ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
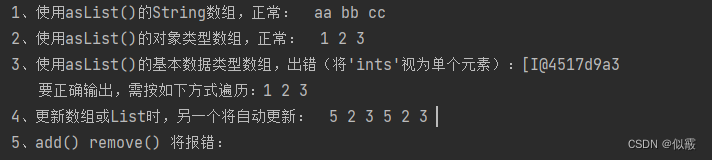
更多资源欢迎关注

Meta 疯狂砸入数十亿美元,一部分招揽人才,一部分造芯片。
Meta 正在不遗余力地想要在生成式 AI 领域赶上竞争对手,目标是投入数十亿美元用于 AI 研究。这些巨资一部分用于招募 AI 研究员。但更大的一部分用于开发硬件,特别是用于运行和训练 Meta AI 模型的芯片。
在英特尔宣布其最新人工智能加速器硬件的第二天,Meta 便迅速公布了关于芯片研发的最新成果:下一代 MTIA(Meta Training and Inference Accelerator),其中 MTIA 是专为 Meta AI 工作负载而设计的定制芯片系列。分析认为,Meta 此举意在减少对英伟达及其他外部公司芯片的依赖。

其实,Meta 在去年就推出了第一代 MTIA,与前代相比,最新版本显著改进了性能,并有助于强化内容排名和推荐广告模型。从 Meta 官方介绍中我们可以看出,MTIA v2 目前已在其 16 个数据中心投入使用,与 MTIA v1 相比,整体性能提高了 3 倍。不过最早的 MTIA v1 预计要到 2025 年才会发布,MTIA v2 只能再等等了,但 Meta 表示这两款 MTIA 芯片现已投入生产。
从下图可以看到,下一代 MTIA 采用了台积电 5nm 制程工艺。

虽然 MTIA 主要用于训练排名和推荐算法,但 Meta 表示,他们的最终目标是扩展芯片的功能,用来训练如 Llama 等语言模型的生成式 AI 。

新的 MTIA 芯片从根本上专注于提供计算、内存带宽和内存容量的适当平衡。该芯片将拥有 256MB 片上内存,频率为 1.3GHz,而 v1 的片上内存为 128MB 和 800GHz。有消息称,Meta 致力于 MTIA v2 研究已有一段时间了,该项目内部代号为 Artemis。

新一代芯片的最新加速器由 8x8 个处理元件 (PE) 组成。这些 PE 显着提高了密集计算性能(比 MTIA v1 提高了 3.5 倍)和稀疏计算性能(提高了 7 倍)。这些提高一部分归功于架构的改进,另一部分归功于 PE 网格供电方式:Meta 将本地 PE 存储的大小增加了两倍,将片上 SRAM 增加了一倍,将其带宽增加了 3.5 倍,并将 LPDDR5 的容量增加了一倍。
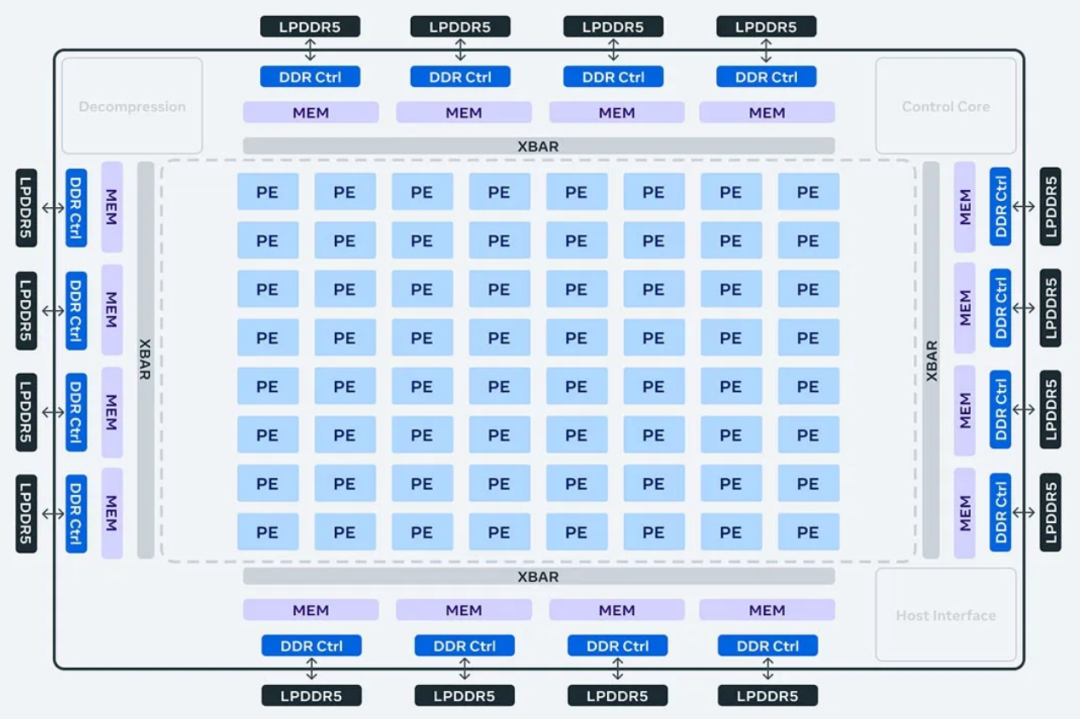
最新版本的 MTIA 设计方式还采用改进的片上网络 (NoC) 架构,使带宽加倍,并允许以低延迟的方式在不同 PE 之间进行协调。
硬件系统
高效地为工作负载提供服务不单单是芯片的挑战,共同设计硬件系统和软件堆栈对于整体推理解决方案的成功同样至关重要。

为了支持下一代 MTIA 芯片,Meta 开发了一个大型机架式系统,最多可容纳 72 个加速器。该系统由三个机箱组成,每个机箱包含 12 个板,每个板上有两个加速器。
为此,Meta 专门设计了该系统,以便将芯片的时钟频率设置为 1.35GHz(从 800MHz 开始提高),并以 90 瓦的功率运行,而第一代的设计功耗为 25 瓦。Meta 的设计确保提供更密集的功能以及更高的计算、内存带宽和内存容量。这种密集性使得可以更轻松地适应各种复杂性和尺寸的模型。

此外,Meta 还将加速器之间、主机与加速器之间的结构升级到 PCIe Gen5,以提高系统的带宽和可扩展性。如果选择横向扩展至机架之外,还能添加一个 RDMA NIC。
软件堆栈
从投资 MTIA 之初起,软件就一直是 Meta 重点关注的领域之一。作为 PyTorch 的最初开发者,Meta 非常重视可编程性和开发效率。
在设计时,MTIA 堆栈旨在与 PyTorch 2.0 以及 TorchDynamo 、TorchInductor 等功能完全集成。同时,前端图形级捕获、分析、转换和提取机制(比如 TorchDynamo、torch.export 等)与 MTIA 无关,并正在被重新使用。
此外, MTIA 的较低级别编译器从前端获取输出并生成高效且设备特定的代码。该编译器本身由几个组件组成,分别负责为模型和内核生成可执行代码。
下图为负责与驱动程序 / 固件连接的运行时堆栈。MTIA Streaming 接口抽象提供了推理和(未来)训练软件管理设备内存以及在设备上运行算子、执行编译图所需要的基本和必要操作。
最后,运行时与用户空间中的驱动程序进行交互,Meta 做出这一决定是为了能够在生产堆栈中更快地迭代驱动程序和固件。
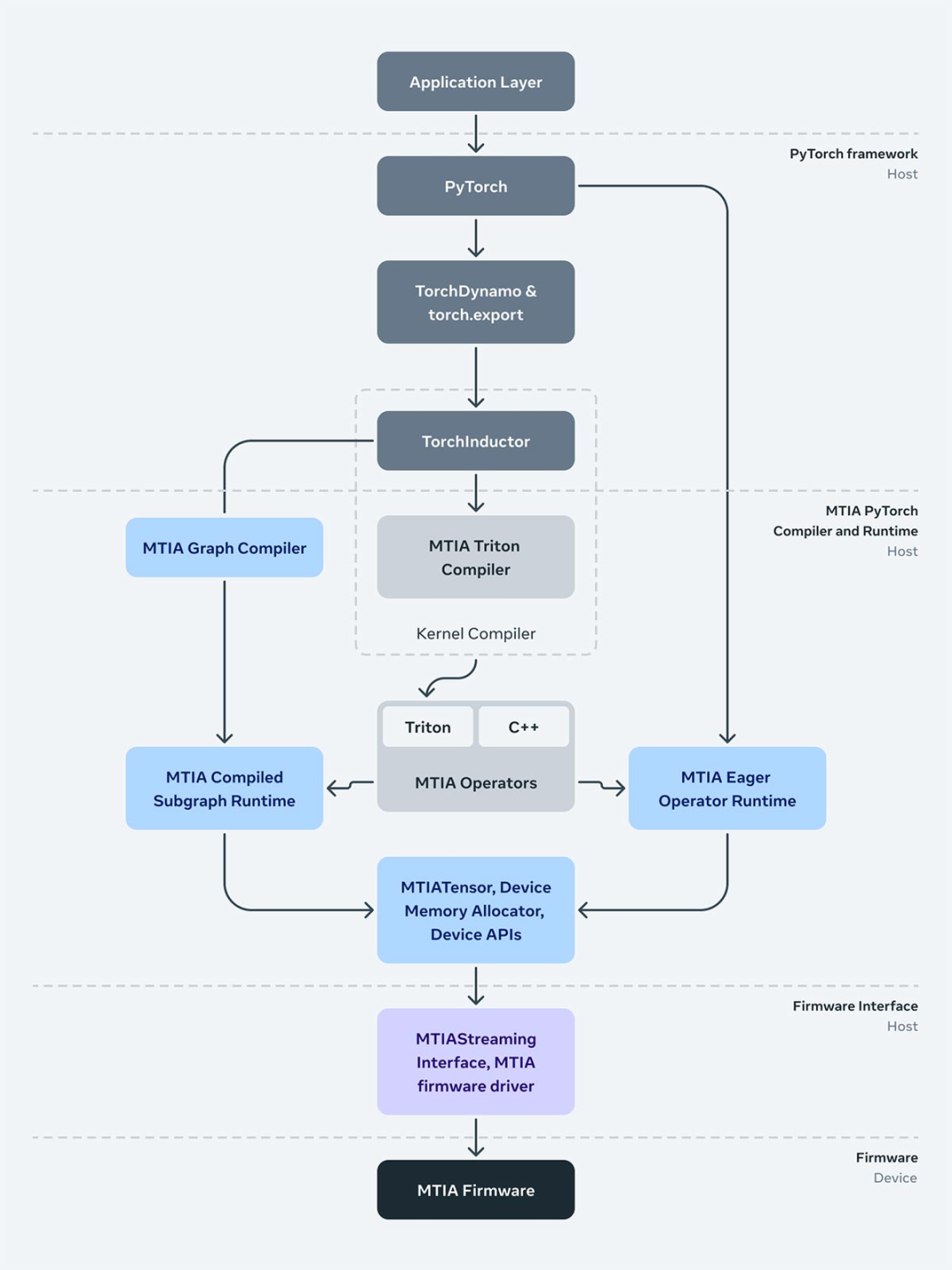
在许多方面,这一全新芯片系统运行软件堆栈的方式与 MTIA v1 类似,使得团队的部署速度更快,其中 Meta 已经完成了在该架构上运行应用程序所需的大部分必要的集成和开发工作 。
下一代 MTIA 旨在兼容为 MTIA v1 开发的代码。由于 Meta 已经将完整的软件堆栈集成到芯片中,因此在几天内就可以使用这款新芯片启动并运行流量。这使得 Meta 能够快速落地下一代 MTIA 芯片,在不到 9 个月的时间内从推出首个芯片到在 16 个数据中心运行生产模型。
Triton-MTIA 编译器后端
Meta 通过创建 Triton-MTIA 编译器后端来为 MTIA 硬件生成高性能代码,从而进一步优化了软件堆栈。作为一种开源语言和编译器,Triton 用于编写高效的机器学习计算内核,可以提高开发人员编写 GPU 代码的效率。Meta 发现 Triton 语言与硬件无关,足以适用于 MTIA 等非 GPU 硬件架构。
此外,Triton-MTIA 后端执行优化后,可以最大限度地提高硬件利用率并支持高性能内核。
Meta 实现了对 Triton 语言功能的支持并集成到 PyTorch 2 中,为 PyTorch 算子提供了广泛的覆盖。例如,借助 TorchInductor,开发人员可以在提前 (AOT) 和即时 (JIT) 工作流程中利用 Triton-MTIA。
Meta 还观察到,Triton-MTIA 显著提高了开发人员的效率,能够扩展计算内核的编写范围,并大大扩展对 PyTorch 算子的支持。
性能结果
目前的结果表明,下一代 MTIA 芯片可以处理 Meta 产品组件中的低复杂性 (LC) 和高复杂性 (HC) 排序和推荐模型。在这些模型中,模型大小和每个输入样本的计算量可能存在 10 倍到 100 倍的差异。
由于 Meta 控制整个堆栈,因此相较于商用 GPU 可以实现更高的效率。实现这些收益需要持续的努力,随着在系统中构建和部署 MTIA 芯片,Meta 将继续提高每瓦性能。
早期结果表明,在 Meta 评估的四个关键模型中,下一代 MTIA 的性能比第一代芯片提高了 3 倍。在平台层面,与第一代 MTIA 系统相比,凭借 2 倍的设备数量和强大的 2-socket CPU,Meta 能够实现 6 倍的模型服务吞吐量和 1.5 倍的每瓦性能提升。
为了实现这些目标,Meta 在优化内核、编译器、运行时和主机服务堆栈方面取得了重大进展。随着开发者生态系统的成熟,优化模型的时间正在缩短,但未来提高效率的空间更大。
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注