iclr 2024 reviewer 评分 5668
1 intro
- 大模型网络剪枝的paper
- 在努力保持性能的同时,舍弃网络权重的一个子集
- 现有方法
- 要么需要重新训练
- 这对于十亿级别的LLMs来说往往不现实
- 要么需要解决依赖于二阶信息的权重重建问题
- 这同样可能带来高昂的计算成本
- 要么需要重新训练
- ——>引入了一种新颖、简单且有效的剪枝方法,名为Wanda (Pruning by Weights and activations)
- 在每个输出的基础上,剪枝那些乘以相应输入激活后幅度最小的权重
- 无需重新训练或权重更新,剪枝后的LLM可以即刻使用
2 方法
2.1 motivation
- 考虑一个带有两个输入及其对应权重的神经元:y = w1x1 + w2x2,其中|w1| ≤ |w2|。
- 现在假设目标是选择一个权重进行移除,同时使输出变化最小。
- 标准的幅度剪枝方法总是会移除权重w1
- 如果输入特征x1和x2的幅度相似,这可能是一个好策略。
- 然而,最近在LLMs中观察到,两个输入特征的规模可能差异很大。例如,可能|x1| ≫ |x2|,结果是|w1x1| ≫ |w2x2|。
- 在这种情况下,我们应该移除权重w2,因为这种移除明显对神经元输出y的影响小于移除权重w1。
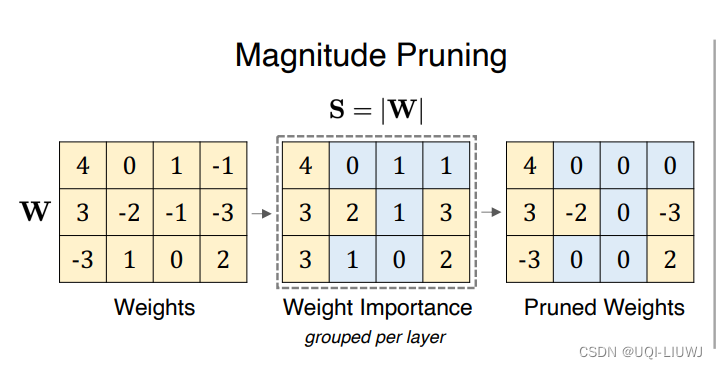
- 这个动机示例与最简单的线性层一起暗示了幅度剪枝的一个主要限制:
- 它没有考虑输入激活,输入激活在决定神经元输出时可能与权重幅度同样重要。
- 对于剪枝LLMs,这一点尤其关键,考虑到在其中发现的突出大幅度特征。
- ——>提出了一种专门为LLMs设计的剪枝指标,以处理此类限制,同时也保持了幅度剪枝的简单性
2.2 剪枝指标
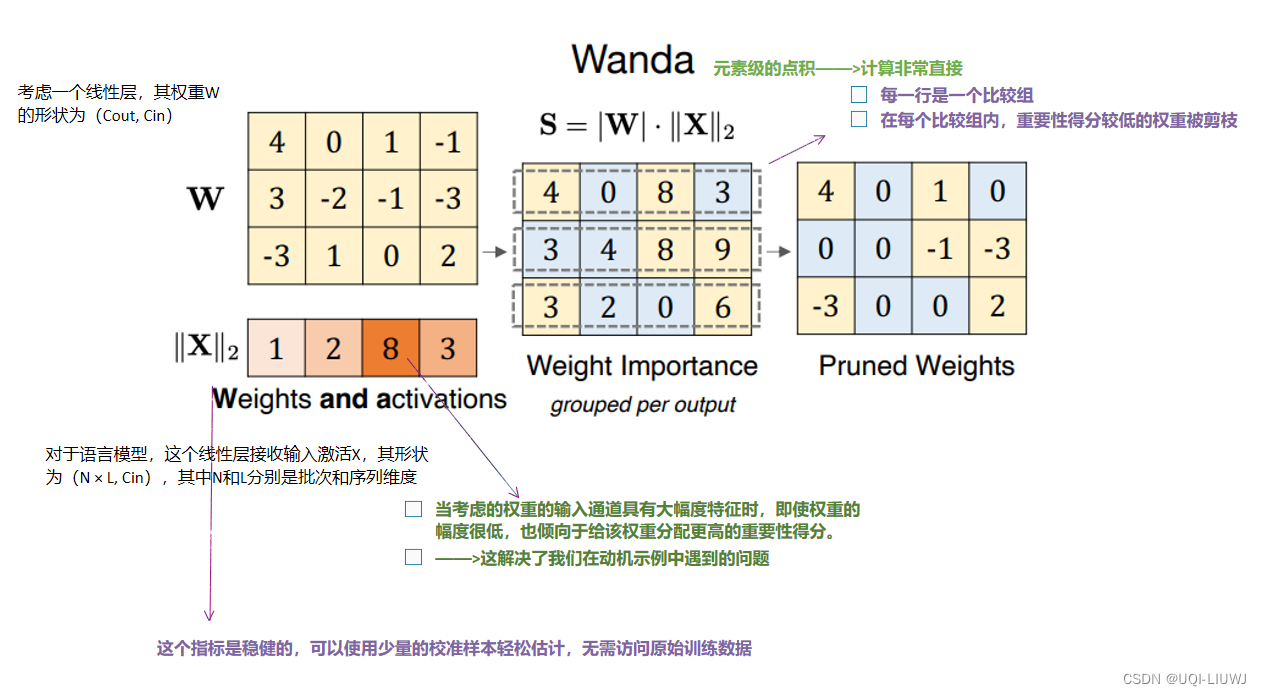

2.3 和现有方法的对比

3 实验
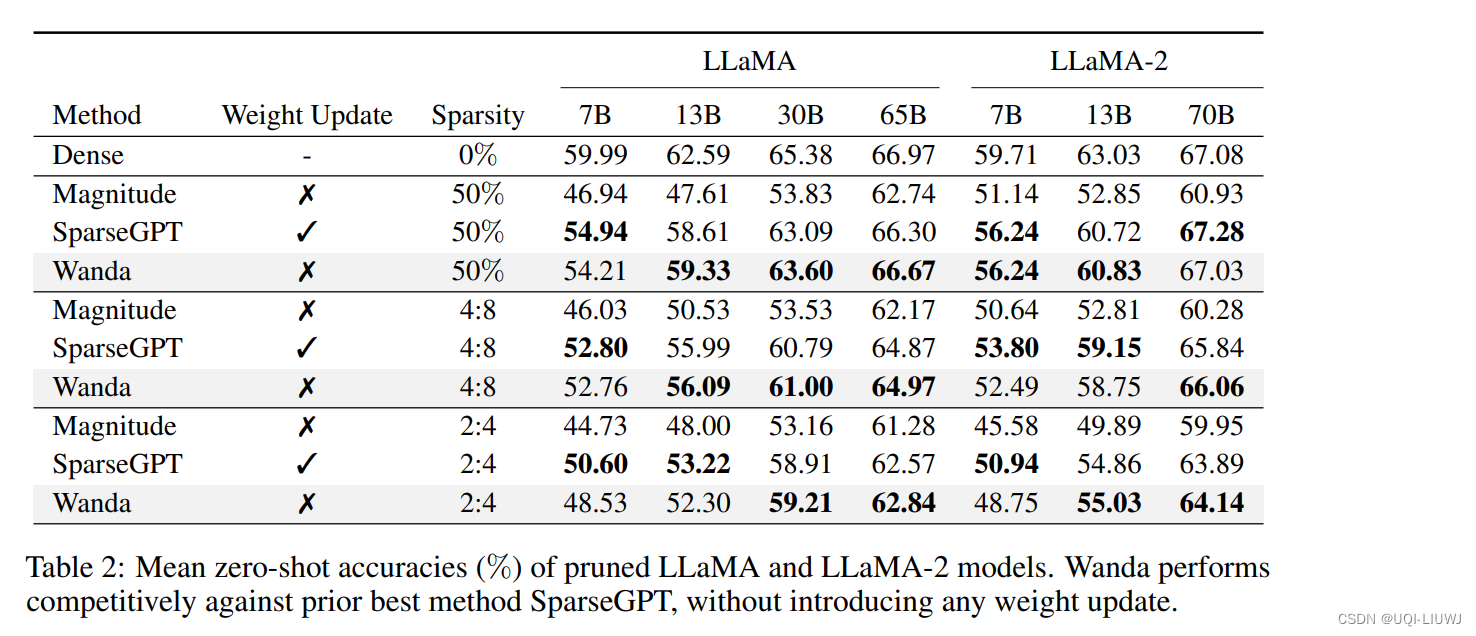
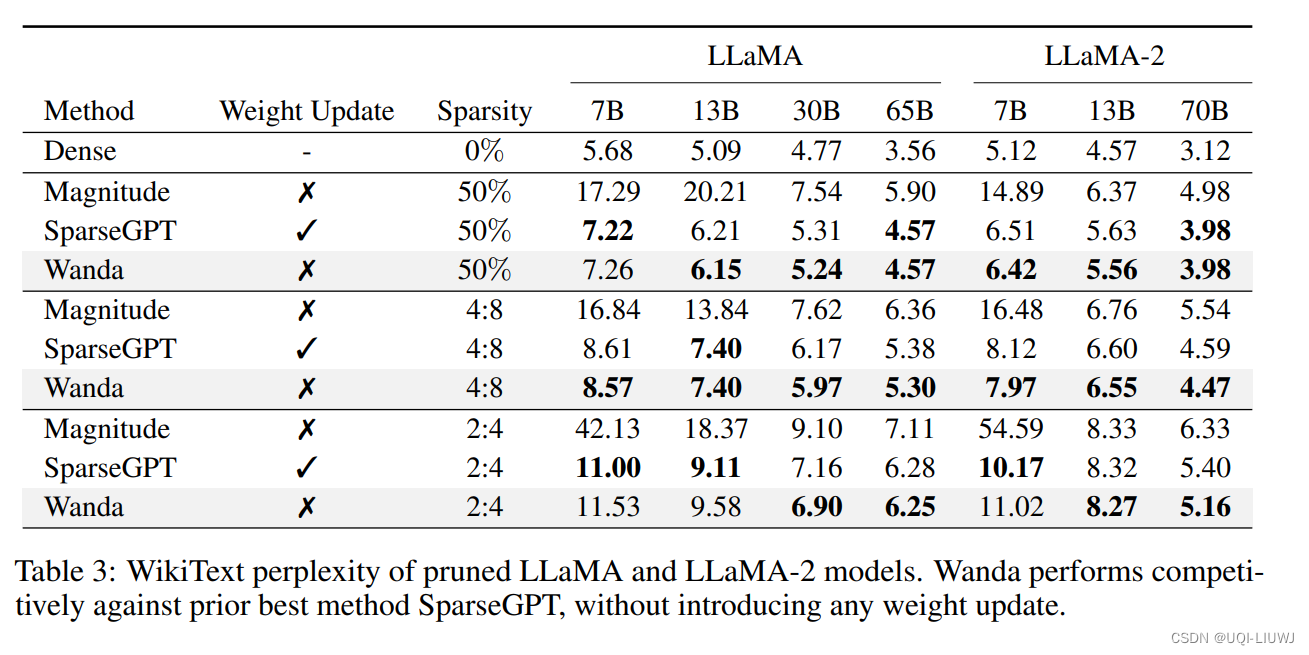
3.1 效果比较
3.2 速度比较

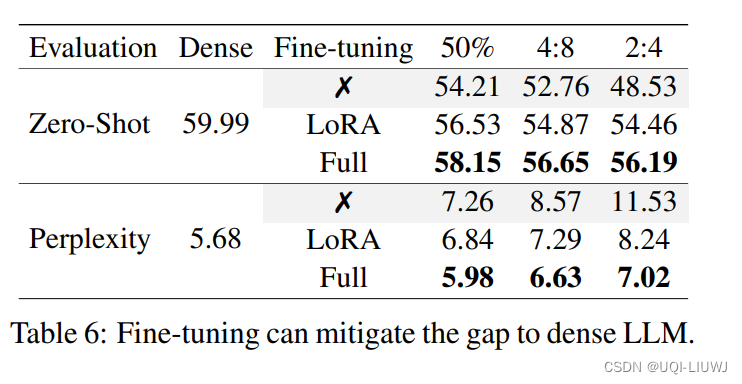
3.3 finetune 剪枝后的LLM可以接近不剪枝的LLM
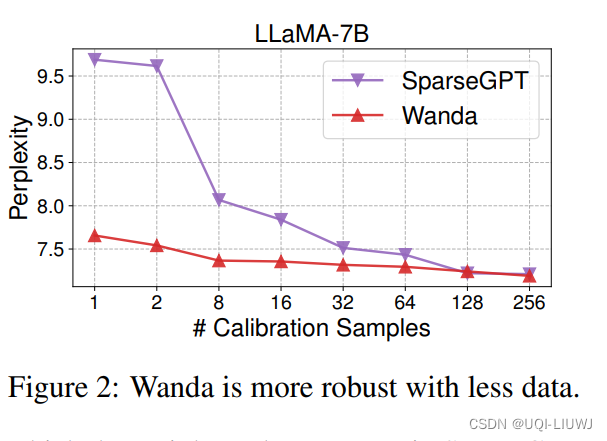
3.4 校准数据(X)的影响






![[大模型] BlueLM-7B-Chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/e6dcf4f6486b461ba21af25a9cc502a2.png#pic_center)