文章目录
- 一、Erlang 简介
- 二、数据结构
- 2.1、元组(Tuple)
- 2.1.1、示例:
- 2.1.2、实现:
- 2.2、列表(List)
- 2.2.1、示例
- 2.2.2、实现
- 2.2.3、原理
- 3. 字典(Dictionary)
- 3.1、创建字典
- 3.2、添加和删除键值对
- 3.3、获取值
- 3.4、检查键是否存在
- 3.5、获取字典大小
- 3.6、遍历字典
- 3.7、合并字典
- 3.8、获取所有键
- 3.9、获取所有值
- 4. 集合(Set)
- 4.1、创建集合
- 4.2、添加元素
- 4.3、删除元素
- 4.4、判断元素是否存在
- 4.5、获取集合大小
- 4.5、并集
- 4.6、交集
- 4.7、差集
- 4.8、遍历集合
- 结论
一、Erlang 简介
Erlang 是一种函数式编程语言,它具有强大的并发和分布式编程能力。在 Erlang 中,常用的数据结构包括元组(tuple)、列表(list)、字典(dictionary)和集合(set)。这些数据结构在 Erlang 中被广泛应用于不同的场景中,例如存储和处理数据、通信和消息传递等。在本文中,我们将深入探讨这些常用数据结构的特点和实现方式。
二、数据结构
2.1、元组(Tuple)
元组是一种不可变的有序集合,通常用于存储固定数量的数据项。在 Erlang 中,元组用大括号 {} 表示,其中的元素之间用逗号 , 分隔。元组的元素可以是任何类型的数据,包括原子、整数、浮点数、字符串等。
2.1.1、示例:
Tuple = {1, atom, "hello", 3.14}.
2.1.2、实现:
Erlang 中的元组是不可变的,即一旦创建就不能修改。可以使用模式匹配来访问元组中的元素,也可以使用内置函数来操作元组,如 tuple_size/1 获取元组的大小,element/2 获取元组中指定位置的元素等。
Tuple = {1, atom, "hello", 3.14},
Size = tuple_size(Tuple), % 获取元组大小
Element = element(2, Tuple). % 获取第二个元素
2.2、列表(List)
列表是一种可变的有序集合,用于存储可变数量的数据项。在 Erlang 中,列表用方括号 [] 表示,其中的元素之间用逗号 , 分隔。列表的元素可以是任何类型的数据,也可以包含其他列表。
2.2.1、示例
List = [1, 2, 3, 4, 5].
2.2.2、实现
Erlang 中的列表是可变的,可以使用模式匹配和内置函数来操作列表。常见的列表操作包括添加元素、删除元素、查找元素、列表推导等。
List = [1, 2, 3, 4, 5],
Head = hd(List), % 获取列表的第一个元素
Tail = tl(List), % 获取列表的尾部
Length = length(List). % 获取列表的长度
2.2.3、原理
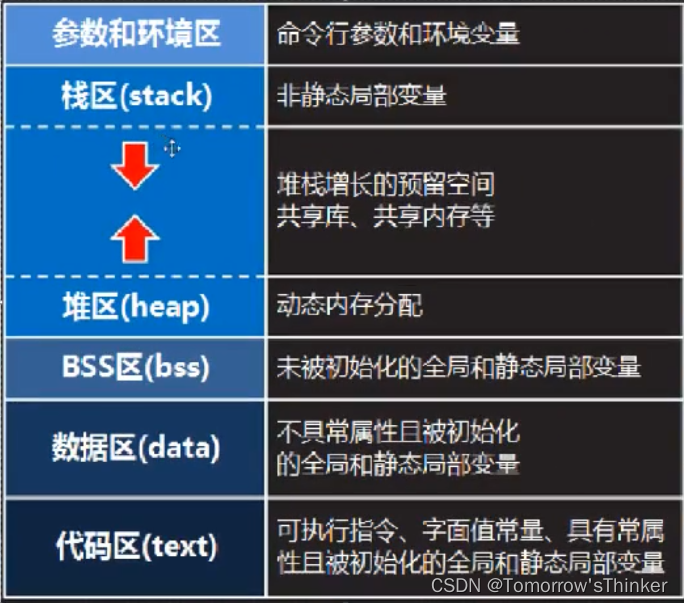
下面举个例子,假设我们有这样一个列表:L = [1,2,ok,done],现在暂时用这个简单的列表来作为示例,这个列表在进程内的示意图如下所示:
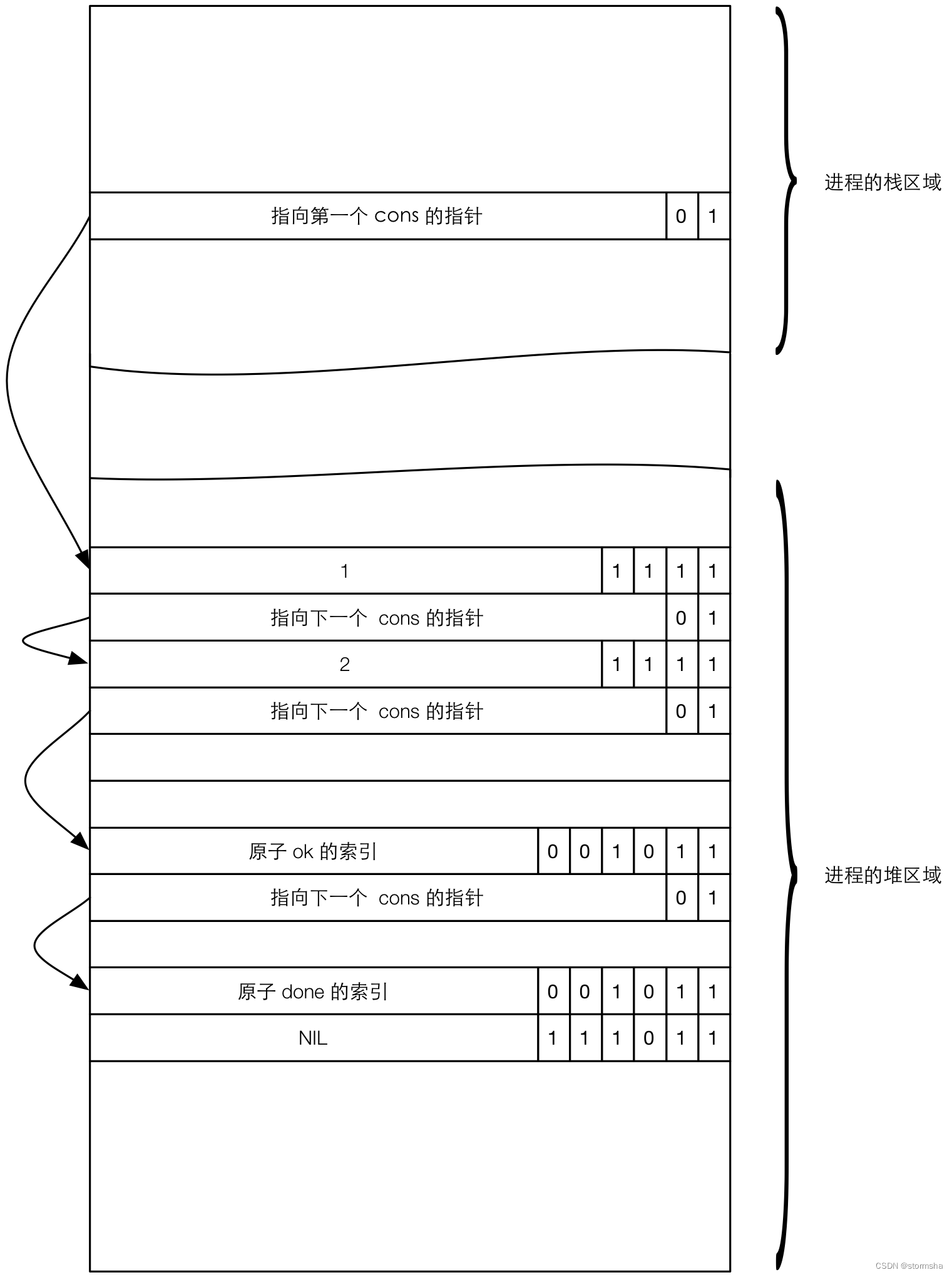
在构造一个新的列表的时候,如果新的列表引用了其他列表,那么引用了其他列表的元素本身就是一个 Cons 单元格。例如,我们有下面两个列表:
L1 = [1, 2, 3].
L2 = [L1, L1, L1]
L2 中存在 3 个对 L1 的引用,Erlang 可以很聪明地复用 L1,内存中实际上只有一份对 L1 的拷贝,如下图所示:
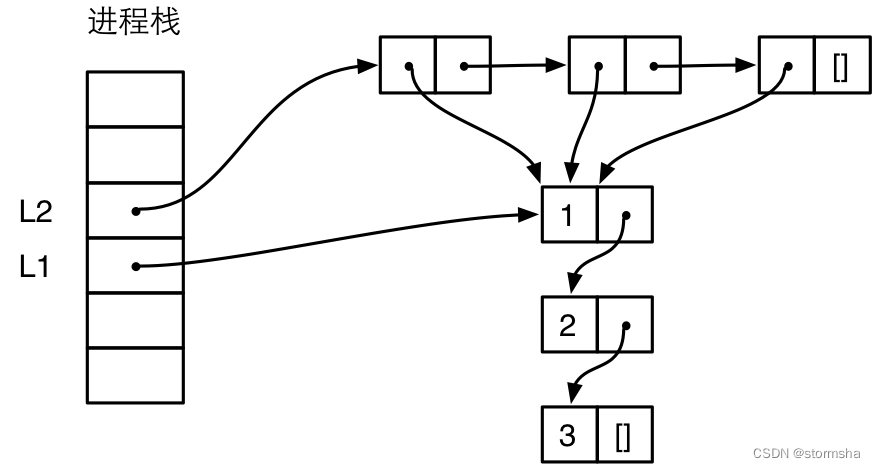
为了简洁,这个图相比前一个图简化了,不再严格表示栈和堆的相对位置,不再严格表示 Eterm 的标签。从图中可以看到,列表 L2 中的 3 个 cons 单元格都引用了 L1。
3. 字典(Dictionary)
在 Erlang 中,字典(Dictionary)是一种键值对的数据结构,也称为关联数组或映射。字典允许您通过键来检索和存储值,它是一种非常灵活和实用的数据结构。在 Erlang 中,字典通常使用 dict 模块来实现,该模块提供了一组函数来创建、操作和查询字典。
3.1、创建字典
在 Erlang 中创建字典可以使用 dict:new/0 函数,也可以使用 dict:from_list/1 函数从列表中创建。
Dict1 = dict:new().
Dict2 = dict:from_list([{key1, value1}, {key2, value2}, {key3, value3}]).
3.2、添加和删除键值对
使用 dict:store/3 函数可以向字典中添加新的键值对,使用 dict:erase/2 函数可以删除指定键的键值对。
NewDict = dict:store(Key, Value, Dict).
NewDict = dict:erase(Key, Dict).
3.3、获取值
可以使用 dict:find/2 函数通过键来获取字典中对应的值。
{ok, Value} = dict:find(Key, Dict).
3.4、检查键是否存在
使用 dict:is_key/2 函数可以检查字典中是否存在指定的键。
Result = dict:is_key(Key, Dict).
3.5、获取字典大小
可以使用 dict:size/1 函数获取字典的大小,即键值对的数量。
Size = dict:size(Dict).
3.6、遍历字典
Erlang 中遍历字典可以使用递归或者列表推导式等方式,也可以使用 dict:fold/3 函数。
Sum = dict:fold(fun(_, Value, Acc) -> Value + Acc end, 0, Dict).
3.7、合并字典
使用 dict:merge/3 函数可以将两个字典合并为一个新的字典。
MergedDict = dict:merge(Dict1, Dict2, fun(_Key, Val1, Val2) -> Val1 end).
3.8、获取所有键
使用 dict:keys/1 函数可以获取字典中所有的键。
Keys = dict:keys(Dict).
3.9、获取所有值
使用 dict:values/1 函数可以获取字典中所有的值。
Values = dict:values(Dict).
4. 集合(Set)
在 Erlang 中,集合(Set)是一种无序的数据结构,用于存储一组唯一的元素。集合的特点是元素的唯一性和无序性,这使得它适用于许多场景,例如去重、集合操作(如并集、交集、差集等)等。在 Erlang 中,集合通常使用 sets 模块来实现,该模块提供了一组丰富的函数来操作集合。
4.1、创建集合
在 Erlang 中创建集合通常使用 sets:from_list/1 函数,该函数接受一个列表作为参数,并返回一个集合。
Set = sets:from_list([1, 2, 3, 4, 5]).
4.2、添加元素
可以使用 sets:add/2 函数向集合中添加元素。
NewSet = sets:add(6, Set).
4.3、删除元素
使用 sets:del/2 函数可以从集合中删除指定元素。
NewSet = sets:del(3, Set).
4.4、判断元素是否存在
使用 sets:is_element/2 函数可以判断集合中是否存在指定元素。
Result = sets:is_element(3, Set).
4.5、获取集合大小
使用 sets:size/1 函数可以获取集合的大小。
Size = sets:size(Set).
Erlang 的 sets 模块还提供了一些集合操作函数,如并集、交集、差集等。
4.5、并集
使用 sets:union/2 函数可以计算两个集合的并集。
UnionSet = sets:union(Set1, Set2).
4.6、交集
使用 sets:intersection/2 函数可以计算两个集合的交集。
IntersectionSet = sets:intersection(Set1, Set2).
4.7、差集
使用 sets:subtract/2 函数可以计算两个集合的差集。
DifferenceSet = sets:subtract(Set1, Set2).
4.8、遍历集合
Erlang 中遍历集合可以使用递归或者列表推导式等方式,也可以使用 sets:fold/3 函数。
Sum = sets:fold(fun(Elem, Acc) -> Elem + Acc end, 0, Set).
结论
在 Erlang 中,元组、列表、字典和集合是常用的数据结构,它们分别适用于不同的场景和需求。掌握这些数据结构的特点和实现方式,有助于编写高效、可靠的 Erlang 代码。在实际开发中,根据具体的问题和需求,选择合适的数据结构来存储和处理数据,可以提高代码的可读性和性能。