一、几个概念
二叉树(binary tree):是 n(n >= 0)个结点(每个结点最多只有2棵子树)的有限集合,该集合可为空集(称为空二叉树),或由一个根节点和两颗互不相交的,称为根节点的左子树和右子树的二叉树组成。
如下图中
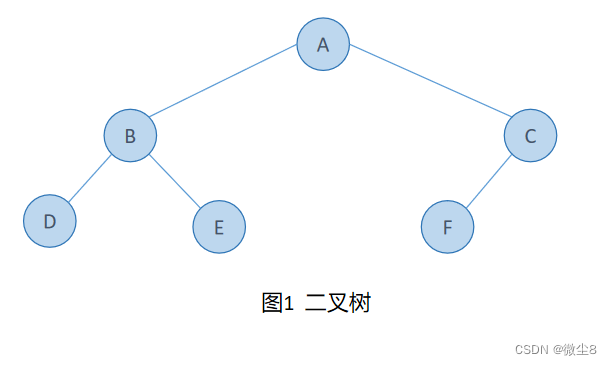
图1是一棵二叉树。
图2是非二叉树,因为 A 结点有3棵子树,其次 E 结点和 F 结点相交了
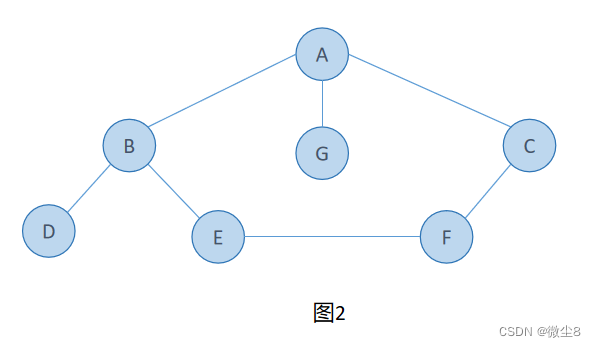
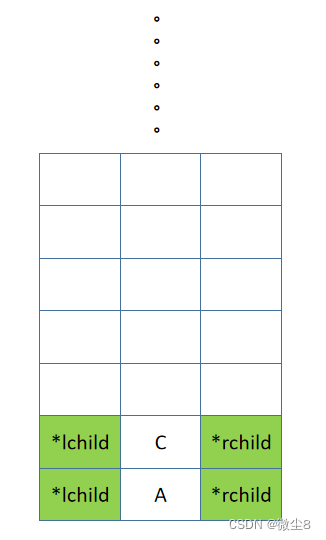
二叉链表:是二叉树的一种链式存储结构,其中每个结点包含三个字段:一个数据字段(data)和两个指针字段(*lchild、*rchild),分别指向该结点的左孩子和右孩子。如果某个结点没有左孩子或右孩子,那么对应的指针字段为NULL。

用 C 语言可以表述为:
typedef struct binary_node {char data;struct binary_node *lchild, *rchild;
}binary_tree;二、前序遍历二叉树(Pre-order Traversal)
前序遍历二叉树(Pre-order Traversal)的规则为:从根结点出发,先访问该结点,然后前序遍历该结点的左子树,再然后前序遍历该结点的右子树
所以,前序遍历图1这棵二叉树的步骤如图4所示

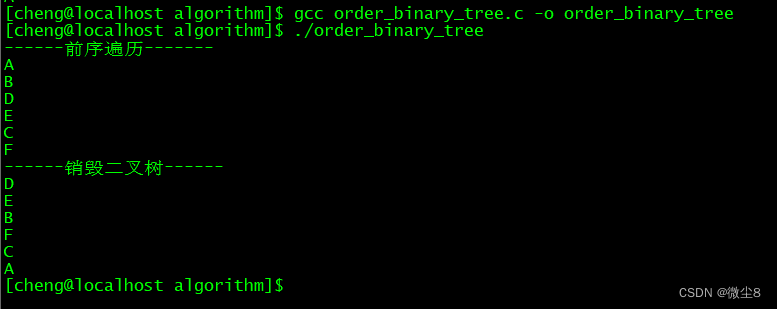
所以,图1这颗二叉树的前序遍历顺序为:ABDECF
1、算法思路
(1)从根结点 A 出发,A 结点入栈,先访问 A 结点,然后前序遍历 A 结点的左子树



(2)A 结点的左子树的根结点为 B,B 结点入栈,先访问 B 结点,然后前序遍历 B 结点的左子树



(3)B 结点的左子树的根结点为 D,D 结点入栈,先访问 D 结点,然后前序遍历 D 结点的左子树
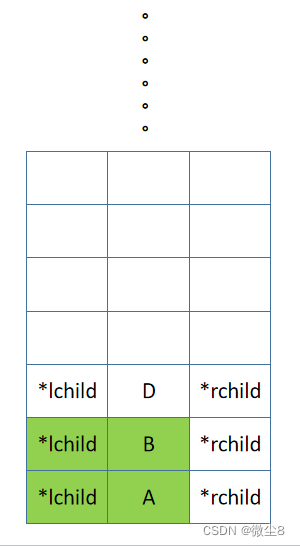


(4)D 结点的左子树为空,则返回
(5)逻辑返回到 D 结点,然后前序遍历 D 结点的右子树
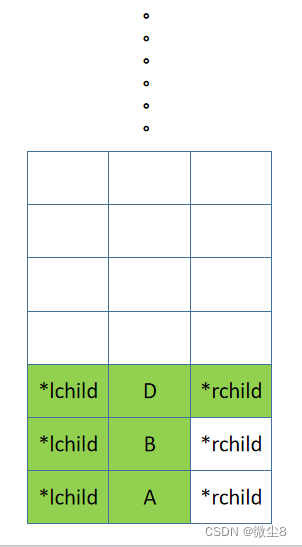
(6)D 结点的右子树为空,则返回
(7)逻辑返回到 D 结点,此时访问 D 结点,前序遍历 D 结点的左右子树的逻辑都已完成,则返回,D 结点出栈。
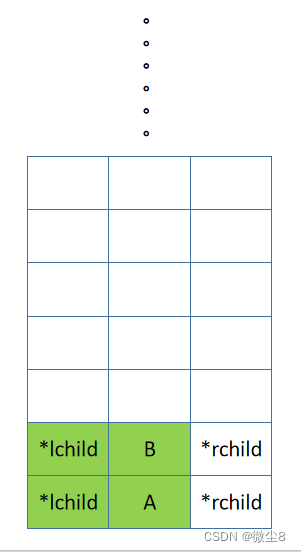
(8)逻辑返回到 B 结点,然后前序遍历 B 结点的右子树

(9)B 结点的右子树的根结点为 E,E 结点入栈,先访问 E 结点,然后前序遍历 E 结点的左子树

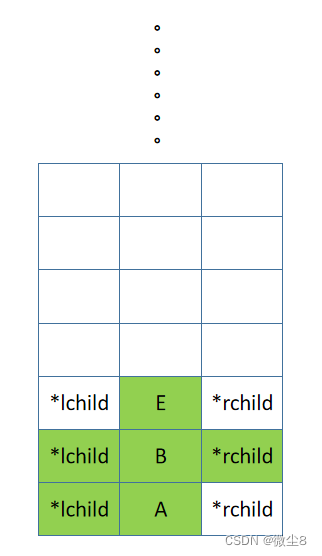
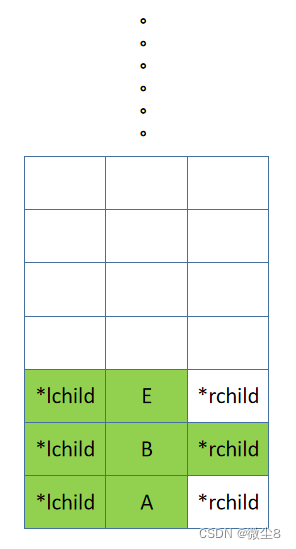
(10)E 结点的左子树为空,则返回
(11)逻辑返回到 E 结点,然后前序遍历 E 结点的右子树
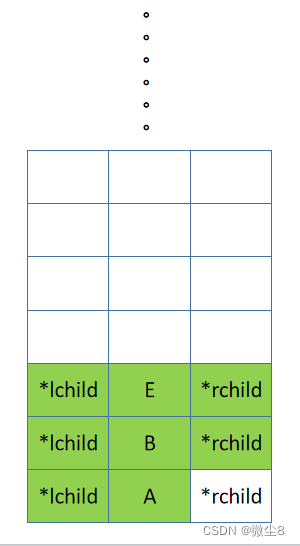
(12)E 结点的右子树为空,则返回
(13)逻辑返回到 E 结点,此时访问 E 结点,前序遍历 E 结点的左右子树的逻辑都已完成,则返回,E 结点出栈。
(14)逻辑返回到 B 结点,此时访问 B 结点,前序遍历 B 结点的左右子树的逻辑都已完成,则函数返回,B 结点出栈。
(15)逻辑返回到 A 结点,然后前序遍历 A 结点的右子树

(16)A 结点的右子树的根结点为 C,C 结点入栈,先访问 C 结点,然后前序遍历 C 结点的左子树



(17)C 结点的左子树的根结点为 F,F 结点入栈,先访问 F 结点,然后前序遍历 F 结点的左子树

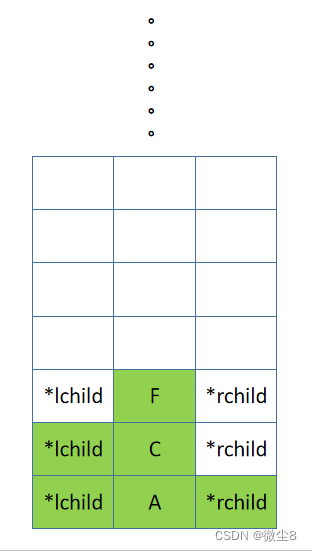

(18)F 结点的左子树为空,则返回
(19)逻辑返回到 F 结点,然后前序遍历 F 结点的右子树
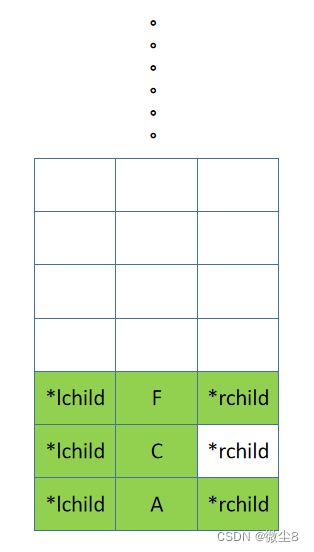
(20)F 结点的右子树为空,则返回
(21)逻辑返回到 F 结点,此时访问 F 结点,前序遍历 F 结点的左右子树的逻辑都已完成,则返回,F 结点出栈。

(22)逻辑返回到 C 结点,然后前序遍历 C 结点的右子树

(23)C 结点的右子树为空,则返回
(24)逻辑返回到 C 结点,此时访问 C 结点,前序遍历 C 结点的左右子树的逻辑都已完成,则返回,C 结点出栈。

(25)逻辑返回到 A 结点,此时访问 A 结点,前序遍历 A 结点的左右子树的逻辑都已完成,则返回,A 结点出栈。

(26)前序遍历二叉树已完成, 所以,前序遍历顺序为:ABDECF
2、实现代码
#include <stdio.h>
#include <string.h>
#include <stdlib.h>char *g_str = "ABD##E##CF###"; // 扩展二叉树前序序列
int g_index = 0;
typedef struct binary_node {char data;struct binary_node *lchild, *rchild;
}binary_tree;void create_binary_tree(binary_tree **T) {if (strlen(g_str) == 0)return;if (g_str[g_index] == '#') {*T = NULL;g_index++;} else {*T = malloc(sizeof(**T));(*T)->data = g_str[g_index];g_index++;create_binary_tree(&(*T)->lchild);create_binary_tree(&(*T)->rchild);}
}void visit_node(binary_tree *T) {printf("%c\n", T->data);
}void pre_order_tree(binary_tree *T) {if (!T)return;visit_node(T);pre_order_tree(T->lchild);pre_order_tree(T->rchild);
}/*销毁用后序遍历*/
void destroy_binary_tree(binary_tree *T) {if (!T)return;destroy_binary_tree(T->lchild);destroy_binary_tree(T->rchild);printf("%c\n", T->data);free(T);
}int main(int argc, char *argv[]) {binary_tree *T;create_binary_tree(&T);printf("------前序遍历-------\n");pre_order_tree(T);printf("------销毁二叉树------\n");destroy_binary_tree(T);return 0;
}
三、中序遍历二叉树(In-order Traversal)
中序遍历二叉树(In-order Traversal)的规则为:从根结点出发,先中序遍历该结点的左子树,然后访问该结点,再然后中序遍历该结点的右子树
所以,中序遍历图1这棵二叉树的步骤如下图所示
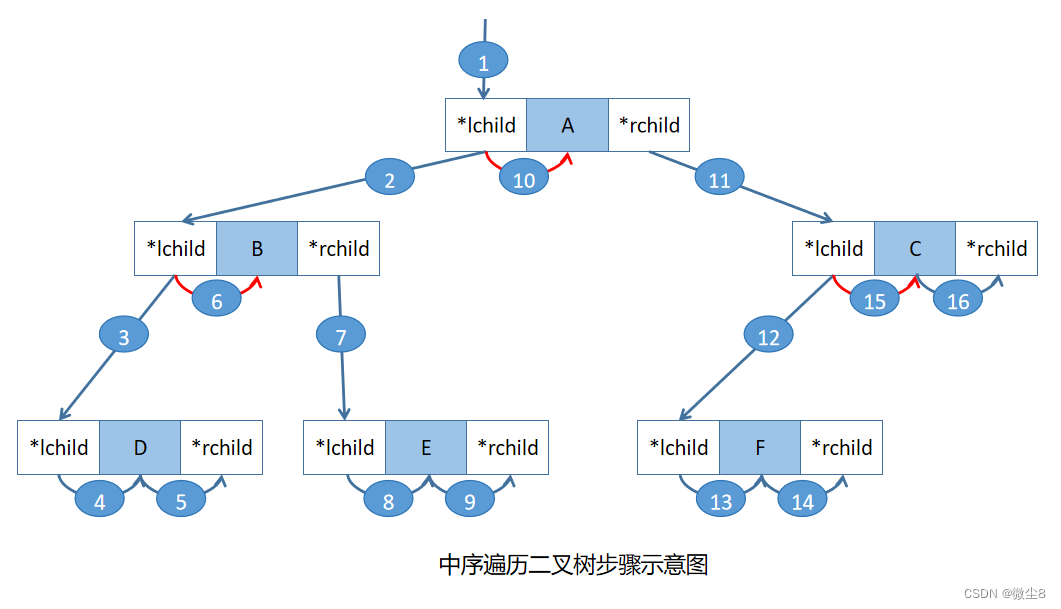
所以,图1这颗二叉树中序遍历顺序为:DBEAFC
1、算法思路
(1)从根结点 A 出发,A 结点入栈,先中序遍历 A 结点的左子树

(2)A 结点的左子树的根结点为 B,B 结点入栈,先中序遍历 B 结点的左子树


(3)B 结点的左子树的根结点为 D,D 结点入栈,先中序遍历 D 结点的左子树
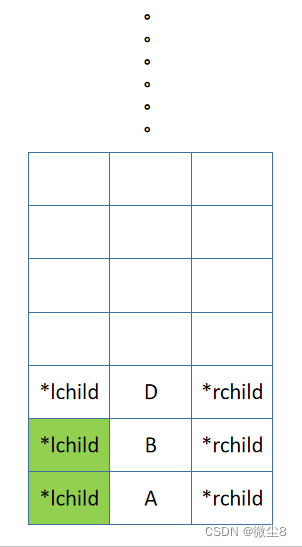

(4)D 结点的左子树为空,则返回
(5)逻辑返回到 D 结点,然后访问 D 结点,再然后中序遍历 D 结点的右子树


(6)D 结点的右子树为空,则返回
(7)逻辑返回到 D 结点,此时中序遍历 D 结点的左子树,访问 D 结点,中序遍历 D 结点的右子树的逻辑都已完成,则返回,D 结点出栈。
(8)逻辑返回到 B 结点,然后访问 B 结点,再然后中序遍历 B 结点的右子树


(9)B 结点的右子树的根结点为 E,E 结点入栈,先中序遍历 E 结点的左子树


(10)E 结点的左子树为空,则返回
(11)逻辑返回到 E 结点,然后访问 E 结点,再然后中序遍历 E 结点的右子树

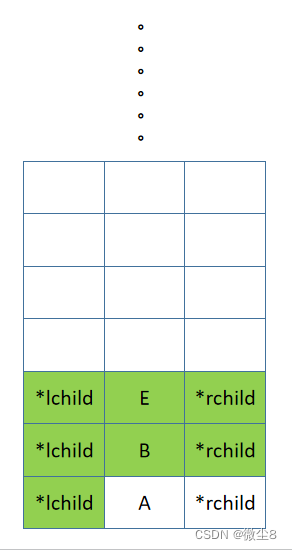
(12)E 结点的右子树为空,则返回
(13)逻辑返回到 E 结点,此时中序遍历 E 结点的左子树,访问 E 结点,中序遍历 E 结点的右子树的逻辑都已完成,则返回,E 结点出栈。
(14)逻辑返回到 B 结点,此时中序遍历 B 结点的左子树,访问 B 结点,中序遍历 B 结点的右子树的逻辑都已完成,则返回,B 结点出栈。
(15)逻辑返回到 A 结点,然后访问 A 结点,再然后中序遍历 A 结点的右子树


(16)A 结点的右子树的根结点为 C,C 结点入栈,先中序遍历 C 结点的左子树


(17)C 结点的左子树的根结点为 F,F 结点入栈,先中序遍历 F 结点的左子树


(18)F 结点的左子树为空,则返回
(19)逻辑返回到 F 结点,然后访问 F 结点,再然后中序遍历 F 结点的右子树

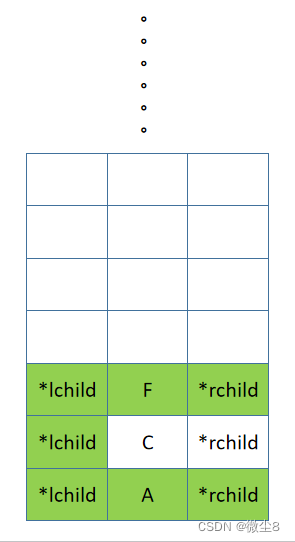
(20)F 结点的右子树为空,则返回
(21)逻辑返回到 F 结点,此时中序遍历 F 结点的左子树,访问 F 结点,中序遍历 F 结点的右子树的逻辑都已完成,则返回,F 结点出栈。
(22)逻辑返回到 C 结点,然后访问 C 结点,再然后中序遍历 C 结点的右子树


(23)C 结点的右子树为空,则返回
(24)逻辑返回到 C 结点,此时中序遍历 C 结点的左子树,访问 C 结点,中序遍历 C 结点的右子树的逻辑都已完成,则返回,C 结点出栈。

(25)逻辑返回到 A 结点,此时中序遍历 A 结点的左子树,访问 A 结点,中序遍历 A 结点的右子树的逻辑都已完成,则返回,A 结点出栈。
(26)中序遍历二叉树已完成, 所以,中序遍历顺序为:DBEAFC
2、实现代码
#include <stdio.h>
#include <string.h>
#include <stdlib.h>char *g_str = "ABD##E##CF###"; // 扩展二叉树前序序列
int g_index = 0;
typedef struct binary_node {char data;struct binary_node *lchild, *rchild;
}binary_tree;void create_binary_tree(binary_tree **T) {if (strlen(g_str) == 0)return;if (g_str[g_index] == '#') {*T = NULL;g_index++;} else {*T = malloc(sizeof(**T));(*T)->data = g_str[g_index];g_index++;create_binary_tree(&(*T)->lchild);create_binary_tree(&(*T)->rchild);}
}void visit_node(binary_tree *T) {printf("%c\n", T->data);
}void pre_order_tree(binary_tree *T) {if (!T)return;visit_node(T);pre_order_tree(T->lchild);pre_order_tree(T->rchild);
}void in_order_tree(binary_tree *T) {if (!T)return;in_order_tree(T->lchild);visit_node(T);in_order_tree(T->rchild);
}/*销毁用后序遍历*/
void destroy_binary_tree(binary_tree *T) {if (!T)return;destroy_binary_tree(T->lchild);destroy_binary_tree(T->rchild);printf("%c\n", T->data);free(T);
}int main(int argc, char *argv[]) {binary_tree *T;create_binary_tree(&T);printf("------中序遍历-------\n");in_order_tree(T);printf("------销毁二叉树------\n");destroy_binary_tree(T);return 0;
}
四、后序遍历二叉树(Post-order Traversal)
后序遍历二叉树(Post-order Traversal)的规则为:从根结点出发,先后序遍历该结点的左子树,然后后序遍历该结点的右子树,再然后访问该结点
所以,后序遍历图1这棵二叉树的步骤如下图所示

所以,图1这颗二叉树后序遍历顺序为:DEBFCA
1、算法思路
(1)从根结点 A 出发,A 结点入栈,先后序遍历 A 结点的左子树
(2)A 结点的左子树的根结点为 B,B 结点入栈,先后序遍历 B 结点的左子树
(3)B 结点的左子树的根结点为 D,D 结点入栈,先后序遍历 D 结点的左子树
(4)D 结点的左子树为空,则返回
(5)逻辑返回到 D 结点,然后后序遍历 D 结点的右子树
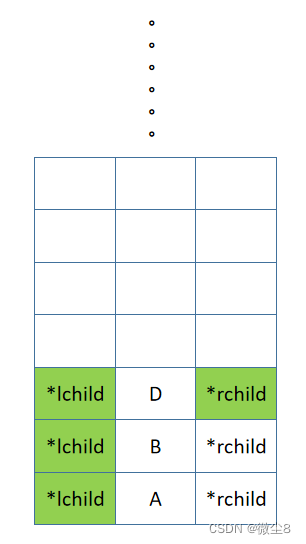
(6)D 结点的右子树为空,则返回
(7)逻辑返回到 D 结点,然后访问 D 结点,此时后序遍历 D 结点的左子树,后序遍历 D 结点的右子树,访问 D 结点的逻辑都已完成,则返回,D 结点出栈。


(8)逻辑返回到 B 结点,然后后序遍历 B 结点的右子树

(9)B 结点的右子树的根结点为 E,E 结点入栈,先后序遍历 E 结点的左子树

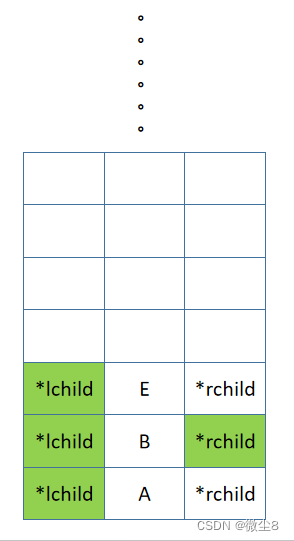
(10)E 结点的左子树为空,则返回
(11)逻辑返回到 E 结点,然后后序遍历 E 结点的右子树

(12)E 结点的右子树为空,则返回
(13)逻辑返回到 E 结点,然后访问 E 结点,此时后序遍历 E 结点的左子树,后序遍历 E 结点的右子树,访问 E 结点的逻辑都已完成,则返回,E 结点出栈。


(14)逻辑返回到 B 结点,然后访问 B 结点,此时后序遍历 B 结点的左子树,后序遍历 B 结点的右子树,访问 B 结点的逻辑都已完成,则返回,B 结点出栈。


(15)逻辑返回到 A 结点,然后后序遍历 A 结点的右子树

(16)A 结点的右子树的根结点为 C,C 结点入栈,先后序遍历 C 结点的左子树


(17)C 结点的左子树的根结点为 F,F 结点入栈,先后序遍历 F 结点的左子树


(18)F 结点的左子树为空,则返回
(19)逻辑返回到 F 结点,然后后序遍历 F 结点的右子树

(20)F 结点的右子树为空,则返回
(21)逻辑返回到 F 结点,然后访问 F 结点,此时后序遍历 F 结点的左子树,后序遍历 F 结点的右子树,访问 F 结点的逻辑都已完成,则返回,F 结点出栈。


(22)逻辑返回到 C 结点,然后后序遍历 C 结点的右子树
(23)C 结点的右子树为空,则返回
(24)逻辑返回到 C 结点,然后访问 C 结点,此时后序遍历 C 结点的左子树,后序遍历 C 结点的右子树,访问 C 结点的逻辑都已完成,则返回,C 结点出栈。


(25)逻辑返回到 A 结点,然后访问 A 结点,此时后序遍历 A 结点的左子树,后序遍历 A 结点的右子树,访问 A 结点的逻辑都已完成,则返回,A 结点出栈。

(26)后序遍历二叉树已完成, 所以,后序遍历顺序为:DEBFCA
2、实现代码
#include <stdio.h>
#include <string.h>
#include <stdlib.h>char *g_str = "ABD##E##CF###"; // 扩展二叉树前序序列
int g_index = 0;
typedef struct binary_node {char data;struct binary_node *lchild, *rchild;
}binary_tree;void create_binary_tree(binary_tree **T) {if (strlen(g_str) == 0)return;if (g_str[g_index] == '#') {*T = NULL;g_index++;} else {*T = malloc(sizeof(**T));(*T)->data = g_str[g_index];g_index++;create_binary_tree(&(*T)->lchild);create_binary_tree(&(*T)->rchild);}
}void visit_node(binary_tree *T) {printf("%c\n", T->data);
}void pre_order_tree(binary_tree *T) {if (!T)return;visit_node(T);pre_order_tree(T->lchild);pre_order_tree(T->rchild);
}void in_order_tree(binary_tree *T) {if (!T)return;in_order_tree(T->lchild);visit_node(T);in_order_tree(T->rchild);
}void post_order_tree(binary_tree *T) {if (!T)return;post_order_tree(T->lchild);post_order_tree(T->rchild);visit_node(T);
}/*销毁用后序遍历*/
void destroy_binary_tree(binary_tree *T) {if (!T)return;destroy_binary_tree(T->lchild);destroy_binary_tree(T->rchild);printf("%c\n", T->data);free(T);
}int main(int argc, char *argv[]) {binary_tree *T;create_binary_tree(&T);printf("------后序遍历-------\n");post_order_tree(T);printf("------销毁二叉树------\n");destroy_binary_tree(T);return 0;
}