这篇论文讨论了在深度卷积网络中引入空间金字塔池化(SPP)层的方法,以解决传统深度卷积网络需要固定图像尺寸的限制。以下是论文各部分的总结:
1. 引言
论文指出现有的深度卷积神经网络(CNN)需要固定大小的输入图像,这一需求限制了图像的比例和尺度,可能会影响识别的准确性。为了解决这个问题,作者提出了一种新的网络结构——SPP-net,该网络通过空间金字塔池化层来生成固定长度的输出,使得网络可以处理任意尺寸的图像。
2. 深度网络与空间金字塔池化
这一部分详细介绍了空间金字塔池化(SPP)层的概念和实现。SPP层位于最后一个卷积层之后,通过不同级别的池化区域聚合特征,生成固定长度的输出。这样,即便输入图像的尺寸不同,网络仍可以输出统一的特征表示。
3. SPP-net用于图像分类
作者在ImageNet 2012数据集上测试了SPP-net的性能,结果显示SPP-net在多种CNN架构上都能提升分类准确率。此外,论文还展示了SPP-net在Pascal VOC 2007和Caltech101数据集上的分类结果,证明了其在这些任务上的有效性。
4. SPP-net用于对象检测
在对象检测任务中,SPP-net同样表现出色。与传统的R-CNN方法相比,SPP-net在提取特征时只需对整个图像进行一次卷积计算,显著提高了处理速度,同时保持了与R-CNN相当或更好的准确率。
5. 结论
最后,作者总结了空间金字塔池化的优势,特别是其处理不同尺度、大小和纵横比的能力,这对于视觉识别任务至关重要。论文还指出,虽然SPP-net在多个任务上都取得了良好的结果,但其真正的潜力还有待在更深更大的网络架构中进一步探索。
附录
附录部分提供了SPP-net实现的一些技术细节,包括如何处理不同大小的输入图像、如何计算池化区域等。
2 DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
2.1 Convolutional Layers and Feature Maps
传统的七层深度卷积神经网络(CNN)的结构。这种结构广泛应用于图像分类任务。这里具体解释如下:
-
七层架构: 提到的七层结构可能包含了5个卷积层和2个全连接层。在某些情况下,也可能包含池化层,但这些池化层通常被视为卷积层的一部分,因为它们也采用了滑动窗口的方式操作。
-
前五层(卷积层): 这些层通过滤波器(或称为卷积核)在输入图像上滑动,提取空间层面的特征。这些特征可以理解为图像的抽象表示,它们捕获了图像中的模式,如边缘、角落、纹理等。
-
池化层: 池化层通常位于卷积层之后,用来降低特征图的空间尺寸(高度和宽度),同时保持重要信息。这也是一种滑动窗口操作,窗口在特征图上移动,并在每个窗口内进行聚合操作(比如取最大值或平均值)。虽然池化层和卷积层在操作方式上有相似性,但池化是一种降采样过程,不涉及权重的学习。
-
后两层(全连接层): 这些层将卷积和池化层提取到的高维特征转换为一维的特征向量,然后通过学习的权重连接到更高层次的特征。全连接层是网络的决策部分,它将特征向量映射到最终的输出。
-
N-way softmax: 在网络的最后,通常会有一个softmax层,它基于全连接层的输出为每个类别分配一个概率值。这里的"N-way"指的是网络能够区分的类别数量。如果有N个类别,softmax输出一个N维的向量,向量的每个元素代表了输入图像属于每个类别的概率。
这段内容的关键点是强调传统CNN结构中的层次组织以及每种类型层的作用。当引入空间金字塔池化(SPP)层时,如论文所述,这种结构可以更加灵活地处理不同尺寸的输入图像,而不是限制在固定尺寸的输入上。这样,CNN可以接收任意大小的输入图像,并为图像分类任务生成一个固定长度的输出表示,这在很大程度上提高了网络的适应性和应用范围。
这段论文内容提供了深度网络的一些详细解释,特别是关于卷积层如何处理输入图像,以及它们与全连接层的关系。以下是对这段内容的解释:
-
固定尺寸的要求:深度网络通常需要固定尺寸的输入图像,这主要是因为网络末端的全连接层需要固定长度的输入向量。全连接层之前的所有层都可以处理任意大小的输入,但是最终的特征表示需要有一个固定的大小以便被全连接层处理。
-
卷积层的灵活性:与全连接层不同,卷积层可以接受任意尺寸的输入。卷积层使用滑动的过滤器来提取特征,并生成所谓的特征图(feature maps)。这些特征图保持了输入图像的大致纵横比,并包含了响应强度和它们在输入图像中的空间位置信息。
-
特征图的可视化:论文中的图2展示了通过卷积层的conv5过滤器产生的特征图。文中指出,不同的过滤器会对图像中的不同形状有最强的激活反应,如圆形、倒V形和V形。这表明每个过滤器学会了识别图像中特定的视觉模式。
-
特征图生成:值得注意的是,这些特征图是在没有固定输入尺寸的条件下生成的,这显示了卷积层处理不同尺寸输入的能力。
-
与传统方法的联系:作者将卷积层生成的特征图与传统计算机视觉方法中使用的特征图进行了对比。在传统方法中,SIFT向量或图像块被密集地提取出来并被编码(例如,通过向量量化、稀疏编码或Fisher核),然后聚合为特征图。这些特征图之后会被Bag-of-Words(BoW)或空间金字塔(SP)模型进一步处理。
-
深度卷积特征的类比:文章指出深度卷积特征可以以类似于空间金字塔匹配的方式被聚合。这表明,深度学习框架内的新技术和传统视觉特征提取方法之间有共同的地方,且可以互相借鉴。
总的来说,这段内容强调了深度卷积网络的一个关键特性——卷积层可以处理任意大小的输入,这为去除网络中对固定输入尺寸的需求提供了理论基础。这也说明了卷积层和全连接层之间的区别,以及如何将这种灵活性通过空间金字塔池化技术整合进深度学习模型中。
2.2 The Spatial Pyramid Pooling Layer
这段内容深入讨论了深度卷积网络(CNN)中如何通过空间金字塔池化(SPP)来处理变化尺寸的输入图像,并保持空间信息,从而生成可以由分类器处理的固定长度的特征向量。下面是对这一段内容的解释:
-
卷积层的灵活性:卷积层能够接收任意尺寸的输入,这是因为它们通过滤波器在输入图像上滑动,生成特征图,而这些特征图的尺寸随输入图像的尺寸变化而变化。
-
分类器的固定长度需求:分类器(如支持向量机SVM或softmax函数)或全连接层需要固定长度的输入向量。在传统方法中,如Bag-of-Words(BoW),通过将所有特征聚合(池化)在一起来生成固定长度的向量。
-
空间金字塔池化:SPP是BoW的改进,因为它可以通过在局部空间区间内聚合特征来保持空间信息。空间金字塔的每个层次由与图像尺寸成比例的bins组成,因此无论输入图像的大小如何,bins的数量都是固定的。
-
空间金字塔池化层的应用:为了适应任意尺寸的图像,作者提出用SPP层替换最后一个池化层。在SPP层中,每个空间bin内的每个滤波器响应都会被池化(通常使用最大值池化)。SPP层的输出是一个固定维度的向量,向量的维度由bins的数量乘以滤波器的数量得出。
-
尺寸和比例的灵活性:SPP层允许输入图像具有任意的比例和尺度。图像可以被调整到任何尺寸,应用相同的深度网络,网络将在不同尺度上提取特征。
-
尺度的重要性:在传统的图像处理方法中,尺度是非常重要的,例如SIFT特征经常在多个尺度上提取。作者将展示尺度对于深度网络准确性的重要性。
-
全局池化:文章指出,在最粗糙的金字塔层级,只有一个bin覆盖整个图像,这实际上是一个全局池化操作。全局平均池化可以减小模型大小并减少过拟合,而全局最大池化可用于弱监督物体识别。全局池化操作与传统的BoW方法相对应。
通过引入SPP层,深度网络能够自由处理不同尺寸和比例的图像,同时生成用于分类任务的固定长度特征,这大大提高了网络的实用性和灵活性。
2.3 Training the Network
首先,作者指出理论上讲,使用标准的反向传播算法,无论输入图像的尺寸大小,上述的网络结构都是可以被训练的。但是,实际上为了更好地利用GPU资源,人们通常倾向于在固定大小的图像上运行GPU实现(例如 cuda-convnet 和 Caffe)。在这种情况下,需要一种特殊的训练解决方案来利用现有的GPU实现,同时保持SPP的特性。
单尺寸训练(Single-size training)
在实践中,首先考虑网络接受一个固定尺寸(例如224x224像素)的输入,这个尺寸是从图像中裁剪出来的,裁剪操作既能为数据增加多样性,又满足了网络对输入尺寸的要求。对于任何给定尺寸的图像,可以预先计算出进行空间金字塔池化所需的bin尺寸。
接着,作者讨论了在卷积层conv5之后的特征图(假设为 α × α α×α α×α,例如 13 × 13 13×13 13×13 像素)的处理。对于一个 n × n n×n n×n 层级的金字塔池化(比如 3 × 3 , 2 × 2 , 1 × 1 3\times3, 2\times2, 1\times1 3×3,2×2,1×1),作者描述了如何实现这样一个池化层级,使用滑动窗口池化(sliding window pooling),其中窗口大小(win)和步幅(str)根据特征图尺寸和金字塔层级动态计算。这里的符号⌈⌉表示向上取整,⌊⌋表示向下取整。
对于一个 l l l 层的金字塔池化,将会实现 l l l 个这样的池化层级。网络的下一个全连接层(比如fc6)会连接这些层的输出。cuda-convnet风格的图4中展示了3层金字塔池化( 3 × 3 , 2 × 2 , 1 × 1 3\times3, 2\times2, 1\times1 3×3,2×2,1×1)的示例配置。
单尺寸训练的主要目的是使网络能够进行多层级的池化操作。作者通过实验表明,多层级池化是提高精度的原因之一。
结论
这段内容讨论的是如何在实际的GPU实现中调整训练过程,以便于能够利用SPP的优势,尤其是如何在固定尺寸输入的限制下模拟SPP的多尺度特性。作者强调这种单尺寸训练策略能够在不改变现有GPU实现的基础上,实现多层级池化,进而提升网络的性能。这说明了在实际应用中,常常需要在理论和实现之间找到
多尺度训练
多尺度训练空间金字塔池化网络(SPP-net),使其能够处理任意大小的输入图像:
-
不同尺寸的输入图像:SPP-net旨在能够应用于任何大小的图像。然而,在训练过程中,需要处理不同大小图像所带来的问题。
-
预定义尺寸集合:为了解决训练时图像大小不一的问题,作者考虑使用一组预定义的尺寸。具体来说,他们考虑了两种尺寸:180×180和224×224。
-
图像重采样:不是通过裁剪,而是通过将224×224的区域重采样为180×180,保持内容/布局不变,仅分辨率不同。
-
实现两种固定尺寸输入的网络:为了处理180×180的输入,他们实现了另一个接收这种尺寸的固定尺寸输入网络。在该网络中,conv5层后的特征图大小为10×10。这个网络使用与224×224网络相同的空间金字塔池化参数。
-
训练策略:为了减少从一个尺寸网络切换到另一个尺寸网络的开销,他们选择在一个完整的训练周期(epoch)中使用一个网络训练,然后在下一个周期切换到另一个尺寸的网络,并保持所有之前训练的权重不变。这个过程会反复迭代。
-
多尺寸训练的目的:多尺寸训练的目的是为了模拟在训练期间输入图像大小的变化,同时利用现有的针对固定尺寸输入优化的实现。除了上述的双尺度实现外,还测试了一种变体,在每个训练周期中使用从180到224之间随机均匀采样的尺寸 s × s s × s s×s作为输入。
-
训练与测试阶段的差异:上述单尺寸和多尺寸的解决方案仅用于训练。在测试阶段,可以直接将SPP-net应用于任意大小的图像。
总结来说,这段内容介绍了作者如何通过在训练期间使用多个固定尺寸网络,共享参数的方法来模拟处理不同尺寸输入的情况。这种做法使得在训练期间网络能够适应不同尺寸的输入,而在实际应用或测试时,SPP-net可以直接处理任意尺寸的图像。
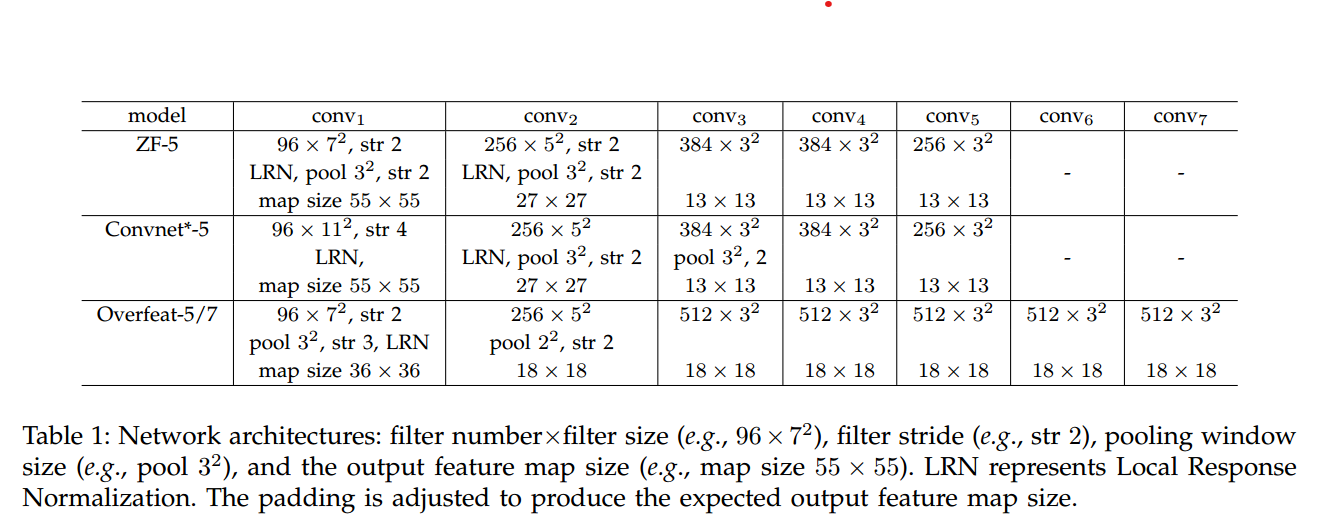
这个表格详细列出了三种不同的深度卷积网络架构(ZF-5, Convnet*-5, Overfeat-5/7)中每层卷积的配置。对于每个模型,表格展示了以下参数:
-
滤波器数量×滤波器尺寸:例如,96×7²意味着第一层卷积层有96个滤波器,每个滤波器的尺寸为7×7像素。
-
滤波器步长(stride):例如,str 2表示滤波器在应用到输入数据时每次移动2个像素点。
-
池化窗口大小:例如,pool 3²意味着池化层使用3×3像素的窗口来进行池化操作。
-
LRN(局部响应归一化):用于在卷积层后增加非线性并有助于模型泛化。
-
输出特征图尺寸:表示卷积操作后得到的特征图的大小。例如,map size 55 × 55意味着经过这层处理后,输出的特征图的尺寸为55×55像素。
-
填充(padding):在应用卷积操作之前对输入数据边缘进行填充,以确保输出特征图具有期望的尺寸。
这三种模型分别为:
- ZF-5:包含5个卷积层的网络。
- Convnet-5*:类似于AlexNet的结构,也是5个卷积层。
- Overfeat-5/7:一种更深的网络,包含5或7个卷积层,并且有更多的滤波器(尤其在conv3及之后的层)。
此表格为深度学习研究人员和实践者提供了模型架构的精确信息,使他们能够复现或比较不同模型的性能。每种模型的设计都影响着它们处理不同层级特征的能力,以及在视觉识别任务上的表现。
配图 1.
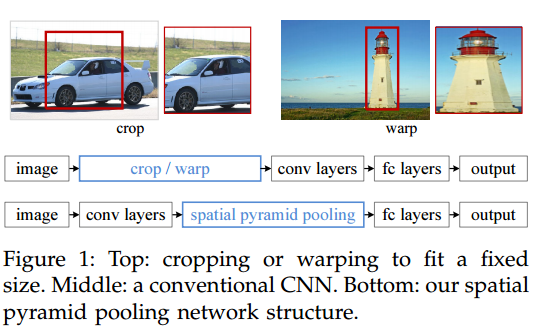
这张图1展示了传统卷积神经网络(CNN)处理不同尺寸图像的方法与引入空间金字塔池化(SPP)后的网络结构对比。
图中上部分:传统CNN的输入处理
- 裁剪(crop): 展示了从大尺寸图像中裁剪出固定大小的区域。左侧的车辆图像通过裁剪可以得到车辆的一个部分,但裁剪区域可能不包含整个对象,这会导致信息丢失。
- 变形(warp): 展示了将整个图像变形(比如拉伸或压缩)以适应网络输入尺寸的固定要求。右侧的灯塔图像通过变形适配到了固定的网络输入尺寸,但是这样做会导致图像失真。
图中中部分:传统CNN结构
展示了一个标准的CNN网络流程。输入图像先经过裁剪或变形处理以适配固定大小,然后通过一系列卷积层(conv layers)提取特征,接着是一系列全连接层(fc layers),最后得到输出结果(output)。
图中下部分:空间金字塔池化网络结构(SPP-net)
这里显示的是引入了空间金字塔池化层的CNN结构。输入图像直接通过卷积层提取特征,这些特征随后被送入空间金字塔池化层(spatial pyramid pooling)。这个池化层能够处理任意大小的特征图,生成固定长度的表示,从而允许全连接层处理不同尺寸的图像。最终,网络同样输出结果。
通过引入SPP层,CNN能够接收任意大小的输入图像,而不需要事先进行裁剪或变形处理。这样做的好处是,可以减少或消除由于裁剪或变形造成的信息丢失和失真,提高网络对不同尺寸和比例图像的泛化能力。
配图 2.

图2展示了特征图(feature maps)的可视化,这些特征图是由深度卷积网络(CNN)的第五层卷积层(conv5)的过滤器(filters)产生的。
图中部分说明:
(a) 图像
展示了来自Pascal VOC 2007数据集的两幅图像。左边是一个夜景的街道图像,右边是一个正在健身房运动的人的图像。
(b) 特征图
- 对于左侧图像,显示了两个特征图的例子,分别对应于conv5层中的filter #175和filter #55。
- 对于右侧图像,同样显示了两个特征图的例子,分别对应于filter #66和filter #118。
在这些特征图中,亮度较高的区域表明了滤波器在输入图像的相应位置的强烈反应。这些强反应可能指示着滤波器学习到的特定特征(如边缘、角落、纹理或某些物体的一部分)在原始图像中的位置。
© 最强激活
- 对于左侧图像中的两个过滤器,显示了ImageNet数据集中引起这些过滤器最强激活的图像。这表明了每个过滤器可能在识别什么类型的特征上有高度的专门化。例如,filter #175可能对某种特定的颜色或灯光模式反应强烈,而filter #55可能对特定的形状或结构反应强烈。
- 对于右侧图像中的两个过滤器,也是如此,展示了引起最强激活的ImageNet图像。
在所有的示例中,绿色矩形标记了在图像中引起最强激活的那些区域的感受野(receptive fields)。这些感受野对应于原始输入图像中的区域,这些区域在经过卷积层处理后在特征图上产生了明显的活动。简而言之,这张图展示了不同滤波器如何响应图像中的不同特征,并如何将这些特征映射回原始图像中的具体位置。
配图 3.
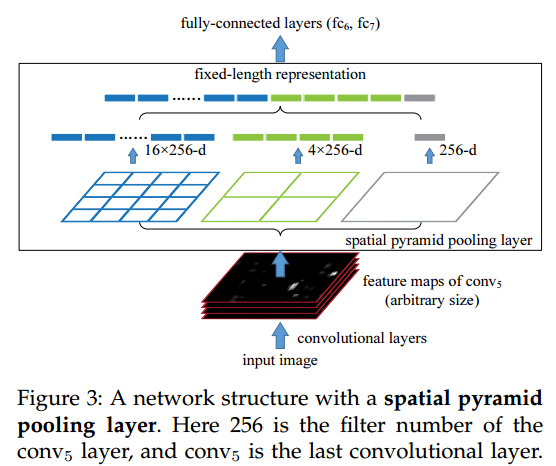
这张图3说明了空间金字塔池化(SPP)层在网络中的具体位置以及它是如何工作的。
图中部分说明:
底部:输入图像和卷积层
- 输入图像经过一系列卷积层处理后,产生了一组任意大小的特征图(feature maps of conv5),它们位于图的最底部。
中间:空间金字塔池化层
- 紧接着是空间金字塔池化层,它上方直观地表示了不同尺度的池化操作。
- 这一层包含多个级别的池化区域(如示例中的1×1, 2×2, 4×4),每个区域会聚合(池化)特征图上对应部分的特征。
- 不同大小的方格代表了不同池化区域的数量。例如,蓝色方格表示有16个大小为256-d(维度)的区域被池化,绿色方格表示有4个这样的区域,而紫色方格表示只有1个。
- 通过将所有池化后的特征连接起来,形成了一个固定长度的表示(fixed-length representation)。
顶部:全连接层
- 得到的固定长度的特征表示会被送入之后的全连接层(fc6, fc7)进行进一步的处理,最终输出结果。
图的功能说明:
- 这张图展示的SPP层允许网络处理任意尺寸的输入图像,而无需改变图像的尺寸来匹配网络的预定尺寸。
- 通常全连接层需要固定长度的输入,但由于特征图的尺寸会随着输入图像的尺寸变化而变化,传统的CNN在全连接层之前需要一个固定尺寸的输入。SPP层通过空间金字塔结构解决了这个问题,无论输入图像的大小如何,都能够产生一个固定长度的输出向量。
- 这种方法不仅提高了网络的灵活性,还增强了对不同尺度特征的适应能力,因为在较大的图像上应用同样大小的滤波器将捕获到更细粒度的信息。
总的来说,这张图清晰地描绘了SPP-net如何结合多尺度空间池化,以生成适应任意输入图像尺寸的固定长度特征,进而允许使用全连接层,而无需预处理图像尺寸。
配图 5.
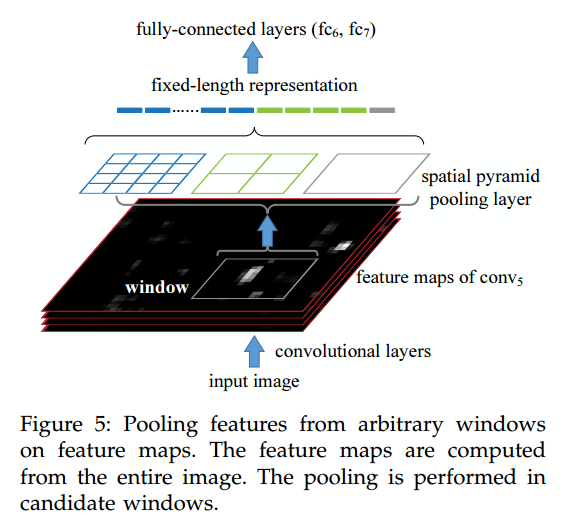
图5是对SPP-net中空间金字塔池化层如何处理任意窗口特征进行池化的一个直观说明。
图中部分说明:
底部:输入图像和卷积层
- 输入图像经过卷积层处理后,会在不同的深度层上产生一组特征图。这里特别指的是conv5层的特征图。
- “窗口(window)”指的是在特征图上任意选取的区域,这个区域可以是图像中感兴趣的特定部分,比如可能包含了一个物体。
中间:空间金字塔池化层
- 空间金字塔池化层位于卷积层与全连接层之间。它的作用是将从卷积层来的变长特征转换成固定长度的向量。
- 池化层中有不同大小的蓝色、绿色和灰色的方格,这些表示不同层级的池化,如1×1(整个窗口),2×2(窗口分成4个区域),4×4(窗口分成16个区域)的池化。
- 每个方格内的特征被池化(如最大值池化),最终将所有池化后的特征拼接成一个固定长度的向量。
顶部:全连接层
- 池化后的固定长度的表示被送入全连接层(fc6, fc7),在这里进行更深层次的特征学习和分类或者回归任务。
图的功能说明:
- 通过空间金字塔池化,即使是在图像的任意窗口上,SPP-net也能从变化的区域大小中生成一个固定长度的特征表示,使得全连接层能够处理这些特征。
- 这种方法使得网络不仅能够处理整个图像,还能处理图像中的任意大小的局部区域,这在物体检测等任务中非常有用,因为它允许网络集中于图像中潜在的感兴趣区域。
- 与传统的滑动窗口方法相比,这种方法减少了重复计算卷积特征的需要,显著提高了计算效率,特别是在处理物体检测任务时。
总结来说,这张图清晰地展示了SPP-net如何有效地从特征图中的任意窗口提取固定长度的特征表示,并将其传递给后续的网络结构进行进一步处理。
Our network with SPP is expected to be applied on images of any sizes. To address the issue of varying image sizes in training, we consider a set of predefined sizes. We consider two sizes: 180×180 in addition to 224×224. Rather than crop a smaller 180×180 region, we resize the aforementioned 224×224 region to 180×180. So the regions at both scales differ only in resolution but not in content/layout. For the network to accept 180×180 inputs, we implement another fixed-size-input (180×180) network. The feature map size after conv5 is a × a = 10 × 10 a×a = 10×10 a×a=10×10 in this case. Then we still use w i n = ⌈ a / n ⌉ win = \lceil a/n \rceil win=⌈a/n⌉ and s t r = ⌊ a / n ⌋ str = \lfloor a/n \rfloor str=⌊a/n⌋ to implement each pyramid pooling level. The output of the spatial pyramid pooling layer of this 180-network has the same fixed length as the 224-network. As such, this 180-network has exactly the same parameters as the 224-network in each layer. In other words, during training we implement the varying-input-size SPP-net by two fixed-size networks that share parameters.
To reduce the overhead to switch from one network (e.g., 224) to the other (e.g., 180), we train each full epoch on one network, and then switch to the other one (keeping all weights) for the next full epoch. This is iterated. In experiments, we find the convergence rate of this multi-size training to be similar to the above single-size training.
The main purpose of our multi-size training is to simulate the varying input sizes while still leveraging the existing well-optimized fixed-size implementations. Besides the above two-scale implementation, we have also tested a variant using s × s s × s s×s as input where s s s is randomly and uniformly sampled from [180,224] at each epoch. We report the results of both variants in the experiment section.
Note that the above single/multi-size solutions are for training only. At the testing stage, it is straightforward to apply SPP-net on images of any sizes.