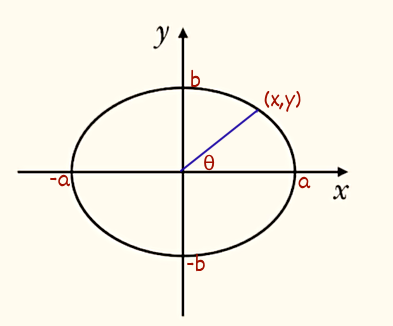
用飞桨帮我们好好学线性代数
参考自《动手学深度学习》第二章 《漫画线性代数》等。星河社区代码一键执行:线性代数难学怎么办?到星河社区让飞桨来帮忙!
线性代数,这个在数学领域举足轻重的学科,是众多学科的基础,也是现代科技发展的重要支柱。从物理学、工程学,到计算机科学、经济学,线性代数的应用无处不在。本文将通过飞桨示例帮助我们学习线性代数的基本知识,探索数学之美。

线性代数基本概念 标量、向量、矩阵
标量
我们日常生活中,经常说的几斤鱼、几碗米、几步路里面的几,就是标量。也就是我们从记事起,就在使用“标量”了,即使我们还不懂“标量”这个概念。
在《天仙子》这首歌中,用到了大量的标量:
一腔爱
一身恨
一缕清风
一丝魂
...
几重幕
几棵松
几层远峦
几声钟
...
我们采用了数学表示法,其中标量变量由普通小写字母表示(例如, x x x、 y y y 和 z z z)。我们用 R \mathbb{R} R 表示所有(连续)实数 标量的空间。为了方便,我们之后将严格定义 空间(space)是什么,但现在只要记住,表达式 x ∈ R x \in \mathbb{R} x∈R 是表示 x x x是一个实值标量的正式形式。符号 ∈ \in ∈ 称为 “属于”,它表示“是集合中的成员”。我们可以用 x , y ∈ { 0 , 1 } x, y \in \{0, 1\} x,y∈{0,1} 来表明 x x x 和 y y y 是值只能为 0 0 0 或 1 1 1的数字。
(标量由只有一个元素的张量表示)。在下面的代码中,我们实例化两个标量,并使用它们执行一些熟悉的算术运算,即加法,乘法,除法和指数。
import paddlex = paddle.to_tensor([3.0])
y = paddle.to_tensor([2.0])x + y, x * y, x / y, x**y
向量
带有方向的量,比如常见的“力”,一个苹果放在桌子上,它同时受着向下的重力和桌子对它向上力,两个力大小相等,方向相反,苹果处于相对静止的平衡态。
向量一般用数组来表示,可以简单的:将向量视为标量值组成的列表
我们将这些标量值称为向量的 元素(elements)或分量(components)。当我们的向量表示数据集中的样本时,它们的值具有一定的现实意义。例如,如果我们正在训练一个模型来预测贷款违约风险,我们可能会将每个申请人与一个向量相关联,其分量与其收入、工作年限、过往违约次数和其他因素相对应。如果我们正在研究医院患者可能面临的心脏病发作风险,我们可能会用一个向量来表示每个患者,其分量为最近的生命体征、胆固醇水平、每天运动时间等。在数学表示法中,我们通常将向量记为粗体、小写的符号(例如, x \mathbf{x} x、 y \mathbf{y} y和 z ) \mathbf{z}) z))。
我们通过一维张量处理向量。一般来说,张量可以具有任意长度,取决于机器的内存限制。
《漫画线性代数》中认为:向量是对矩阵的特殊解释
x = paddle.arange(4)
x我们可以使用下标来引用向量的任一元素。例如,我们可以通过 x i x_i xi 来引用第 i i i 个元素。注意,元素 x i x_i xi 是一个标量,所以我们在引用它时不会加粗。大量文献认为列向量是向量的默认方向,在本书中也是如此。在数学中,向量 x \mathbf{x} x 可以写为:
x = [ x 1 x 2 ⋮ x n ] , \mathbf{x} =\begin{bmatrix}x_{1} \\x_{2} \\ \vdots \\x_{n}\end{bmatrix}, x= x1x2⋮xn ,
其中 x 1 , … , x n x_1, \ldots, x_n x1,…,xn 是向量的元素。在代码中,我们(通过张量的索引来访问任一元素)。
x[2]
长度、维度和形状
让我们回顾一下 :numref:sec_ndarray 中的一些概念。向量只是一个数字数组。就像每个数组都有一个长度一样,每个向量也是如此。在数学表示法中,如果我们想说一个向量 x \mathbf{x} x 由 n n n 个实值标量组成,我们可以将其表示为 x ∈ R n \mathbf{x} \in \mathbb{R}^n x∈Rn。向量的长度通常称为向量的 维度(dimension)。
与普通的 Python 数组一样,我们可以通过调用 Python 的内置 len() 函数来[访问向量(张量)的长度]。
len(x)
当用张量表示一个向量(只有一个轴)时,我们也可以通过 .shape 属性访问向量的长度。形状(shape)是一个元组,列出了张量沿每个轴的长度(维数)。对于(只有一个轴的张量,形状只有一个元素。)
x.shape
集合
集合是“具有某种特定性质的具体的或抽象的对象汇总而成的集体”,与向量相比,集合并不关注元素之间的顺序和相对位置,只关注元素的存在与否。
X = {4, 10}
Y = {2, 4, 6, 8, 10}
x = 4
print(x in X, X in Y, X < Y)矩阵
- 定义:将数排列成m行n列,用括号将它围起来,这种形式组合叫做矩阵。称为m * n矩阵,也叫m行n列矩阵,括号中的数叫元素。
- 方阵:行列数相等的矩阵,叫方阵
正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。矩阵,我们通常用粗体、大写字母来表示(例如, X \mathbf{X} X、 Y \mathbf{Y} Y 和 Z \mathbf{Z} Z),在代码中表示为具有两个轴的张量。
在数学表示法中,我们使用 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n 来表示矩阵 A \mathbf{A} A ,其由 m m m 行和 n n n 列的实值标量组成。直观地,我们可以将任意矩阵 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n 视为一个表格,其中每个元素 a i j a_{ij} aij 属于第 i i i 行第 j j j 列:
A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] . \mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \\ \end{bmatrix}. A= a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn .
:eqlabel:eq_matrix_def
对于任意 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n, A \mathbf{A} A的形状是( m m m, n n n)或 m × n m \times n m×n。当矩阵具有相同数量的行和列时,其形状将变为正方形;因此,它被称为 方矩阵(square matrix)。
当调用函数来实例化张量时,我们可以[通过指定两个分量 m m m 和 n n n来创建一个形状为 m × n m \times n m×n 的矩阵]。
A = paddle.reshape(paddle.arange(20), (5, 4))
A
我们可以通过行索引( i i i)和列索引( j j j)来访问矩阵中的标量元素 a i j a_{ij} aij,例如 [ A ] i j [\mathbf{A}]_{ij} [A]ij。如果没有给出矩阵 A \mathbf{A} A 的标量元素,如在 :eqref:eq_matrix_def那样,我们可以简单地使用矩阵 A \mathbf{A} A 的小写字母索引下标 a i j a_{ij} aij来引用 [ A ] i j [\mathbf{A}]_{ij} [A]ij。为了表示起来简单,只有在必要时才会将逗号插入到单独的索引中,例如 a 2 , 3 j a_{2, 3j} a2,3j 和 [ A ] 2 i − 1 , 3 [\mathbf{A}]_{2i-1, 3} [A]2i−1,3。
有时候,我们想翻转轴。当我们交换矩阵的行和列时,结果称为矩阵的 转置(transpose)。我们用 a ⊤ \mathbf{a}^\top a⊤来表示矩阵的转置,如果 B = A ⊤ \mathbf{B} = \mathbf{A}^\top B=A⊤,则对于任意 i i i和 j j j,都有 b i j = a j i b_{ij} = a_{ji} bij=aji。因此,在 :eqref:eq_matrix_def 中的转置是一个形状为 n × m n \times m n×m的矩阵:
A ⊤ = [ a 11 a 21 … a m 1 a 12 a 22 … a m 2 ⋮ ⋮ ⋱ ⋮ a 1 n a 2 n … a m n ] . \mathbf{A}^\top = \begin{bmatrix} a_{11} & a_{21} & \dots & a_{m1} \\ a_{12} & a_{22} & \dots & a_{m2} \\ \vdots & \vdots & \ddots & \vdots \\ a_{1n} & a_{2n} & \dots & a_{mn} \end{bmatrix}. A⊤= a11a12⋮a1na21a22⋮a2n……⋱…am1am2⋮amn .
现在我们在代码中访问(矩阵的转置)。
paddle.transpose(A, perm=[1, 0])
作为方矩阵的一种特殊类型,[对称矩阵(symmetric matrix) A \mathbf{A} A 等于其转置: A = A ⊤ \mathbf{A} = \mathbf{A}^\top A=A⊤]。这里我们定义一个对称矩阵 B:
B = paddle.to_tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B
- 现在我们将
B与它的转置进行比较。
B == paddle.transpose(B, perm=[1, 0])
矩阵的优点
- 能够将一次方程组很清楚的表达出来
- 可以减轻老师在黑板上书写的辛苦
- 可以减少书籍的用纸量
矩阵的类型
- 零矩阵
- 转置矩阵
- 对称矩阵
- 三角矩阵
- 对角矩阵
- 单位矩阵
- 逆矩阵
逆矩阵求解
函数paddle.linalg.pinv 通过奇异值分解(svd)来计算伪逆矩阵
import paddlex = paddle.arange(15).reshape((3, 5)).astype('float64')
input = paddle.to_tensor(x)
out = paddle.linalg.pinv(input)
print(input)print(out)点积(Dot Product)
到目前为止,我们只执行了按元素操作、求和及平均值。如果这就是我们所能做的,那么线性代数可能就不需要单独一节了。
但是,最基本的操作之一是点积。给定两个向量 x , y ∈ R d \mathbf{x}, \mathbf{y} \in \mathbb{R}^d x,y∈Rd,它们的 点积(dot product) x ⊤ y \mathbf{x}^\top \mathbf{y} x⊤y(或 ⟨ x , y ⟩ \langle \mathbf{x}, \mathbf{y} \rangle ⟨x,y⟩)是相同位置的按元素乘积的和: x ⊤ y = ∑ i = 1 d x i y i \mathbf{x}^\top \mathbf{y} = \sum_{i=1}^{d} x_i y_i x⊤y=∑i=1dxiyi。
[点积是相同位置的按元素乘积的和]
x = paddle.arange(4, dtype=paddle.float32)
y = paddle.ones(shape=[4], dtype='float32')
x, y, paddle.dot(x, y)
点积在很多场合都很有用。例如,给定一组由向量 x ∈ R d \mathbf{x} \in \mathbb{R}^d x∈Rd 表示的值,和一组由 w ∈ R d \mathbf{w} \in \mathbb{R}^d w∈Rd 表示的权重。 x \mathbf{x} x 中的值根据权重 w \mathbf{w} w 的加权和可以表示为点积 x ⊤ w \mathbf{x}^\top \mathbf{w} x⊤w。当权重为非负数且和为1(即 ( ∑ i = 1 d w i = 1 ) \left(\sum_{i=1}^{d} {w_i} = 1\right) (∑i=1dwi=1))时,点积表示 加权平均(weighted average)。将两个向量归一化得到单位长度后,点积表示它们夹角的余弦。我们将在本节的后面正式介绍长度(length)的概念。
矩阵-向量积
现在我们知道如何计算点积,我们可以开始理解 矩阵-向量积(matrix-vector products)。回顾分别在 :eqref:eq_matrix_def 和 :eqref:eq_vec_def 中定义并画出的矩阵 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n 和向量 x ∈ R n \mathbf{x} \in \mathbb{R}^n x∈Rn。让我们将矩阵 A \mathbf{A} A用它的行向量表示
A = [ a 1 ⊤ a 2 ⊤ ⋮ a m ⊤ ] , \mathbf{A}= \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_m \\ \end{bmatrix}, A= a1⊤a2⊤⋮am⊤ ,
其中每个 a i ⊤ ∈ R n \mathbf{a}^\top_{i} \in \mathbb{R}^n ai⊤∈Rn 都是行向量,表示矩阵的第 i i i 行。[矩阵向量积 A x \mathbf{A}\mathbf{x} Ax 是一个长度为 m m m 的列向量,其第 i i i 个元素是点积 a i ⊤ x \mathbf{a}^\top_i \mathbf{x} ai⊤x]:
A x = [ a 1 ⊤ a 2 ⊤ ⋮ a m ⊤ ] x = [ a 1 ⊤ x a 2 ⊤ x ⋮ a m ⊤ x ] . \mathbf{A}\mathbf{x} = \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_m \\ \end{bmatrix}\mathbf{x} = \begin{bmatrix} \mathbf{a}^\top_{1} \mathbf{x} \\ \mathbf{a}^\top_{2} \mathbf{x} \\ \vdots\\ \mathbf{a}^\top_{m} \mathbf{x}\\ \end{bmatrix}. Ax= a1⊤a2⊤⋮am⊤ x= a1⊤xa2⊤x⋮am⊤x .
我们可以把一个矩阵 A ∈ R m × n \mathbf{A}\in \mathbb{R}^{m \times n} A∈Rm×n 乘法看作是一个从 R n \mathbb{R}^{n} Rn 到 R m \mathbb{R}^{m} Rm 向量的转换。这些转换证明是非常有用的。例如,我们可以用方阵的乘法来表示旋转。
我们将在后续章节中讲到,我们也可以使用矩阵-向量积来描述在给定前一层的值时,求解神经网络每一层所需的复杂计算。
在飞桨等AI框架中,会专门给出一个mv函数来进行矩阵-向量积,当我们为矩阵 A 和向量 x 调用 paddle.mv(A, x)时,会执行矩阵-向量积。注意,A 的列维数(沿轴1的长度)必须与 x 的维数(其长度)相同。paddle.mv 可以看作特殊的时候矩阵相乘,即paddle.mm的特例。
# mv 需要数据类型为 float32、float64,而且两个变量类型要一致。
print(A.dtype, x.dtype)
A=A.astype("float32")
print(A.dtype, A.shape, x.dtype, x.shape)
paddle.mv(A, x)
# paddle.mv是paddle.mm 里矩阵为向量的特例。
paddle.mv(A, x), paddle.mm(A, x)
矩阵-矩阵乘法
如果你已经掌握了点积和矩阵-向量积的知识,那么 矩阵-矩阵乘法(matrix-matrix multiplication) 应该很简单。
假设我们有两个矩阵 A ∈ R n × k \mathbf{A} \in \mathbb{R}^{n \times k} A∈Rn×k 和 B ∈ R k × m \mathbf{B} \in \mathbb{R}^{k \times m} B∈Rk×m:
A = [ a 11 a 12 ⋯ a 1 k a 21 a 22 ⋯ a 2 k ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n k ] , B = [ b 11 b 12 ⋯ b 1 m b 21 b 22 ⋯ b 2 m ⋮ ⋮ ⋱ ⋮ b k 1 b k 2 ⋯ b k m ] . \mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1k} \\ a_{21} & a_{22} & \cdots & a_{2k} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nk} \\ \end{bmatrix},\quad \mathbf{B}=\begin{bmatrix} b_{11} & b_{12} & \cdots & b_{1m} \\ b_{21} & b_{22} & \cdots & b_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ b_{k1} & b_{k2} & \cdots & b_{km} \\ \end{bmatrix}. A= a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1ka2k⋮ank ,B= b11b21⋮bk1b12b22⋮bk2⋯⋯⋱⋯b1mb2m⋮bkm .
用行向量 a i ⊤ ∈ R k \mathbf{a}^\top_{i} \in \mathbb{R}^k ai⊤∈Rk 表示矩阵 A \mathbf{A} A的第 i i i 行,并让列向量 b j ∈ R k \mathbf{b}_{j} \in \mathbb{R}^k bj∈Rk 作为矩阵 B \mathbf{B} B的第 j j j 列。要生成矩阵积 C = A B \mathbf{C} = \mathbf{A}\mathbf{B} C=AB,最简单的方法是考虑 A \mathbf{A} A的行向量和 B \mathbf{B} B的列向量:
A = [ a 1 ⊤ a 2 ⊤ ⋮ a n ⊤ ] , B = [ b 1 b 2 ⋯ b m ] . \mathbf{A}= \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_n \\ \end{bmatrix}, \quad \mathbf{B}=\begin{bmatrix} \mathbf{b}_{1} & \mathbf{b}_{2} & \cdots & \mathbf{b}_{m} \\ \end{bmatrix}. A= a1⊤a2⊤⋮an⊤ ,B=[b1b2⋯bm].
当我们简单地将每个元素 c i j c_{ij} cij计算为点积 a i ⊤ b j \mathbf{a}^\top_i \mathbf{b}_j ai⊤bj:
C = A B = [ a 1 ⊤ a 2 ⊤ ⋮ a n ⊤ ] [ b 1 b 2 ⋯ b m ] = [ a 1 ⊤ b 1 a 1 ⊤ b 2 ⋯ a 1 ⊤ b m a 2 ⊤ b 1 a 2 ⊤ b 2 ⋯ a 2 ⊤ b m ⋮ ⋮ ⋱ ⋮ a n ⊤ b 1 a n ⊤ b 2 ⋯ a n ⊤ b m ] . \mathbf{C} = \mathbf{AB} = \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_n \\ \end{bmatrix} \begin{bmatrix} \mathbf{b}_{1} & \mathbf{b}_{2} & \cdots & \mathbf{b}_{m} \\ \end{bmatrix} = \begin{bmatrix} \mathbf{a}^\top_{1} \mathbf{b}_1 & \mathbf{a}^\top_{1}\mathbf{b}_2& \cdots & \mathbf{a}^\top_{1} \mathbf{b}_m \\ \mathbf{a}^\top_{2}\mathbf{b}_1 & \mathbf{a}^\top_{2} \mathbf{b}_2 & \cdots & \mathbf{a}^\top_{2} \mathbf{b}_m \\ \vdots & \vdots & \ddots &\vdots\\ \mathbf{a}^\top_{n} \mathbf{b}_1 & \mathbf{a}^\top_{n}\mathbf{b}_2& \cdots& \mathbf{a}^\top_{n} \mathbf{b}_m \end{bmatrix}. C=AB= a1⊤a2⊤⋮an⊤ [b1b2⋯bm]= a1⊤b1a2⊤b1⋮an⊤b1a1⊤b2a2⊤b2⋮an⊤b2⋯⋯⋱⋯a1⊤bma2⊤bm⋮an⊤bm .
[我们可以将矩阵-矩阵乘法 A B \mathbf{AB} AB 看作是简单地执行 m m m次矩阵-向量积,并将结果拼接在一起,形成一个 n × m n \times m n×m 矩阵]。在下面的代码中,我们在 A 和 B 上执行矩阵乘法。这里的A 是一个5行4列的矩阵,B是一个4行3列的矩阵。相乘后,我们得到了一个5行3列的矩阵。
B = paddle.ones(shape=[4, 3], dtype='float32')
A.shape, B.shape, paddle.mm(A, B)
飞桨里面paddle.mm和paddle.matmul是等效的。
import paddle
# 定义两个3x3的矩阵A和B
A = paddle.to_tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=paddle.float32)
B = paddle.to_tensor([[10, 11, 12], [13, 14, 15], [16, 17, 18]], dtype=paddle.float32) # 计算矩阵乘积C
C = paddle.mm(A, B)
D = paddle.matmul(A, B) # 打印结果
print("\r", C, "\r", D)张量
[就像向量是标量的推广,矩阵是向量的推广一样,我们可以构建具有更多轴的数据结构]。张量(本小节中的 “张量” 指代数对象)为我们提供了描述具有任意数量轴的 n n n维数组的通用方法。例如,向量是一阶张量,矩阵是二阶张量。张量用特殊字体的大写字母(例如, X \mathsf{X} X、 Y \mathsf{Y} Y 和 Z \mathsf{Z} Z)表示,它们的索引机制(例如 x i j k x_{ijk} xijk 和 [ X ] 1 , 2 i − 1 , 3 [\mathsf{X}]_{1, 2i-1, 3} [X]1,2i−1,3)与矩阵类似。
当我们开始处理图像时,张量将变得更加重要,图像以 n n n维数组形式出现,其中3个轴对应于高度、宽度,以及一个通道(channel)轴,用于堆叠颜色通道(红色、绿色和蓝色)。比如一副图像的张量可能是[3, 512, 512],表示这是一个三通到颜色,高和宽都是512像素的图片。
张量算法的基本性质
标量、向量、矩阵和任意数量轴的张量(本小节中的 “张量” 指代数对象)有一些很好的属性,通常会派上用场。例如,你可能已经从按元素操作的定义中注意到,任何按元素的一元运算都不会改变其操作数的形状。同样,[给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量]。例如,将两个相同形状的矩阵相加会在这两个矩阵上执行元素加法。
具体而言,[两个矩阵的按元素乘法称为 哈达玛积(Hadamard product)(数学符号 ⊙ \odot ⊙)]。对于矩阵 B ∈ R m × n \mathbf{B} \in \mathbb{R}^{m \times n} B∈Rm×n,其中第 i i i 行和第 j j j 列的元素是 b i j b_{ij} bij。矩阵 A \mathbf{A} A(在 :eqref:eq_matrix_def 中定义)和 B \mathbf{B} B的哈达玛积为:
A ⊙ B = [ a 11 b 11 a 12 b 12 … a 1 n b 1 n a 21 b 21 a 22 b 22 … a 2 n b 2 n ⋮ ⋮ ⋱ ⋮ a m 1 b m 1 a m 2 b m 2 … a m n b m n ] . \mathbf{A} \odot \mathbf{B} = \begin{bmatrix} a_{11} b_{11} & a_{12} b_{12} & \dots & a_{1n} b_{1n} \\ a_{21} b_{21} & a_{22} b_{22} & \dots & a_{2n} b_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} b_{m1} & a_{m2} b_{m2} & \dots & a_{mn} b_{mn} \end{bmatrix}. A⊙B= a11b11a21b21⋮am1bm1a12b12a22b22⋮am2bm2……⋱…a1nb1na2nb2n⋮amnbmn .
A * B
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
a = 2
X = paddle.reshape(paddle.arange(24), (2, 3, 4))
a + X, (a * X).shape
映射
线性映射
满足:
\begin{align}
f(x_i) + f(x_j) &= f(x_i+x_j) \
cf(x_i) &= f(cx_i) \
\end{align}
则称为线性映射。
从图形上看,第一反应就是线性映射是过原点的线。实际上这是特例,不是必要条件。
我当前对线性映射的理解:围绕原点进行转动,得到的映射是线性映射。而沿着x或y轴平移这种最简单的变化,不是线性映射。(换句话说,它影响了透视大小,就像《三体》里面深水王子,他一旦不符合透视原理,也就无法画到画纸上了。)
前面的理解有误,现在对线性和非线性映射的理解是:线性映射顺序无关,非线性映射顺序有关,也就是假如有多个映射A、B和C,如果任何排列组合的顺序做映射,如(A B C)、(A C B) (C A B)等都不影响最终的映射结果,那么这就是线性映射,如果改变了顺序就会改变映射结果,那么就是非线性映射。
换句话说,线性映射可以看作是没有时间参数的映射,因为它们的结果不受顺序的影响,而非线性映射则受到顺序的影响,类似于引入了时间参数。
学习线性映射有什么用?
以下为文心一言生成的答案:
线性映射在机器学习、深度学习、图像处理、自然语言处理等领域都有着广泛的应用。
在机器学习领域,线性映射常常被用于预测、分类和回归等多种特定目标。比如,在训练一个预测模型时,可以使用线性映射将原始数据转换为更有意义的特征空间,从而提高模型预测的准确性。在分类问题中,线性映射也有着重要的作用,比如将原始的像素特征转换为均值、方差等高维特征,从而更有效地表示分类对象。此外,线性映射还可以用于回归问题,例如将一维信号转换为一个高维特征向量,从而更容易得到有意义的回归结果。
在图像处理和自然语言处理领域,线性映射可以用于图像的变换、裁剪、缩放、旋转等操作,以便更好地实现特定的应用需求。例如,在图像处理中,可以使用线性映射将图像从一个尺度变换到另一个尺度,以便更好地实现图像变换和滤波等操作;在自然语言处理中,可以使用线性映射将自然语言序列映射到一个更高的维度,以便更好地实现自然语言处理中的分词、词性标注、句法分析等任务。
除此之外,线性映射还可以用于其他领域,例如音频处理、语音识别、金融数据分析等。线性映射的应用非常广泛,可以为不同领域的应用提供高效、准确的算法和技术支持。
非线性映射
非线性变换可以使模型更加复杂,能更好的拟合和解释数据。在神经网络中,非线性变换通常通过激活函数实现,如ReLU、sigmoid和tanh等,它们能够引入非线性特性,使得神经网络能够学习和表示复杂的数据模式。这使得神经网络能够处理那些线性模型无法有效处理的问题,如图像识别、语音识别和自然语言处理等。
以下是非线性变换sigmoid的例子:
import paddlem = paddle.nn.Sigmoid()
x = paddle.to_tensor([-10, -1, 0, 1.0, 2.0, 3.0, 4.0, 10])
out = m(x)
print(out)范数
范数常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。简单来说,范数是一个具有长度概念的函数。向量的范数是表示一个向量有多大。 这里考虑的大小(size)概念不涉及维度,而是分量的大小。
import paddle
x = paddle.arange(24, dtype="float32").reshape([2, 3, 4]) - 12
print(x)# compute frobenius norm along last two dimensions.
out_fro = paddle.linalg.norm(x, p='fro', axis=[0,1])
print(out_fro)# compute 2-order vector norm along last dimension.
out_pnorm = paddle.linalg.norm(x, p=2, axis=-1)
print(out_pnorm)# compute 2-order norm along [0,1] dimension.
out_pnorm = paddle.linalg.norm(x, p=2, axis=[0,1])
print(out_pnorm)# compute inf-order norm
out_pnorm = paddle.linalg.norm(x, p=float("inf"))
print(out_pnorm)out_pnorm = paddle.linalg.norm(x, p=float("inf"), axis=0)
print(out_pnorm)# compute -inf-order norm
out_pnorm = paddle.linalg.norm(x, p=-float("inf"))
print(out_pnorm)out_pnorm = paddle.linalg.norm(x, p=-float("inf"), axis=0)
print(out_pnorm)作者:网名skywalk 或 天马行空,济宁市极快软件科技有限公司的AI架构师,百度飞桨PPDE。