1.目的
找到一个可运行的代码,可以每个epoch打印训练数据,但是不会保存。因为在改进模型需要这些训练数据进行对比,所以需要将每个epoch的训练数据保存下来,写到一个文件中。
2.解决方案1
直接问ChatGPT,提示词如下:
做一个深度学习的图像分类任务,现在需要将每个epoch的训练数据存到一个文件,用python来实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import json# 定义一个简单的网络
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.fc1 = nn.Linear(32 * 28 * 28, 10)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = x.view(x.size(0), -1)x = self.fc1(x)return x# 设置超参数
batch_size = 64
num_epochs = 10
learning_rate = 0.01# 创建数据集和数据加载器
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='data/', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)# 创建网络、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 文件名
output_file = "training_data.json"# 开始训练
training_data = []for epoch in range(num_epochs):epoch_loss = 0.0correct = 0total = 0# 训练一个 epochfor inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()epoch_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)correct += predicted.eq(labels).sum().item()total += labels.size(0)# 计算平均损失和准确度avg_loss = epoch_loss / totalaccuracy = correct / total# 将 epoch 的数据添加到列表中epoch_data = {"epoch": epoch + 1,"avg_loss": avg_loss,"accuracy": accuracy}training_data.append(epoch_data)# 打印 epoch 的训练结果print(f"Epoch {epoch + 1}: Avg Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")# 将所有 epoch 的训练数据保存到文件中
with open(output_file, 'w') as f:json.dump(training_data, f)print(f"Training data saved to {output_file}")
由于缺少数据集,也懒得去找一个数据集,就将自己py文件中训练部分摘出来给ChatGPT,让它在训练方法中实现这个功能。
def train():data_format(os.path.join(config.root_path, './data/train.txt'),os.path.join(config.root_path, './data/data'), os.path.join(config.root_path, './data/train.json'))data = read_from_file(config.train_data_path, config.data_dir, config.only)train_data, val_data = train_val_split(data)train_loader = processor(train_data, config.train_params)val_loader = processor(val_data, config.val_params)best_acc = 0epoch = config.epochfor e in range(epoch):print('-' * 20 + ' ' + 'Epoch ' + str(e+1) + ' ' + '-' * 20)# 训练模型tloss, tloss_list = trainer.train(train_loader)print('Train Loss: {}'.format(tloss))# writer.add_scalar('Training/loss', tloss, e)# 验证模型vloss, vacc = trainer.valid(val_loader)print('Valid Loss: {}'.format(vloss))print('Valid Acc: {}'.format(vacc))# writer.add_scalar('Validation/loss', vloss, e)# writer.add_scalar('Validacc/acc', vacc, e)# 保存训练数据training_data = {"epoch": e + 1,"train_loss": tloss,"valid_loss": vloss,"valid_acc": vacc}with open('training_data.json', 'a') as f:json.dump(training_data, f)f.write('\n')print("数据保存完成")# 保存最佳模型if vacc > best_acc:best_acc = vaccsave_model(config.output_path, config.fuse_model_type, model)print('Update best model!')print('-' * 20 + ' ' + 'Training Finished' + ' ' + '-' * 20)print('Best Validation Accuracy: {}'.format(best_acc))
在我的代码中具体加入的是下列几行代码
# 保存训练数据
training_data = {"epoch": e + 1,"train_loss": tloss,"valid_loss": vloss,"valid_acc": vacc
}
with open('training_data.json', 'a') as f:json.dump(training_data, f)f.write('\n')
print("数据保存完成")
代码意思如下:
with open('training_data.json', 'a') as f:: 打开名为'training_data.json'的文件,以追加模式'a',并将其赋给变量f。如果文件不存在,将会创建一个新文件。json.dump(training_data, f): 将变量training_data中的数据以 JSON 格式写入到文件f中。这个操作会将training_data中的内容转换成 JSON 格式,并写入到文件中。f.write('\n'): 写入一个换行符\n到文件f中,确保每次写入 JSON 数据后都有一个新的空行,使得每个 JSON 对象都独占一行,便于后续处理。这段代码的作用是将变量
training_data中的数据以 JSON 格式写入到文件'training_data.json'中,并确保每次写入后都有一个换行符分隔。
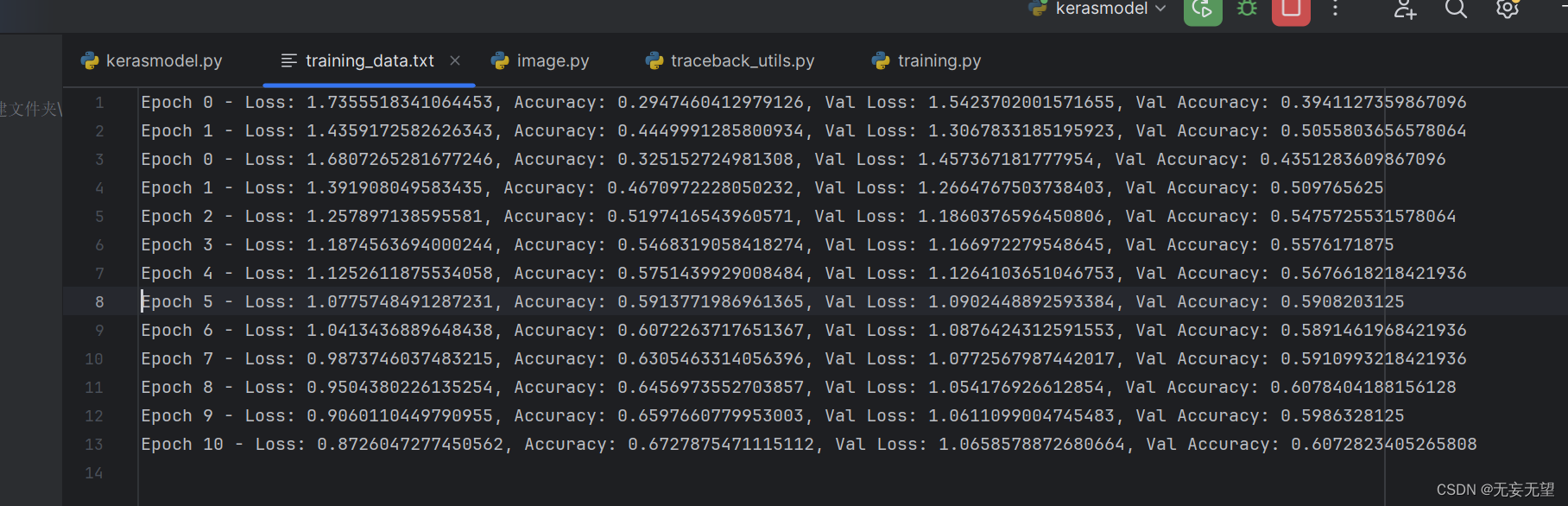
结果
可以在每个epoch训练完成后,将训练损失,验证损失和验证准确率保存在training_data.json文件中。

3.解决方案2
这是另外一个代码,使用的是tensoflow来构建网络,代码如下
model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48,48,1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))# If you want to train the same model or try other models, go for this
if mode == "train":# 使用旧版本的Adam优化器model.compile(loss='categorical_crossentropy', optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001, decay=1e-6),metrics=['accuracy'])model_info = model.fit_generator(train_generator,steps_per_epoch=num_train // batch_size,epochs=num_epoch,validation_data=validation_generator,validation_steps=num_val // batch_size,)train_loss = model_info.history['loss']train_accuracy = model_info.history['accuracy']val_loss = model_info.history['val_loss']val_accuracy = model_info.history['val_accuracy']plot_model_history(model_info)model.save_weights('model.h5')
询问ChatGPT
import tensorflow as tfclass SaveTrainingDataCallback(tf.keras.callbacks.Callback):def __init__(self, file_path):super(SaveTrainingDataCallback, self).__init__()self.file_path = file_pathdef on_epoch_end(self, epoch, logs=None):with open(self.file_path, 'a') as file:file.write(f'Epoch {epoch} - Loss: {logs["loss"]}, Accuracy: {logs["accuracy"]}\n')# 您可以根据需要保存其他训练数据,如验证集的损失和准确率等# 创建模型
model = tf.keras.Sequential([tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),tf.keras.layers.MaxPooling2D((2, 2)),tf.keras.layers.Flatten(),tf.keras.layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 创建Callback来保存训练数据
save_data_callback = SaveTrainingDataCallback(file_path='training_data.txt')# 训练模型并在每个epoch结束时保存训练数据
model.fit(x_train, y_train, epochs=10, callbacks=[save_data_callback])
要保存每个epoch的训练数据并将其存放到一个文件中,您可以使用
Callback回调函数来实现。Callback提供了在训练过程中执行特定操作的灵活性,包括在每个epoch结束时保存训练数据。
然后改写到自己代码为
model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48,48,1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))import tensorflow as tfclass SaveTrainingDataCallback(tf.keras.callbacks.Callback):def __init__(self, file_path):super(SaveTrainingDataCallback, self).__init__()self.file_path = file_pathdef on_epoch_end(self, num_epoch, logs=None):with open(self.file_path, 'a') as file:file.write(f'Epoch {num_epoch} - Loss: {logs["loss"]}, Accuracy: {logs["accuracy"]}, Val Loss: {logs["val_loss"]}, Val Accuracy: {logs["val_accuracy"]}\n')# If you want to train the same model or try other models, go for this
if mode == "train":# 使用旧版本的Adam优化器model.compile(loss='categorical_crossentropy', optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001, decay=1e-6),metrics=['accuracy'])# 创建Callback来保存训练数据save_data_callback = SaveTrainingDataCallback(file_path='training_data.txt')model_info = model.fit_generator(train_generator,steps_per_epoch=num_train // batch_size,epochs=num_epoch,validation_data=validation_generator,validation_steps=num_val // batch_size,callbacks=[save_data_callback])train_loss = model_info.history['loss']train_accuracy = model_info.history['accuracy']val_loss = model_info.history['val_loss']val_accuracy = model_info.history['val_accuracy']plot_model_history(model_info)model.save_weights('model.h5')
添加的代码为
import tensorflow as tfclass SaveTrainingDataCallback(tf.keras.callbacks.Callback):def __init__(self, file_path):super(SaveTrainingDataCallback, self).__init__()self.file_path = file_pathdef on_epoch_end(self, num_epoch, logs=None):with open(self.file_path, 'a') as file:file.write(f'Epoch {num_epoch} - Loss: {logs["loss"]}, Accuracy: {logs["accuracy"]}, Val Loss: {logs["val_loss"]}, Val Accuracy: {logs["val_accuracy"]}\n') #在这个示例中,我们定义了一个自定义的回调函数SaveTrainingDataCallback ,在每个epoch结束时将训练和验证数据写入到指定的文件中。然后我们创建了一个回调函数实例,并将其传递给模型的fit方法中,以在模型训练时保存训练数据。# 创建Callback来保存训练数据 save_data_callback = SaveTrainingDataCallback(file_path='training_data.txt')callbacks=[save_data_callback]
结果