目录
1.使用环境
2.条件判断
2.1.case when
2.2.if
3.窗口函数
3.1.排序函数
3.2.聚合函数
3.3.partiton by
3.4.order by
4.排序窗口函数
5.聚合窗口函数
1.使用环境
数据库:MySQL 8.0.30
客户端:Navicat 15.0.12
MySQL进阶一:
MySQL进阶一-CSDN博客
MySQL进阶二:
MySQL进阶二-CSDN博客
2.条件判断
2.1.case when
语法格式:
case when [condition] then [result1]...else [default] end
如果condition条件成立,返回result1,否则返回default,以end结束条件判断。
建表:
CREATE TABLE t_1 (id int(10) NOT NULL,name varchar(255) DEFAULT NULL,age int(5) DEFAULT NULL,score int(5) DEFAULT NULL,PRIMARY KEY (`id`)
);> OK
> 时间: 0.008s
添加数据:
INSERT INTO t_1 VALUES
('1', '张三', '20', '68'),
('2', '李四', '19', '97'),
('3', '王五', '21', '55'),
('4', '赵六', '22', '81');> Affected rows: 4
> 时间: 0.001s
为t_1添加一列level,表示学生的得分等级:
select * ,case when t_1.score >= 80 then '优秀'when t_1.score < 80 and t_1.score >= 60 then '一般'else '不及格'end as level
from t_1;
2.2.if
语法格式:
if(condition,result1,result2)
如果condition条件为真,则返回result1否则返回result2。
为t_1添加一列,表示学生是否成年:
select *,
if(t_1.age >= 18,'成年人','未成年人') as 是否成年
from t_1;
3.窗口函数
语法格式:
窗口函数 over(partiton by 分组字段 order by 排序字段 asc|desc)
3.1.排序函数
- rank()
- dense_rank()
- row_number()
3.2.聚合函数
- sum(字段) ---求和
- count(字段) ---统计个数
- max(字段) ---最大值
- min(字段) ---最小值
- avg(字段) --平均值
3.3.partiton by
将表数据根据partiton by后面的字段进行分组。
partiton by和 group by分组的区别:
- group by会改变显示结果的行数(相当于按照字段折叠,把同一组的数据折叠在一起)。
- partiton by不会改变表显示的行数(与原表显示一样),只是把相同组的数据归纳纵向相连在一起。
3.4.order by
根据指定的字段进行排序。
4.排序窗口函数
先建表:
CREATE TABLE student0413 (sid varchar(255),gender varchar(255) DEFAULT NULL,sname varchar(255) DEFAULT NULL,caption varchar(255) DEFAULT NULL,cname varchar(255) DEFAULT NULL,tname varchar(255) DEFAULT NULL,num varchar(255) DEFAULT NULL
)> OK
> 时间: 0.01s
添加数据:
INSERT INTO student0413 VALUES
('1', '男', '李一一', '三年二班', '生物', '张老师', '11'),
('1', '男', '李一一', '三年二班', '物理', '李老师', '8'),
('1', '男', '李一一', '三年二班', '美术', '李老师', '67'),
('2', '女', '王一二', '三年二班', '生物', '张老师', '9'),
('2', '女', '王一二', '三年二班', '体育', '刘老师', '69'),
('2', '女', '王一二', '三年二班', '美术', '李老师', '98'),
('3', '男', '张三', '三年二班', '生物', '张老师', '78'),
('3', '男', '张三', '三年二班', '物理', '李老师', '67'),
('3', '男', '张三', '三年二班', '体育', '刘老师', '88'),
('3', '男', '张三', '三年二班', '美术', '李老师', '98'),
('4', '男', '张一', '三年二班', '生物', '张老师', '78'),
('4', '男', '张一', '三年二班', '物理', '李老师', '12'),
('4', '男', '张一', '三年二班', '体育', '刘老师', '68'),
('4', '男', '张一', '三年二班', '美术', '李老师', '100'),
('5', '女', '张二', '三年二班', '生物', '张老师', '78'),
('5', '女', '张二', '三年二班', '物理', '李老师', '12'),
('5', '女', '张二', '三年二班', '体育', '刘老师', '68'),
('5', '女', '张二', '三年二班', '美术', '李老师', '100'),
('6', '男', '张四', '三年二班', '生物', '张老师', '8'),
('6', '男', '张四', '三年二班', '物理', '李老师', '100'),
('6', '男', '张四', '三年二班', '体育', '刘老师', '68'),
('6', '男', '张四', '三年二班', '美术', '李老师', '100'),
('7', '女', '丁一', '三年三班', '生物', '张老师', '8'),
('7', '女', '丁一', '三年三班', '物理', '李老师', '100'),
('7', '女', '丁一', '三年三班', '体育', '刘老师', '68'),
('7', '女', '丁一', '三年三班', '美术', '李老师', '89'),
('8', '男', '李三', '三年三班', '生物', '张老师', '8'),
('8', '男', '李三', '三年三班', '物理', '李老师', '100'),
('8', '男', '李三', '三年三班', '体育', '刘老师', '68'),
('8', '男', '李三', '三年三班', '美术', '李老师', '89'),
('9', '男', '李一', '三年三班', '生物', '张老师', '92'),
('9', '男', '李一', '三年三班', '物理', '李老师', '89'),
('9', '男', '李一', '三年三班', '体育', '刘老师', '68'),
('9', '男', '李一', '三年三班', '美术', '李老师', '23'),
('10', '女', '李二', '三年三班', '生物', '张老师', '91'),
('10', '女', '李二', '三年三班', '物理', '李老师', '78'),
('10', '女', '李二', '三年三班', '体育', '刘老师', '44'),
('10', '女', '李二', '三年三班', '美术', '李老师', '88'),
('11', '男', '李四', '三年三班', '生物', '张老师', '91'),
('11', '男', '李四', '三年三班', '物理', '李老师', '78'),
('11', '男', '李四', '三年三班', '体育', '刘老师', '44'),
('11', '男', '李四', '三年三班', '美术', '李老师', '88'),
('12', '女', '赵五', '一年二班', '生物', '张老师', '91'),
('12', '女', '赵五', '一年二班', '物理', '李老师', '78'),
('12', '女', '赵五', '一年二班', '体育', '刘老师', '44'),
('12', '女', '赵五', '一年二班', '美术', '李老师', '88'),
('13', '男', '刘一五', '一年二班', '体育', '刘老师', '88');> Affected rows: 47
> 时间: 0.002s
查询每个班分数最高的学生的分数:
select caption,max(num) as 最高分 from student0413 group by caption;
把每个班的学生成绩从高到低进行排序,并将排名结果作为新的一列和原数据汇总到一起:
select *,rank() over(partition by caption order by num desc) as 排名 from student0413;
使用dense_rank排名函数,查看和rank的区别:
select *,dense_rank() over(partition by caption order by num desc) as 排名
from student;使用row_number排名函数,查看和rank和dense_rank的区别:
select *,row_number() over(partition by caption order by num desc) as 排名 from student0413;查询每个班的分数排名前2的学生信息:
select * from
(select *, dense_rank() over(partition by caption order by num desc) 排名 from student0413) as e
where e.排名 <= 2;
查找每个班级成绩最高的所有学员信息:
select * from
(select *, dense_rank() over(partition by caption order by num desc) 排名 from student0413) as e
where 排名 <= 1;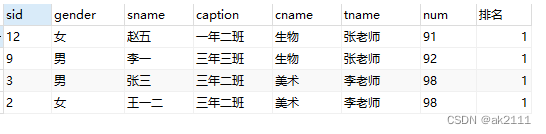
5.聚合窗口函数
用分组聚合实现每个学生及格科目的数量统计:
用分组聚合实现每个学生及格科目的数量统计:
select sname, count(cname) 及格学科数量 from
(select * from student0413 where num >= 60) as e
group by sname;
用窗口函数实现每个学生及格科目的数量统计:
select sname, count(cname) over(partition by sname) 及格学科数量
from student0413 where num >= 60;
查询每个月的总销量与总销售额:
建表:
create table if not exists sale_order(
id int primary key auto_increment, -- 订单id
sale date, -- 订单时间
user_id int, -- 用户id
pro_id int, -- 商品类型id
sale_count int, -- 销售数量
price int, -- 销售单价
amount int -- 销售金额
);> OK
> 时间: 0.008s
添加数据:
insert into sale_order(sale, user_id, pro_id, sale_count, price, amount) values
('2024-01-01', 1, 101, 2, 150, 300),
('2024-01-02', 2, 101, 1, 100, 100),
('2024-02-10', 3, 101, 2, 90, 180),
('2024-02-11', 2, 102, 2, 200, 400),
('2024-03-01', 3, 102, 1, 100, 100),
('2024-03-01', 3, 101, 1, 60, 60),
('2024-03-01', 3, 103, 4, 120, 480);> Affected rows: 7
> 时间: 0.001s
查询每个月的总销量与总销售额:
select date_format(sale, '%Y-%m') 月, sum(sale_count) 总销量, sum(amount) 总销售额
from sale_order group by 月;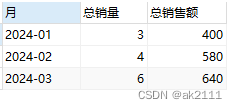




![[CSS]使用方式+样式属性](https://img-blog.csdnimg.cn/direct/249f3b443e504592800e00f1f0466934.png)

