你是否希望掌握大模型开发的秘诀?你是否渴望得到实践操作的机会?如果你的心中充满热情和期待,那么,WAVE SUMMIT 2023特别设置的Workshop将会是你的知识启航站!
本次Workshop专注于AI开发与大模型应用,邀请一线优秀的AI软件工程师和产品专家,分享他们的技术心得,带领每一位参与者深入了解AI的最新动态。在这里,你可以学到熟练AI开发的独到方法,掌握大模型应用的关键技术。WAVE SUMMIT 2023Workshop将为您提供独一无二的学习、交流和探索机会,助您加速AI技术的发展和应用。

课程详情

大模型应用开发部署全流程实践
活动时间
13:00-13:45
活动地点
展区Workshop
活动内容
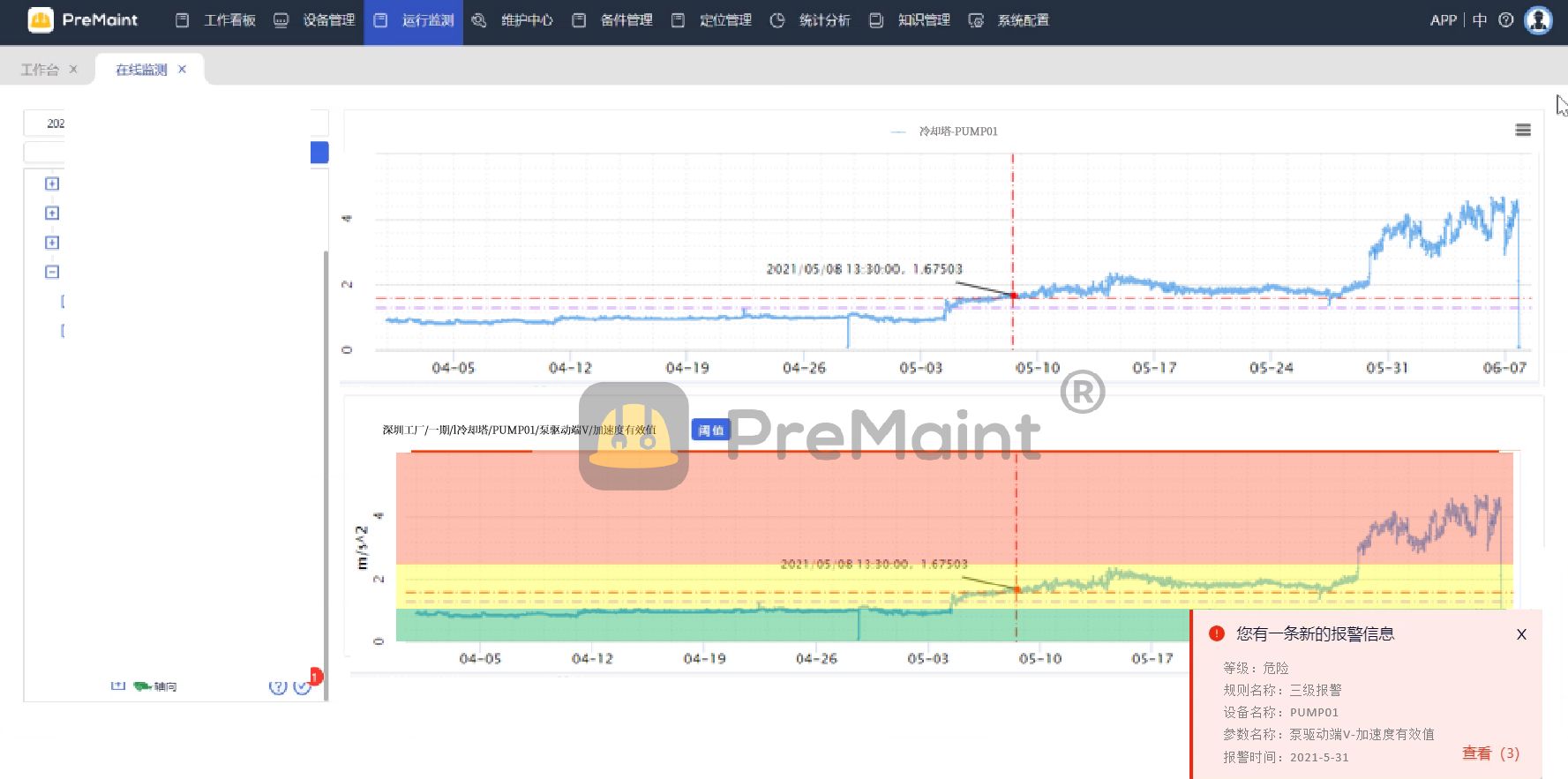
AI Studio应用中心是一个模型效果体验展示平台,开发者可通过简单的代码操作将模型部署为可直接体验的应用。在AI Studio平台,开发者可以一站式开发大模型应用。AI Studio平台覆盖全AI领域模型内容资源,可一键进入线上开发环境,具备云端强大算力支持,支持在线直接将模型部署为可视化体验的应用。在本次Workshop中,AI Studio产品经理将从0到1带你了解上手大模型应用开发全流程,构建创新应用。
AI Studio 项目开发介绍
基于AI Studio SDK与飞桨开源套件的项目开发
基于Gradio的应用界面开发和部署
上机体验:AI Studio 精选应用体验
上机操作:
AI Studio 项目新建
快速安装 AI Studio SDK 和飞桨模型套件
notebook 快速开发 prompting chaining 和模型推理
基于 gradio 的界面开发和调试
应用部署
主讲人介绍

熊斯衍
百度飞桨AI Studio 产品负责人

施依欣
百度飞桨产品经理

Al Studio零代码大模型开发实践
活动时间
15:40-16:25
活动地点
展区Workshop
活动内容
AI Studio大模型社区全新上线。在大模型社区,与众多大模型同好实时交流、体验与生产大模型相关应用。同时,只需要简单三步,开发者就可以创建大模型应用,这个过程中,无需具备代码基础,只要有想法和相关数据,就可以「无痛」进行应用的创建。在本次workshop中,AI Studio产品经理将对大模型社区进行介绍并现场演示如何基于文心大模型打造生成式对话应用。
AI Studio 大模型社区介绍
进阶 Prompting 开发范式
知识问答和角色扮演中的常见错误和处理方式
上机体验:AI Studio 社区体验
上机操作:
快速搭建AI原生应用
Prompt 工程快速入门
应用效果迭代优化
数据预处理和挂载
常见 pitfalls 和处理方式
主讲人介绍

熊斯衍
百度飞桨AI Studio 产品负责人

施依欣
百度飞桨产品经理

动手体验语音AI开发利器- NVIDIA NeMo 代码实战
活动时间
13:00-13:45
活动地点
「携手飞桨 创新加速」分论坛
活动内容
NVIDIA NeMo 是一个用于构建对话式人工智能应用的开源工具库。它采用语音文本数据为输入,使用人工智能和自然语言处理模型理解语义,从而实现语音与文字间内容的相互转换。NeMo toolkit 可用于构建人与机器进行语音文字交互的对话式解决方案,用于搭建智能语音助手,聊天机器人,智能语音翻译,声控智能家居及无人驾驶汽车语音指令交互等应用场景。本次活动将重点介绍如何使用 NeMo 训练自定义语音AI模型,同时上机操作体验在边缘计算设备 Jetson NX 中实现语音AI模型的推理。
NVIDIA NeMo 介绍
构建适用于 NeMo 的语音数据集
使用 NeMo 训练ASR语音识别模型方法
使用 NeMo 训练TTS语音合成模型方法
上机体验:
在 Jetson NX 边缘计算设备上实现语音AI模型推理
上机操作:
以 Jetson NX 作为实验硬件平台
以 Jupyter Lab 作为实验开发工具
线上远程网络连接对应IP端口进行登录
动手体验 NeMo 代码实战
主讲人介绍

Yipeng Li 李奕澎
NVIDIA 企业级开发者社区经理
拥有多年数据分析建模、人工智能自然语言处理开发经验。在自动语音识别、自然语言处理、语音合成等对话式AI技术领域有丰富的实战经验与见解。曾开发法律、金融、保险文档中基于实体抽取的智能问答系统,曾开发基于NLP知识抽取,KG知识图谱的建立的科研文档智能检索系统。

LLM高速推理引擎在Intel® Xeon® CPU的使用实践
活动时间
13:00-13:45
活动地点
「产教融合 人才共育」分论坛
活动内容
xFasterTransformer是一个针对Intel Xeon CPU平台高度优化的大语言模型(LLM)推理引擎。它兼容huggingface以及NVIDIA FT等主流的模型格式,支持OPT,LLAMA,ChatGLM,Falcon等多种主流大语言模型在FP16/BF16/INT8数据格式的推理,可以充分利用Xeon CPU平台上的硬件feature进行加速,并具有良好的跨节点可扩展性。本次活动将介绍xFasterTransformer的核心架构和技术实现,并展示其在Intel Xeon SPR平台上的卓越的推理性能,实践体验如何使用xFasterTransformer在Xeon CPU平台上加速大模型推理计算。
xFasterTransformer架构和实现介绍
Intel SPR/HBM 硬件平台介绍
上机体验:远程SPR-HBM服务器上实现CPU平台大模型的高速推理实操
上机操作:远程Intel Xeon SPR-HBM为实验硬件平台, 动手体验用xFasterTransformer加速LLM推理实战
主讲人介绍

孟晨
Intel 高级AI软件工程师
从事深度学习计算框架和高性能计算等领域研发工作,具有深厚的AI知识积累。作为PaddlePaddle的contributor,在分布式训练和推理的开发和性能优化方向具有丰富的实战经验。

温馨提示
现场位置有限,建议提前5-10分钟到场。
请携带笔记本电脑到场,如续航较短建议携带充电器。
请提前注册飞桨AI Studio账号并完善个人信息。

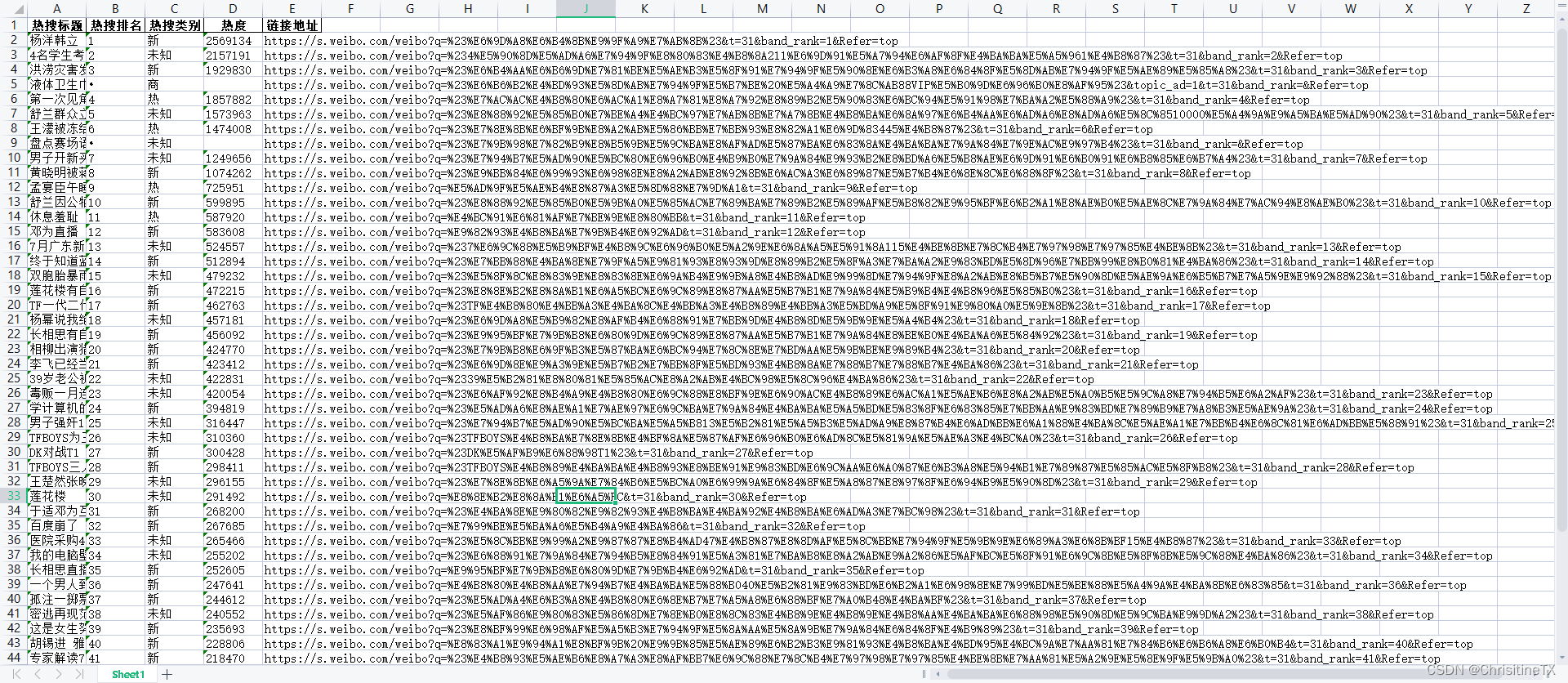
workshop课程表

扫描上方二维码报名,到场即刻上手AI原生应用。请关注WAVE SUMMIT 2023官方网站及社交媒体渠道,获取最新的峰会信息和报名通知。让我们一起开启AI的未来,探索大模型的无限可能。我们期待您的到来,启程属于您的AI之旅,共享知识与创新的盛宴!





关注【飞桨PaddlePaddle】公众号
获取更多技术内容~