索引失效
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则,最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将部分失效(后面的字段索引失效)。
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效(不包含范围查询的列)。使用>=,<=不会失效
索引列运算
不要在索引列上进行运算操作,索引将会失效
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效
模糊查询
如果仅仅时尾部模糊查询,索引不会失效。如果是头部模糊查询,索引失效。
select * from user where name like '张%';索引不失效
select * from user where name like '%三';索引失效or连接的条件
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。解决办法:都加上索引。
数据分布影响
如果mysql评估使用索引比全表更慢,则不适用索引。
SQL提示
sql提示,是优化数据库的一个重要手段,简单来说,就是在sql语句中加入一些人为的提示来达到优化操作的目的。
-
use index(索引名):告诉数据库用哪个索引
-
ignore index(索引名):告诉数据库不用哪个索引
-
force index(索引名):告诉数据库必须走这个索引
覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经能够全部能够找到),减少select *。
补充:
extre中地信息:
using index condition:查找使用了索引,但是需要回表查询数据
using where;using index:查找使用了索引,但是需要的数据都在索引列中找到,所以不需要回表查询数据
前缀索引
当字段类型为字符串(varchar、text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘io,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
- 语法
 其中,n代表索引的前n个字符。
其中,n代表索引的前n个字符。 -
前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。可根据以上语句计算索引的选择性:

-
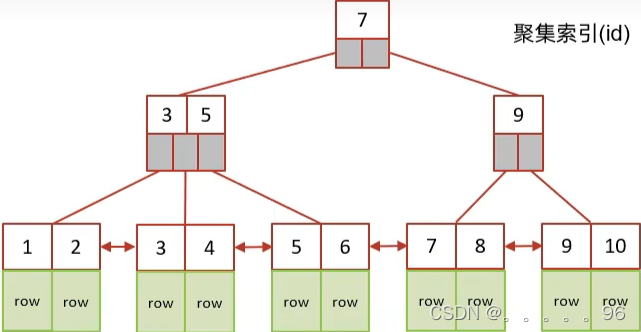
查询流程。以下表tb_user举例

-
根据id建立主键索引
-
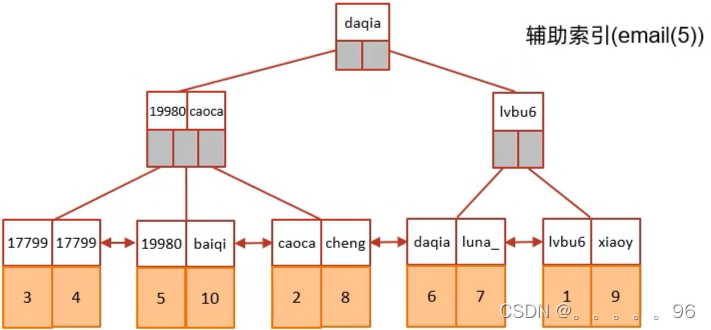
根据email列的前5位建立辅助索引
-
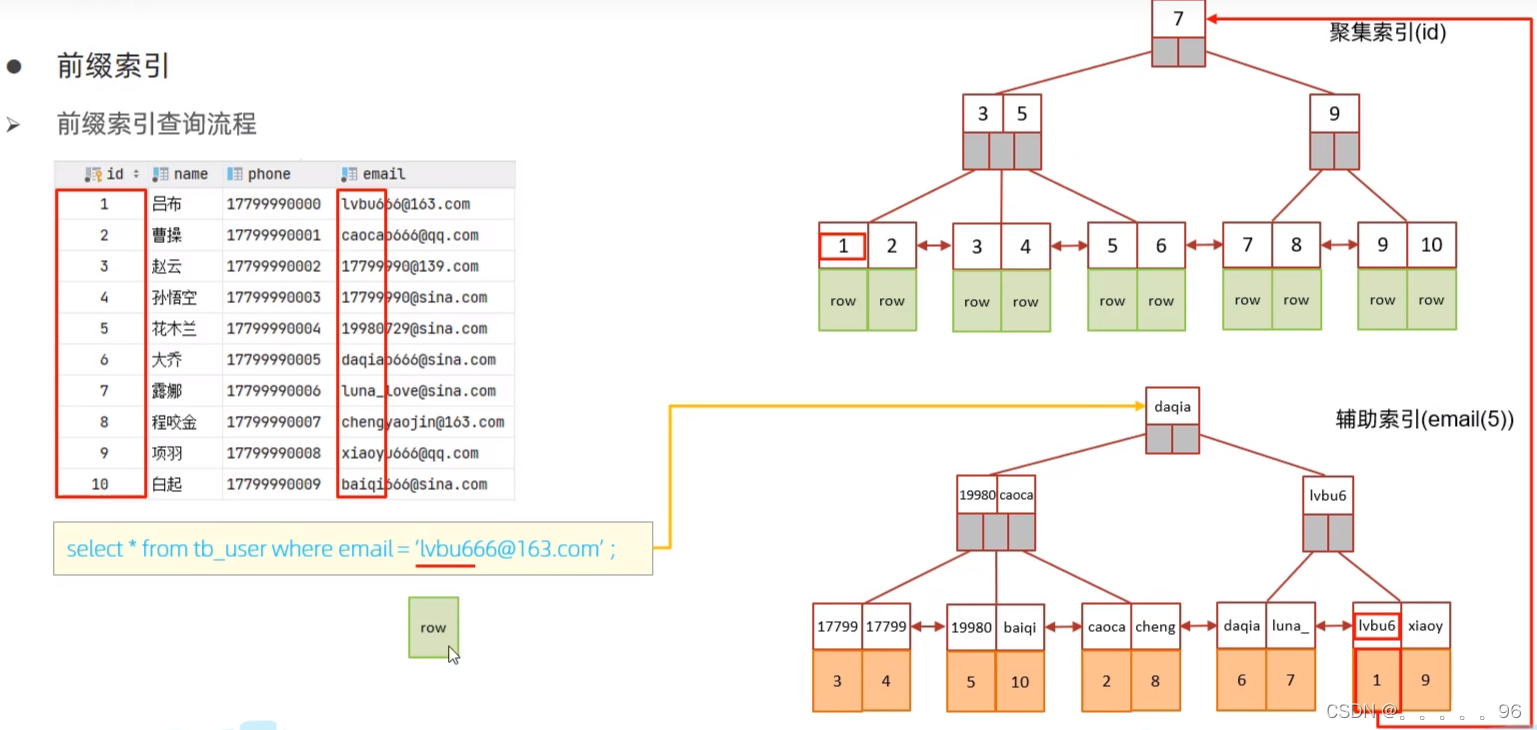
执行sql语句select * from tb_user where email="lvbu666@163.com";
-
对lvbu666@163.com截取前5位即"lvbu6"根据辅助索引进行查询,查到后拿到id值为1,再进行回表查询即根据id=1通过聚集索引查找
-
回表查询拿到数据后不会立即返回,还需要将拿的数据中的email值与我们要查询的email值进行比较(因为我们是根据email的前位查询的),如果相等则返回,否则不会返回。
-
接下来还会拿个"lvbu6"与下一个结点的进行比较,如果相等则重复以上操作,否则查询结束。
-
单列索引和联合索引
单列索引:即一个索引只包含单个列
联合索引:即一个索引包含了多个列
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。多条件联合查询时,MySQL优化器会评估哪个字段的索引效率高,会选择该索引完成本次查询。
这里对于单列索引不再做其他介绍,主要介绍下联合索引:
- 对字段phone和name建立联合索引

- 根据这个联合索引要查询字段是(id,phone,name)其中一个或多个时,就不需要回表。
设计原则
-
针对于数据量较大,且查询比较频繁的表建立索引
-
针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
-
尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率高
-
如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
-
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
-
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率
-
如果索引不能存储NULL值,谁在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。