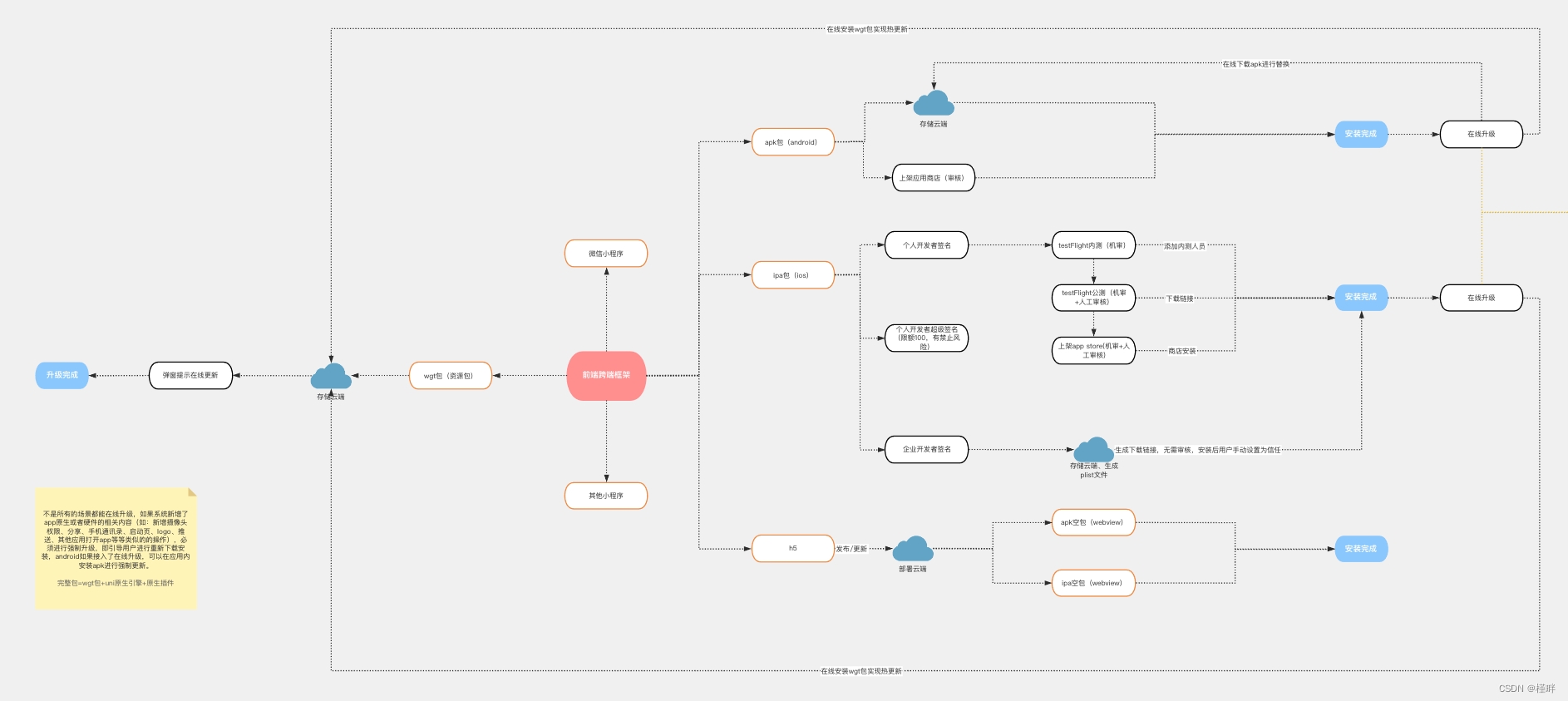
基于分区的SIMD处理及在列存数据库系统中的应用
单指令多数据(SIMD)范式称为列存数据库系统中优化查询处理的核心原则。到目前为止,只有LOAD/STORE指令被认为足够高效,可以实现预期的加速,并且认为需要尽可能避免GATHER/SCATTER操作。但是GATHER指令提供了一种非常灵活的方式用来将非连续内存位置的数据填充到SIMD寄存器中。正如本文讨论的那样,如果使用方法合适,GATHER会达到和LOAD指令一样的性能。我们概述了一种新的访问模式,该模式允许细粒度、基于分区的SIMD实现。然后,我们将这种基于分区的处理应用到列存数据库系统中,通过2个代表性示例,证明我们新的访问模式的效率及适用性。
1、引言
单指令多数据(SIMD)是一种并行概念,其特征在于统一操作同时应用于单个指令中的多个数据元素。现代的CPU都支持这样的SIMD指令以及AVX扩展,其中英特尔CPUs是其中代表。SIMD扩展包括2方面东西:SIMD寄存器,比传统的标量寄存器大;SIMD指令。SIM指令集包括算术操作、布尔操作、逻辑和算术移位、数据类型转换。此外还有一些特定的SIMD指令可以将数据从主存加载到SIMD寄存器并将其写回。一方面,连续放在内存中的数据元素可以通过LOAD和STORE指令访问。另一方面,GATHER和SCATTER指令反映了非连续内存访问的替代方式。但是,通常指导原则是,如果可能,尽可能避免使用GATHER/SCATTER,因为他的性能损失比较严重。目前,还没有对GATHER/SCATTER性能进行明确的理解。本文的主要贡献之一就是对不同Intel CPUs的GATHER指令进行了系统的评估。并且关于strided access(跨步访问)模式。评估结果表明,GATHER指令的性能主要取决于跨步访问的应用及步的大小。如果使用合适,GATHER会有接近LOAD指令的性能。另一个贡献,基于分区的SIMD访问概念,提出新型的block-strided access访问模式,并在一个简单的分析查询模型和整数压缩算法中进行比较。
2、GATHER评估
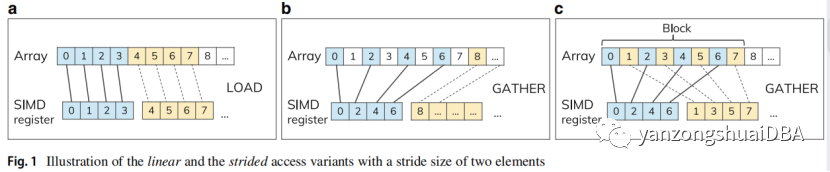
鉴于AggSum性能依赖于加载指令,所以使用aggregation-sum(AggSum)操作进行评估。AggSum对输入数组进行迭代计算,每次迭代执行加法,最后将总和(单个值)写回主存。图1a使用线性访问模式,利用LOAD指令进行迭代计算。跨步变种使用跨步访问模式,利用GATHER指令。GHATER指令需要给一个数据首地址以及步长。基于此,跨步访问模式又分2种:图1b是传统风格的stride-full,根据步幅加载数据知道数组结束(使用了2的步幅)。处理依次后,移动一次头,然后接着在进行一次迭代,这样依次处理所有数据。图1c是将输入数组逻辑分块,提出stride-block的风格。本例中,定义步长为2,块大小为8。这就意味着,每个大小为8的块,需要运行2次大小为4的SIMD寄存器。因此它并不能像stride-full一样作为一个整体立即执行。比stride-full风格更据cache-friendly。
3、基于分区的SIMD
上述实验说明,在单线程和多线程环境中,SIMD寄存器可以实验GATHER操作访问非连续内存中的元素,可达到LOAD指令访问连续内存的性能。然而,GAHTER指令需要合适的访问模式以达到他的峰值。根据上述评估,跨步访问模式的变种stride-block满足下面属性P1和P2:
P1:输入数据逻辑分区成block大小,每个block大小:
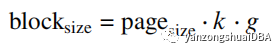
其中k是根据数据类型不同的SIMD寄存器通道数,比如一个128位的矢量寄存器可以分成8个16位的数据通道。
g>=1,作为页gap系数。pagesize 由操作系统决定,通常4kb。
P2:对逻辑块进行连续处理,每个块内采用的访问模式是以字节为步幅的跨步访问模式。
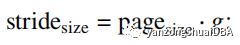
block-strided访问模式如下图所示:
SIMD的通道数k为4,因此输入数据逻辑分块内由4页,gap因子g为1。如果g>1,则一个block由g*k个连续的页组成,一个通道负责g个页。也就是说g定义了两个被访问的页面之间的间隙,每个块内页面使用步幅为g的跨步访问模式。
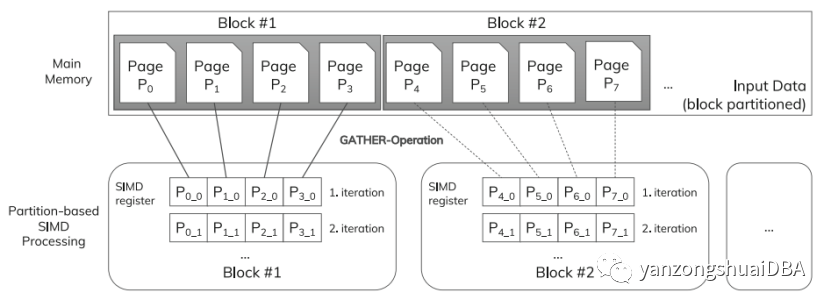
这种访问模式支持一种细粒度、页面分区的SIMD处理概念。我们基于分区的SIMD处理概念通过访问模式和分区隐式地对数据进行分区,页面分配给SIMD通道。SIMD通道操作他们本地的页面。
理解:相当于将一大串输入数据逻辑分块,每个块内分配g*k个页。g>1,比如是2,则块内使用gather指令进行跨步为2的步幅进行访问。迭代1次,并发访问k个页;头指针移访问完,动一页,迭代2次并发访问后续的页。这种方式有什么用呢?也就是对于GAHTER的应用来说,能适用这种方式?过滤后的数据进行转储,步长不固定,貌似用不到这种固定步长的方式。
4、应用案例
4.1 向量化查询处理
一个基于分区的SIMD方式的应用场景是基于列存的向量化查询。每个查询算子迭代处理多个值的向量。优势是良好的指令缓存和CPU利用率,同时保持较低的物化代价。然而,选择一个合适向量大小并不是一个简单的事情。较小的向量会提高数据cache利用率但会增加指令cache misses。大的向量会增加物化代价并损耗数据cache利用率。因此,我们基于分区的SIMD处理概念旨在显式地缓存当前和未来处理多个页面所需的数据,与线性访问相比,可以提高该处理模型的性能。
对满足列B上的谓词条件的记录,在列A上进行聚合sum操作。实现了必要算子:filter和AggSum。Filter算子首先将谓词值广播到SIMD寄存器,然后每个迭代filter将列B的数据加载到SIMD寄存器,并与谓词向量寄存器进行比较。加载操作要么使用LOAD指令(线性访问模式),要么使用GATHER指令(block-stried访问模式)。AVX2和AVX512支持cmp的向量寄存器操作。结果转换成一个bitmask,减小物化代价。第n位是1,表示SIMD寄存器种的第n个元素满足filter条件。在bitmask旁边不会存储任何额外的位置信息,所以使用这个bitmask的操作符必须隐式地解码特定的信息。当使用AVX512时,转换时动态完成的。高效的AVX2实现更具挑战性。
AVX2种使用_mm256_cmpeq_epi32比较2个SIMD寄存器(包含32位整数),并产生相同大小的SIMD寄存器值。相等对应的位位1,否则位0。使用_mm256_castsi256_ps将上面的结果转换成bitmask值。使用_mm256_movemask_pd将每64位元素种最高位包装在一个word中。虽然这个过程看起来很昂贵,但我们的实验表明,由此内存减少了32倍,步长了内存绑定算法的额外计算成本。
AggSum算子首次调用时,将一个结果的SIMD寄存器初始化0。处理了一个完整的向量后,操作符返回这个SIMD寄存器。然后将相同的寄存器用作每个后续调用的输入,并在每个处理的向量中进行修改。处理完所有数据时,sum值汇总到SIMD寄存器中并返回。对于每个向量,AggSum算子将列A的相关数据传输到一个SIMD寄存器中,并从上一个操作符中加载位置等下的bitmask。
需要注意,数据传输方法必须与前一个操作符相同。虽然AVX512原生支持mask,但是我们需要自己为AVX2创建一个特殊的mask SIMD寄存器,并使用它来零化无效数据。这个SIMD寄存器包含的所有位设置0或者1.因此可以将掩码先广播到SIMD寄存器,由lane-id和二进制与移位。这样,SIMD寄存器的每个通道包含对应位1的或者0的值。SIMD寄存器中的所有元素都减少了1,其中−1等于设置为1的所有位。最后,所得到的SIMD寄存器取反,并与数据SIMD寄存器进行与操作。
评估中,针对3个维度:1)过滤的选择率;2)向量大小;3)页gap因子。单线程评估结果1)1024向量大小(AVX2使用unint32_t);2)2084向量大小(AVX512,uint64_t)。由于我们实现了AggSum分支,所以总体查询吞吐量取决于过滤的选择性。该分支检查过滤的bitmask结果,因为AggSum操作仅针对满足条件的值。如果bitmask都是0,则给跳过该组值。根据评估结果他认为基于分区的SIMD处理概念可以高效应用到向量化处理模型中。
理解:仅将基于分区的处理应用在加载上,感觉没啥实际可用的价值。如果能够针对索引的Gather应用加载,则可以灵活处理过滤后的数据,这样才会更加有意义。
参考
2022:https://link.springer.com/article/10.1007/s13222-022-00431-0