今天给大家分享黏菌优化算法优化CNN-BiLSTM的时序预测,主要从算法原理和代码实战展开。需要了解更多算法代码的,可以点击文章左下角的阅读全文,进行获取哦~需要了解智能算法、机器学习、深度学习和信号处理相关理论的可以后台私信哦,下一期分享的内容就是你想了解的内容~
代码实战
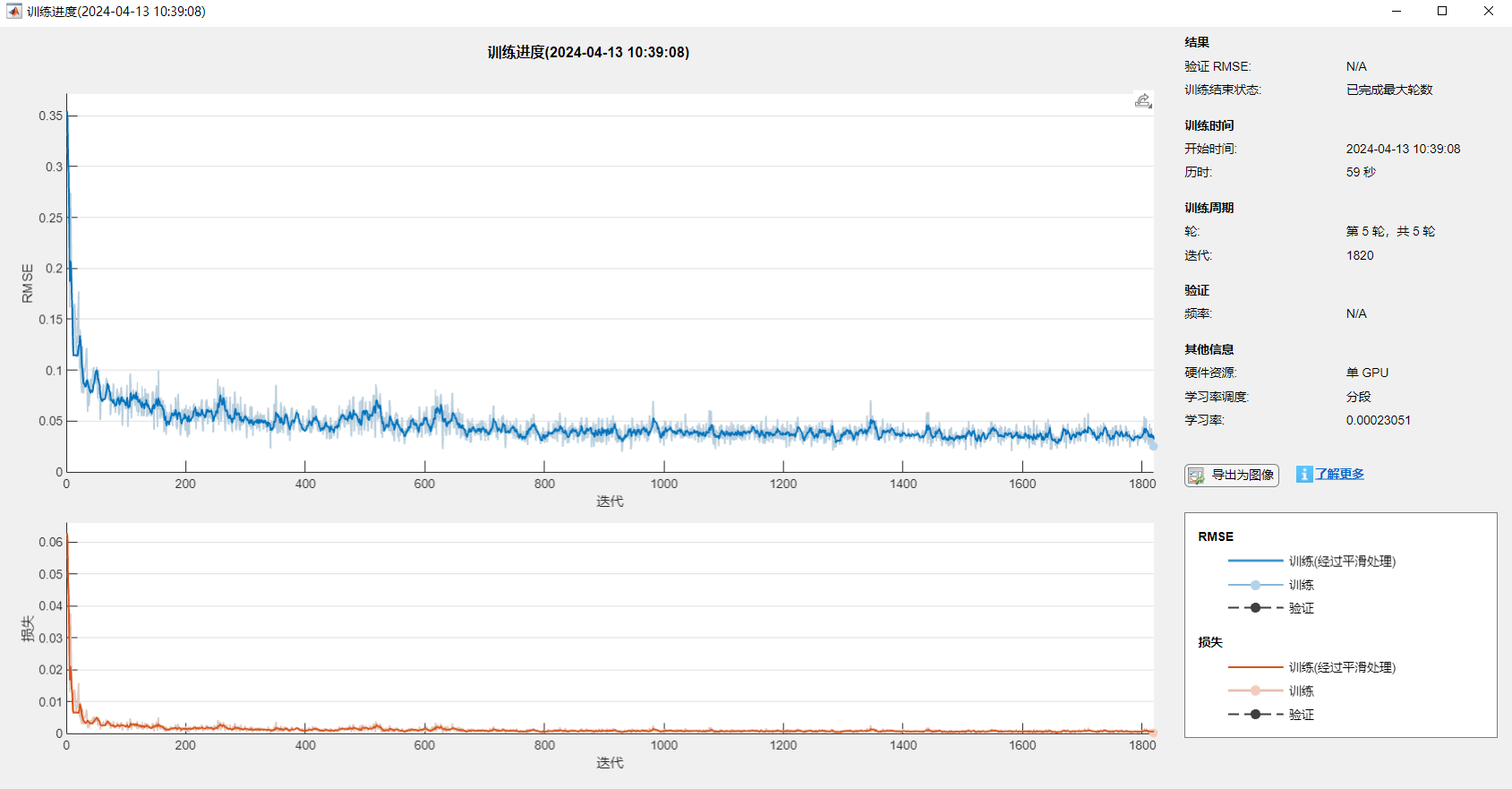
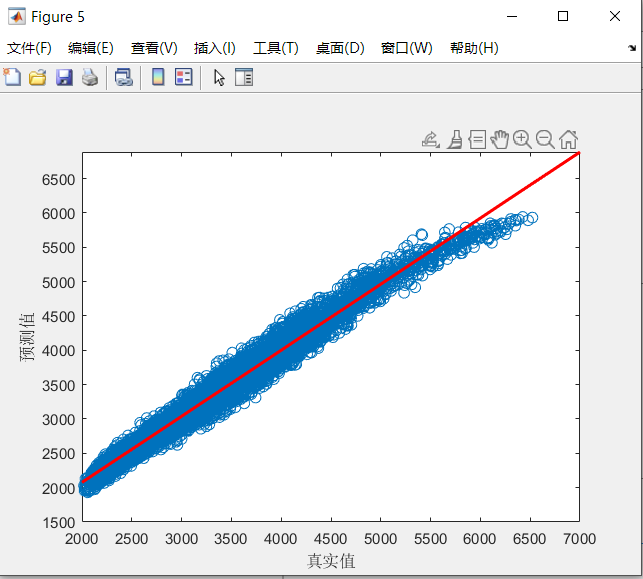
%% SMA-CNN-LSTM负荷预测% 数据集(列为特征,行为样本数目clcclearload('Train.mat')%Train(1,:) =[];y = Train.demand;x = Train{:,3:end};[xnorm,xopt] = mapminmax(x',0,1);[ynorm,yopt] = mapminmax(y',0,1);x = x';k = 24; % 滞后长度% 转换成2-D imagefor i = 1:length(ynorm)-kTrain_xNorm{i} = reshape(xnorm(:,i:i+k-1),6,1,1,k);Train_yNorm(i) = ynorm(i+k-1);Test_x(i) = y(i+k-1);endTrain_yNorm= Train_yNorm';%%load('Test.mat')Test(1,:) =[];ytest = Test.demand;xtest = Test{:,3:end};[xtestnorm] = mapminmax('apply', xtest',xopt);[ytestnorm] = mapminmax('apply',ytest',yopt);xtest = xtest';for i = 1:length(ytestnorm)-kTest_xNorm{i} = reshape(xtestnorm(:,i:i+k-1),6,1,1,k);Test_yNorm(i) = ytestnorm(i+k-1);Test_y(i) = ytest(i+k-1);endTest_yNorm = Test_yNorm';% LSTM 层设置,参数设置inputSize = size(Train_xNorm{1},1); %数据输入x的特征维度outputSize = 1; %数据输出y的维度%%%% 优化算法参数设置SearchAgents_no = 10; % 数量Max_iteration = 10; % 最大迭代次数dim = 3; % 优化参数个数lb = [1e-4,10,10]; % 参数取值下界(学习率,隐藏层节点,正则化系数)ub = [1e-3, 200,200]; % 参数取值上界(学习率,隐藏层节点,正则化系数)[Best_score,Best_pos,curve]=SMA(SearchAgents_no,Max_iteration,lb,ub,dim,fit)best_lr = Best_pos(1); % 最佳隐藏层节点数numhidden_units1 = round(Best_pos(2));% 最佳隐藏层节点数1numhidden_units2 = round(Best_pos(3));% 最佳隐藏层节点数2%% lstmlayers = [ ...sequenceInputLayer([inputSize,1,1],'name','input') %输入层设置sequenceFoldingLayer('name','fold')convolution2dLayer([2,1],10,'Stride',[1,1],'name','conv1')batchNormalizationLayer('name','batchnorm1')reluLayer('name','relu1')maxPooling2dLayer([1,3],'Stride',1,'Padding','same','name','maxpool')sequenceUnfoldingLayer('name','unfold')flattenLayer('name','flatten')bilstmLayer(numhidden_units1,'Outputmode','sequence','name','hidden1')dropoutLayer(0.3,'name','dropout_1')bilstmLayer(numhidden_units2,'Outputmode','last','name','hidden2')dropoutLayer(0.3,'name','drdiopout_2')fullyConnectedLayer(outputSize,'name','fullconnect') % 全连接层设置(影响输出维度)(cell层出来的输出层) %tanhLayer('name','softmax')regressionLayer('name','output')];lgraph = layerGraph(layers)lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');% plot(lgraph)%% 网络训练options = trainingOptions('adam', ...'MaxEpochs',5, ...'GradientThreshold',1,...'ExecutionEnvironment','gpu',...'InitialLearnRate',best_lr, ...'LearnRateSchedule','piecewise', ...'LearnRateDropPeriod',2, ... %2个epoch后学习率更新'LearnRateDropFactor',0.5, ...'Shuffle','once',... % 时间序列长度'SequenceLength',k,...'MiniBatchSize',24,...'Plots', 'training-progress',... % 画出曲线'Verbose',0);%% 训练[net,traininfo] = trainNetwork(Train_xNorm, Train_yNorm, lgraph, options);%% 预测t_sim1 = predict(net, Train_xNorm);t_sim2 = predict(net, Test_xNorm);%% 数据反归一化T_sim1 = mapminmax('reverse', t_sim1',yopt);T_sim2 = mapminmax('reverse', t_sim2', yopt);T_sim1 = double(T_sim1) ;T_sim2 = double(T_sim2) ;%% 绘图M = size(T_sim1,2);N = size(T_sim2,2);figureplot(1 : length(curve), curve,'linewidth',1.5);title('SMA-CNN-LSTM', 'FontSize', 10);xlabel('迭代次数', 'FontSize', 10);ylabel('适应度值', 'FontSize', 10);grid off%% 均方根误差 RMSEerror1 = sqrt(sum((T_sim1 - Test_x').^2)./M);error2 = sqrt(sum((Test_yNorm' - T_sim2).^2)./N);%% 显示网络结构analyzeNetwork(net)%% 绘图figureplot(lgraph)title("CNN-BILSTM模型结构")%% 绘图figureplot(T_sim1,'-','linewidth',1)hold onplot(Test_x,'-','linewidth',1)legend( 'SMA-CNN-LSTM拟合训练数据','实际分析数据','Location','NorthWest','FontName','华文宋体');title('SMA-CNN-LSTM模型预测结果及真实值','fontsize',12,'FontName','华文宋体')xlabel('样本','fontsize',12,'FontName','华文宋体');ylabel('数值','fontsize',12,'FontName','华文宋体');xlim([1 M])%-------------------------------------------------------------------------------------figureplot(T_sim2,'-','linewidth',1)hold onplot(Test_y,'-','linewidth',1)legend('SMA-CNN-LSTM预测测试数据','实际分析数据','Location','NorthWest','FontName','华文宋体');title('SMA-CNN-LSTM模型预测结果及真实值','fontsize',12,'FontName','华文宋体')xlabel('样本','fontsize',12,'FontName','华文宋体');ylabel('数值','fontsize',12,'FontName','华文宋体');xlim([1 N])%-------------------------------------------------------------------------------------%% 相关指标计算% R2R1 = 1 - norm(Test_x - T_sim1)^2 / norm(Test_x - mean(Test_x))^2;R2 = 1 - norm(Test_y - T_sim2)^2 / norm(Test_y - mean(Test_y))^2;disp(['训练集数据的R2为:', num2str(R1)])disp(['测试集数据的R2为:', num2str(R2)])% MAEmae1 = sum(abs(T_sim1 - Test_x)) ./ M ;mae2 = sum(abs(T_sim2 - Test_y )) ./ N ;disp(['训练集数据的MAE为:', num2str(mae1)])disp(['测试集数据的MAE为:', num2str(mae2)])% MAPEmaep1 = sum(abs(T_sim1 - Test_x)./Test_x) ./ M ;maep2 = sum(abs(T_sim2 - Test_y)./Test_y) ./ N ;disp(['训练集数据的MAPE为:', num2str(maep1)])disp(['测试集数据的MAPE为:', num2str(maep2)])% RMSERMSE1 = sqrt(sumsqr(T_sim1 - Test_x)/M);RMSE2 = sqrt(sumsqr(T_sim2 - Test_y)/N);disp(['训练集数据的RMSE为:', num2str(RMSE1)])disp(['测试集数据的RMSE为:', num2str(RMSE2)])%% 保存训练模型save ('model')
仿真结果





部分知识来源于网络,如有侵权请联系作者删除~
今天的分享就到这里了,后续想了解智能算法、机器学习、深度学习和信号处理相关理论的可以后台私信哦~希望大家多多转发点赞加收藏,你们的支持就是我源源不断的创作动力!
作 者 | 华 夏
编 辑 | 华 夏
校 对 | 华 夏