量涌入,进行注册,就会出现数据库难以处理持续增长的请求。
使用缓存
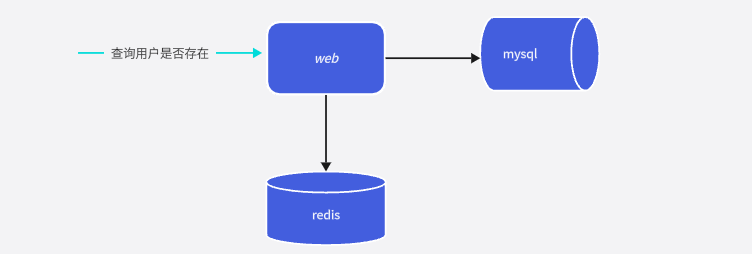
试想一下,数据库能实现的话,我们的缓存可以实现吗?
对哦,redis天生有set这种类型的数据,我们可以设置一个key,比如:register_user,然后每次注册用户直接向缓存添加用户名,如果能成功则说明用户不重复,不能添加成功则说明用户已经被注册。这些操作都是在缓存中进行的,虽然查询速度会比mysql快,但是又会引入一个新的问题,那就是redis的大key问题。
这里补充一下什么是redis的大key问题: 普遍认同的规范是:value > 10kb,即认定为大 key,同时像list,set,hash 等容器类型的 redis key,元素数量 > 5000,即认定为大 key。
那大key会带来什么问题呢?
大 key 会带来以下四种影响:
-
客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
-
引发网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
-
阻塞工作线程:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
-
内存分布不均:集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
像我们这种业务场景必定是大key无疑了,虽然我们也可以设计一些算法将key拆分,分成不同的小key,但是又有一个新的问题出现了,假设我们每个用户名字占20个字节,那1亿用户将会耗费20G左右的内存,内存是比较珍稀且昂贵的资源,我们一下就耗费20g资源,能不能想个法子,节约一下成本,让老板觉得你是个人才,以后每次你提离职老板都亲自挽留你,并给你涨工资。(你还真别说,我有同事就是这么干的而且还真成功了,只能羡慕人家技术好啊) 
布隆过滤器
直接缓存判断内存占用过大,有没有什么更好的办法呢?布隆过滤器就是很好的一个选择。
那究竟什么布隆过滤器呢?
布隆过滤器(Bloom Filter)是一种数据结构,用于快速检查一个元素是否存在于一个大型数据集中,通常用于在某些情况下快速过滤掉不可能存在的元素,以减少后续更昂贵的查询操作。 布隆过滤器的主要优点是它可以提供快速的查找和插入操作,并且在内存占用方面非常高效。 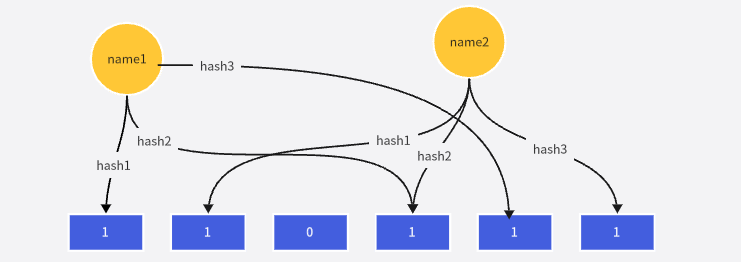 结构如图所示,布隆过滤器的核心思想是使用一个位数组(bit array)和一组哈希函数。
结构如图所示,布隆过滤器的核心思想是使用一个位数组(bit array)和一组哈希函数。
-
位数组(Bit Array) :布隆过滤器使用一个包含大量位的数组,通常初始化为全0。每个位可以存储两个值,通常是0或1。这些位被用来表示元素的存在或可能的存在。
-
哈希函数(Hash Functions) :布隆过滤器使用多个哈希函数,每个哈希函数可以将输入元素映射到位数组的一个或多个位置。这些哈希函数必须是独立且具有均匀分布特性。哈希函数的个数越多,产生误判的概率就越低。
那么具体是怎么做的呢?
布隆过滤器的操作分为添加元素和查询元素两个阶段
-
添加元素:如上图所示,当将字符串“name1”,“name2”插入布隆过滤器时,通过多个哈希函数将元素映射到位数组的多个位置,然后将这些位置的位设置为1。
-
查询元素:当要检查一个元素是否存在于布隆过滤器中时,通过相同的哈希函数将元素映射到位数组的相应位置,然后检查这些位置的位是否都为1。如果有任何一个位为0,那么可以确定元素不存在于数据集中。但如果所有位都是1,元素可能存在于数据集中,但也可能是误判。
说了那么多他的优点在哪呢?
优点: 节约内存空间,相比使用哈希表等数据结构,布隆过滤器通常需要更少的内存空间,因为它不存储实际元素,而只存储元素的哈希值。
有同学可能要问了呀,你说更少就更少吗?怎么证明他确实省,像京东口号一样,"多快好省"!

这里公司可以参考公式: m = -(n * ln(p)) / (ln(2)^2) 其中:m 是所需要的位数,n 是过滤器中元素的数量,p 是期望的误判率。
举个例子

在这里给大家一个案例,现在有1亿用户,我们把误判率设为0.001在给定的条件下,其中 n 是10^8(1亿),p 是0.001(0.1%),我们可以将这些值带入公式中:m = -(10^8 * ln(0.001)) / (ln(2)^2) 运算后,我们得到的结果 m 大约为2.88*10^9位。为了将位转换为字节(1字节 = 8位),我们需要除以8:m_in_bytes = m / 8这将得到大约3.6*10^8字节,或者说约 0.36 GB 的内存需求。 相比原理的20G一下减少了19G还多,而且查询的时候也是O(1)的时间复杂度,对其他实现方案来说,这将是一场屠杀
难道只有优点吗?

缺点 布隆过滤器在判断元素是否存在时,有一定的误判率。这意味着在某些情况下,它可能会错误地报告元素存在,但不会错误地报告元素不存在。不能删除元素,布隆过滤器通常不支持从集合中删除元素,因为删除一个元素会影响其他元素的哈希值,增加了误判率。
参看文献
https://web.archive.org/web/20110930114037/http://en.wikipedia.org/wiki/Bloom_filter#Probability_of_false_positives
https://blog.csdn.net/J_bean/article/details/135996254
https://juejin.cn/post/7293786247655129129
https://blog.csdn.net/weixin_62827806/article/details/136290340
本文由 mdnice 多平台发布