目录
一.环境安装
1.cuda/cudnn安装:
2.Pytorch,torchvision安装
3. TensorRT安装C++版本:
4.onnxRuntime安装:
二.基础知识
1.Onnx、onnxTime、wts和TensorRT
2. 模型部署
3. 深度学习简介
4. Loss函数
5. 激活函数
一.环境安装
1.cuda/cudnn安装:
安装cuda之前首先安装vs,vs版本从低到高安装。
a) 安装cuda:首先查看显卡支持的最高CUDA的版本,以便下载对应的CUDA安装包;
cmd命令行:nvidia-smi,显示如下:最高版本为12.2,

在NVIDIA官方网站即可下载,地址为:https://developer.nvidia.com/cuda-toolkit-archive
无坑,双击exe选择安装目录即可,C盘有空间尽量C盘安装;安装完成使用nvcc -V确认安装成功
b) cudnn:cudnn版本选择对应支持的较高版本即可;非常简单,将bin,include,lib三个文件夹拷贝到cuda安装目录下对应的文件夹里面,下载地址:cuDNN Archive | NVIDIA Developer
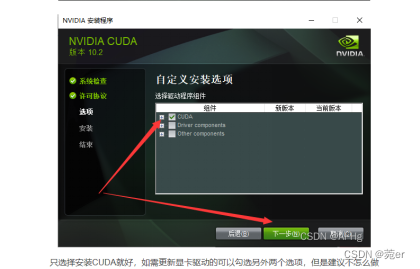
c)多版本cuda:按照ab下载对应版本,安装cuda时只选择安装CUDA组件即可,之后在环境变变量path中将优先使用的cuda放置到最前面;
2.Pytorch,torchvision安装
使用conda创建虚拟环境,conda create -n py39 ,激活环境,activate py39
之后根据自己的环境进行安装,不要瞎搜索,根据官网的命令,地址:
https://pytorch.org/get-started/previous-versions/
选择符合自己环境的,比如1.10,按照如下命令即可。
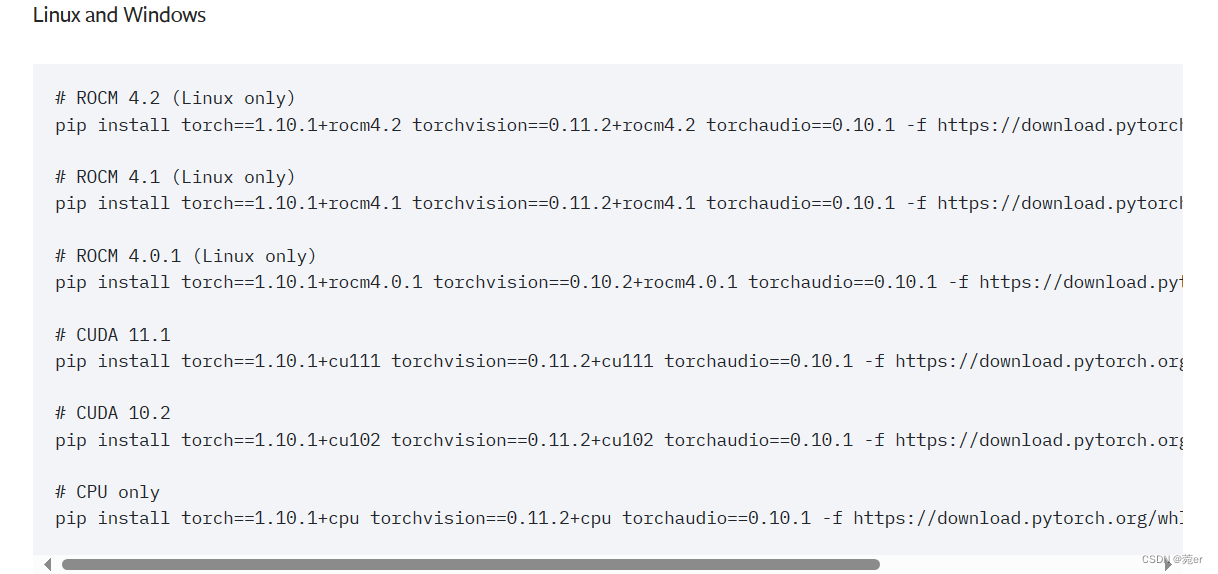
下载较慢时,可以使用阿里的源:
pytorch-wheels-cu117安装包下载_开源镜像站-阿里云 (aliyun.com)
3. TensorRT安装C++版本:
1)安装很简单,下载解压即可;下载地址:https://developer.nvidia.com/tensorrt/download

根据自己的环境进行选择,比如我选择TensorRT8.6 ,GA是稳定版本,

2)VS2019配置
此处对sampleMNIST示例进行测试,进入到D:\tensorrt_tar\TensorRT-xxxx\samples\sampleMNIST目录下,选择sample_mnist.sln文件—>右键点击打开方式—>选择Microsoft Visual Studio 2019打开文件
然后依次点击 项目—>属性—>VC++目录
将路径D:\tensorrt_tar\TensorRT-xxx\lib分别加入可执行文件目录及库目录里
将D:\tensorrt_tar\TensorRT-xxxx\include加入C/C++ —> 常规 —> 附加包含目录
将D:\tensorrt_tar\TensorRT-xxx\lib\*.lib加入链接器–>输入–>附加依赖项
有说将lib、include拷贝到cuda文件夹中,个人建议,直接配置即可;
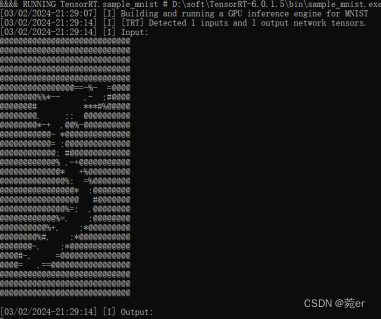
3)进行测试
在VS2019中,将sample_mnist项目选中右键执行生成,直接运行出现以下内容表示成功运行;
4.onnxRuntime安装:
onnxRuntime搜索到的vs2019的配方式,个人建议直接从官网下载编译好的包,下载地址:https://github.com/microsoft/onnxruntime/releases,根据需求选择不同版本,这里我的cuda是11.1,选择1.8.1;

然后配置如下:

之后在vs2019中使用即可,注意,最好将onnxruntime.dll放在release下边,因为通常会有多个onnxruntime.dll,如果dll路径不对就导致无法运行,如下错误:

python安装路径:

二.基础知识
1.Onnx、onnxTime、wts和TensorRT
onnx和onnxTime的关系:训练模型时有不同框架,Pytroch,TensorFlow等,这样不同的框架就导致产生不同的模型结果包,在模型进行部署推理时就需要不同的依赖库,而且同一个框架不同版本之间的差异较大。为了解决这个混乱问题,LFAI联合Facebook,MicroSoft等公司指定了机器学习模型的标准,这个标准叫做Onnx,Open Neural Network Exchange,所有其他框架产生的模型包都可以转换成这个标准格式,转换成个标准格式后就可以统一使用onnx Runtime等工具进行部署,简言之,onnx用于转换格式,onnx runtime用于部署。
TensorRT:TensorRT可以在Nvidia各种GPU平台下运行的一个C++推理框架,利用Pytorch或者其他框架训练好的模型可以转化为TensorRT格式,利用TensorRT推理引擎运行这个模型,从而提升这个模型在Nvidia GPU上运行速度,核心代码是C++/CUDA。TensorRT所做的优化是基于GPU进行优化,对于通道较多的卷积层和反卷积层,优化力度比较大,如果是复杂的细小的op操作,性能没有那么高了,大而整”的GPU运算效率远超“小而碎”的运算。主要优化的操作有算子融合、动态显存分配、精度校准、多stream流、自动调优等。
2. 模型部署
难点:开发完毕的软件投入使用的过程,包括环境配置、软件安装等过程成为部署。对于AI,模型部署过程就是将训练好的模型在特定环境中运行的过程。AI模型部署的主要难点是,模型主要是一个框架编写,Pytroch等,这些框架不适合在生产环境中安装;模型结构通常比较庞大,运行效率需要优化。
部署流水线:深度学习框架Pytorch/TF【训练】-->中间模型ONNX【优化】-->推理引擎TensorRT/OnnxRuntime/OpenVINO【运行】
这个流水线解决了模型部署中的两个问题,使用对接深度学习框架和推理引擎的中间表示,不同担心复杂框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
部署方式有:DNN/ONNXRuntime/TensorRT/OpenVINO,具体过程:模型初始化、输入数据前处理、输入数据从内存拷贝到cuda显存、执行推理、推理结果从cuda显存拷贝内存、推理结果后处理。GPU加速首选TensorRT;CPU加速首选OpenVINO,多图并行推理可以选OnnxRuntime;兼具CPU和GPU推理,可选择ONNXRuntime。