YOLTV8 — 大尺度图像目标检测框架【ABCnutter/YOLTV8: 🚀】
针对大尺度图像(如遥感影像、大尺度工业检测图像等),由于设备的限制,无法利用图像直接进行模型训练。将图像裁剪至小尺度进行训练,再将训练结果进行还原拼接是解决该问题的普遍思路。YOLT项目([1805.09512] You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery (arxiv.org))是该思路具体实现,其以改进的YOLOV2作为检测框架,通过重叠裁剪预测处理以及对目标检测框拼接还原结果进行NMS过滤实现大尺度遥感影像的小型目标检测。但在具体方案操作时,本项目作者发现该方法存在以下几点问题:
-
无法较好地同时性地解决拼接结果中不同类别物体重叠检测框的精确过滤,尤其是位于图像边缘的不完整物体的检测框,会牺牲一定的检测精度。
-
由于裁剪造成图像中的大型物体被分割于数块图像中,存在无法在单张影像中完整捕获物体的缺陷
-
所使用的YOLOV2检测框架已经较为落后,已无法满足现在任务场景对检测精度的需求。
因此,本项目以最新的YOLOV8为检测框架,增设多尺度,多信息的预处理模块,捕获大尺度图像的多尺度上下文信息,能够有效识别出大尺度图像的大小型识别物体以及密集型检测目标。另外,此次我们还对对原始NMS算法进行改进,以满足不同类型物体以及重叠框(尤其是位于边缘的检测框)的过滤,实现大尺度影像的精确检测。
项目实战展示
- 煤渣传送带异常物体检测

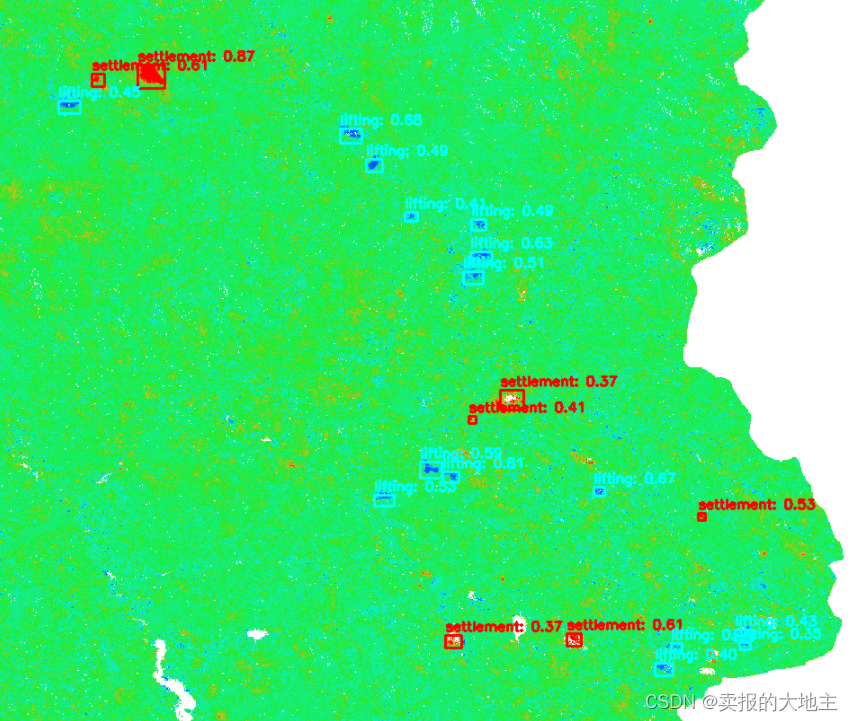
- 基于InSAR影像的地表沉陷变化监测
Install
window
1、CPU推理环境配置:
1.1、Pip (recommended)
pip install ultralytics
1.2、conda
conda create -n yoltv8 python=3.9
conda activate yoltv8
conda install ultralytics
2、GPU推理环境配置:
Note:默认已安装配置gpu环境下的pytorch深度学习环境,如未配置,请先进行配置
2.1、Pip(recommended)
pip install ultralytics
2.2、conda
conda create -n yoltv8 python=3.9
conda activate yoltv8
conda install ultralytics
Usage
本项目支持命令行参数,可通过设置命令行参数进行模型推理,请在yoltv8\predict.py下运行,相关命令行参数如下:
[--images_dir IMAGES_DIR] # 所存放照片的文件夹路径, 默认为:yoltv8\dataset\predict\init_images\项目名称
[--outdir_slice_ims OUTDIR_SLICE_IMS] # 图像分割结果路径,无需设置,会自动生成,默认为:yoltv8\dataset\predict\slice_images\项目名称
[--project_name PROJECT_NAME]
# 一次推理任务的项目名称,推理结果的ID,不同任务请不用重复,否则会覆盖结果。
# yolov8原始模型预测结果路径:yoltv8\results\yolov8_detect\项目名称, 自动生成,无需修改
[--im_ext IM_EXT] # 推理文件的后缀名称,如.jpg
[--sliceHeight SLICEHEIGHT] # 图像裁剪高度, 默认1088, 根据具体情况更改
[--sliceWidth SLICEWIDTH] # 图像裁剪宽度. 默认1088
[--overlap OVERLAP] # 图像裁剪重复率,默认0.5,太小会出现无法捕获大型目标的完整检测框
[--slice_sep SLICE_SEP] # 分割结果名称的分隔符号,默认'_'
[--overwrite OVERWRITE] # 图像裁剪结果已存在时是否重写, 默认Flase
[--out_ext OUT_EXT] # 裁剪结果的后缀名称,默认.png
[--model MODEL] # 模型训练结果文件
[--conf CONF] # 检测对象置信度阈值
[--iou IOU] # NMS的交集联合(IoU)阈值
[--half HALF] # 是否使用半精度(FP16)
[--device DEVICE] # 要运行的设备,即cuda设备=0/1/2/3或设备=cpu
[--show SHOW] # 如果可能,显示结果
[--save SAVE] # 保存带有结果的图像
[--save_txt SAVE_TXT] # 将结果保存为. txt文件
[--save_conf SAVE_CONF] # 使用置信度分数保存结果
[--save_crop SAVE_CROP] # 保存带有结果的裁剪图像
[--hide_labels HIDE_LABELS] # 是否隐藏标签
[--hide_conf HIDE_CONF] # 是否隐藏置信度
[--max_det MAX_DET] # 每张图像的最大检测次数
[--vid_stride VID_STRIDE] # 视频帧率步幅
[--line_width LINE_WIDTH] # 边界框的线宽。如果无,则按图像大小缩放。
[--visualize VISUALIZE] # 可视化模型特征
[--augment AUGMENT] # 将图像增强应用于预测源
[--agnostic_nms AGNOSTIC_NMS] # 与类无关的NMS
[--retina_masks RETINA_MASKS] # 使用高分辨率分割掩码
[--classes CLASSES [CLASSES ...]] # 按类过滤结果,即class=0,或class=[0,2,3]
[--boxes BOXES] # 在分割预测中显示框
[--output_file_dir OUTPUT_FILE_DIR] # 模型预测最后txt结果文件的路径,无需修改,默认为:yoltv8\results\completed_txt\项目名称, txt结果会自动成在此路径下
[--iou_threshold IOU_THRESHOLD] # 回归大图时进行perclassnms的iou阈值,默认为0.01,即,默认同类物体其检测框不应该出现重叠,符合当前任务需求,可根据实际情况修改
[--confidence_threshold CONFIDENCE_THRESHOLD] # 回归大图时进行perclassnms的置信度阈值,默认为0.5
[--area_weight AREA_WEIGHT] # 回归大图时进行perclassnms的置信度与面积的比例权重,默认为5
[--class_labels CLASS_LABELS [CLASS_LABELS ...]] # 类别的标签结果,默认[0, 1, 2, 3, 4, 5]
[--class_names CLASS_NAMES [CLASS_NAMES ...]] # 类别标签对应的名称,默认怕["head", "boxholder", "greendevice", "baseholer", "circledevice", "alldrop"]
[--completed_output_path COMPLETED_OUTPUT_PATH] # 模型预测最后txt结果文件的路径,无需修改,默认为:yoltv8\results\completed_predict\项目名称, 图像结果会自动成在此路径下
本次任务一般仅需要修改以下参数(其他参数可保持默认,请根据实际情况进行设置):
-
images_dir参数,指定你所存放照片的文件夹路径(注意照片路径,而是存在照片的上级文件夹路径,路径及照片名称中不可出现中文汉字),
如:–image_dir E:\yoltv8\dataset\predict\init_images, 可将推理照片存放在默认dataset\predict\init_images路径下。
-
im_ext参数,你所需要进行推理的照片格式,如.jpg、.png等(无需区分大小写,但要注意不要遗忘了 . )。推理时,只会对images_dir下的以im_ext为后缀名的文件进行推理。
-
model参数,指定模型结果文件的路径,如 --model E:\yoltv8\checkpoint\best.pt,除pt文件外,也支持onnx文件、engine文件等yolov8等官方支持的模型结果文件格式。
命令行启动示例:
python predict.py --images_dir E:\yoltv8\dataset\predict\init_images --im_ext .jpg --model E:\yoltv8\checkpoint\best.pt
本项目还可直接修改predict.py文件中的命令函参数设置部分,这样就无需再命令行中进行修改,,修改参数信息后直接启动predict.py即可。各参数信息和前文一样。
parser = argparse.ArgumentParser()
parser.add_argument("--images_dir", type=str, default=os.path.join(PROJECT_ROOT, 'dataset', 'predict', 'init_images'))
parser.add_argument("--outdir_slice_ims", type=str, default=os.path.join(PROJECT_ROOT, 'dataset', 'predict', 'slice_images'))
parser.add_argument("--project_name", type=str, default="sensor_detect")
parser.add_argument("--im_ext", type=str, default=".jpg")
parser.add_argument("--sliceHeight", type=int, default=1088)
parser.add_argument("--sliceWidth", type=int, default=1088)
parser.add_argument("--overlap", type=float, default=0.5)
parser.add_argument("--slice_sep", type=str, default="_")
parser.add_argument("--overwrite", type=bool, default=False)
parser.add_argument("--out_ext", type=str, default=".png")
parser.add_argument("--model", type=str, default=r"E:\yoltv8\checkpoint\best.pt")
parser.add_argument("--conf", type=float, default=0.25) # object confidence threshold for detection
parser.add_argument("--iou", type=float, default=0.7) # intersection over union (IoU) threshold for NMS
parser.add_argument("--half", type=bool, default=False) # use FP16 half-precision inference
parser.add_argument("--device", type=str, default=None) # cuda device, i.e. 0 or 0,1,2,3 or
parser.add_argument("--show", type=bool, default=False) # show results
parser.add_argument("--save", type=bool, default=True) # save images with results
parser.add_argument("--save_txt", type=bool, default=True) # save results"
parser.add_argument("--save_conf", type=bool, default=True)
parser.add_argument("--save_crop", type=bool, default=False) # save cropped prediction boxes
parser.add_argument("--hide_labels", type=bool, default=False) # hide labels
parser.add_argument("--hide_conf", type=bool, default=False)
parser.add_argument("--max_det", type=int, default=300) # maximum detections per image
parser.add_argument("--vid_stride", type=bool, default=False) # video frame-rate stride
parser.add_argument("--line_width", type=float, default=None)
parser.add_argument("--visualize", type=bool, default=False)
parser.add_argument("--augment", type=bool, default=False)
parser.add_argument("--agnostic_nms", type=bool, default=False)
parser.add_argument("--retina_masks", type=bool, default=False)
parser.add_argument("--classes", type=int, nargs="+", default=None)
parser.add_argument("--boxes", type=bool, default=True)
parser.add_argument("--output_file_dir", type=str, default=os.path.join(PROJECT_ROOT, 'results', 'completed_txt'))
parser.add_argument("--iou_threshold", type=float, default=0.01)
parser.add_argument("--confidence_threshold", type=float, default=0.5)
parser.add_argument("--area_weight", type=float, default=5)
parser.add_argument("--class_labels", type=int, nargs="+", default=[0, 1, 2, 3, 4, 5])
parser.add_argument("--class_names", type=str, nargs="+", default=["head","boxholder","greendevice","baseholer","circledevice","alldrop",])
parser.add_argument("--completed_output_path", type=str, default=os.path.join(PROJECT_ROOT, 'results', 'completed_predict')))
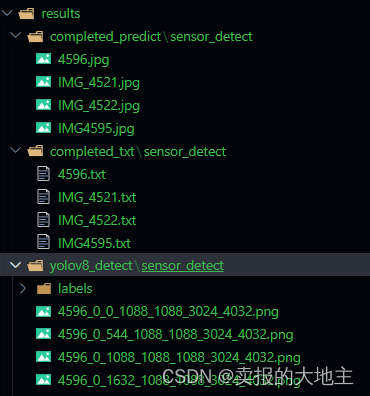
结果路径示例展示(sensor_detect为本次推理的项目名称):
注:多尺度,多信息的预处理模块还未上传,但不影响正常使用,可先增大裁剪尺寸以及重叠率来避免超大物体(无法在单幅影像块中完整给出的物体)的识别不完整。