目录
编辑
1.什么是回溯
2.关于剪枝
3.关于恢复现场
4.题目:二叉树的所有路径(凸显恢复现场:切实感受回溯与深搜)
问题分析
①函数设置为:void Dfs(root)
②函数设置为:void Dfs(root,path)
解题思想:使⽤深度优先遍历(DFS)求解。
代码实现
5.N后问题
问题分析
4皇后的放置方式
首先我们先在第一行进行落子:共有四种放置方式
接下来我们考虑往第二行的落子:
接下来我们考虑第三行落子:
接下来我们考虑第4行落子:
代码实现:
①对同列分析
②对于对角线的位置:
主对角线:
副对角线:
代码实现:
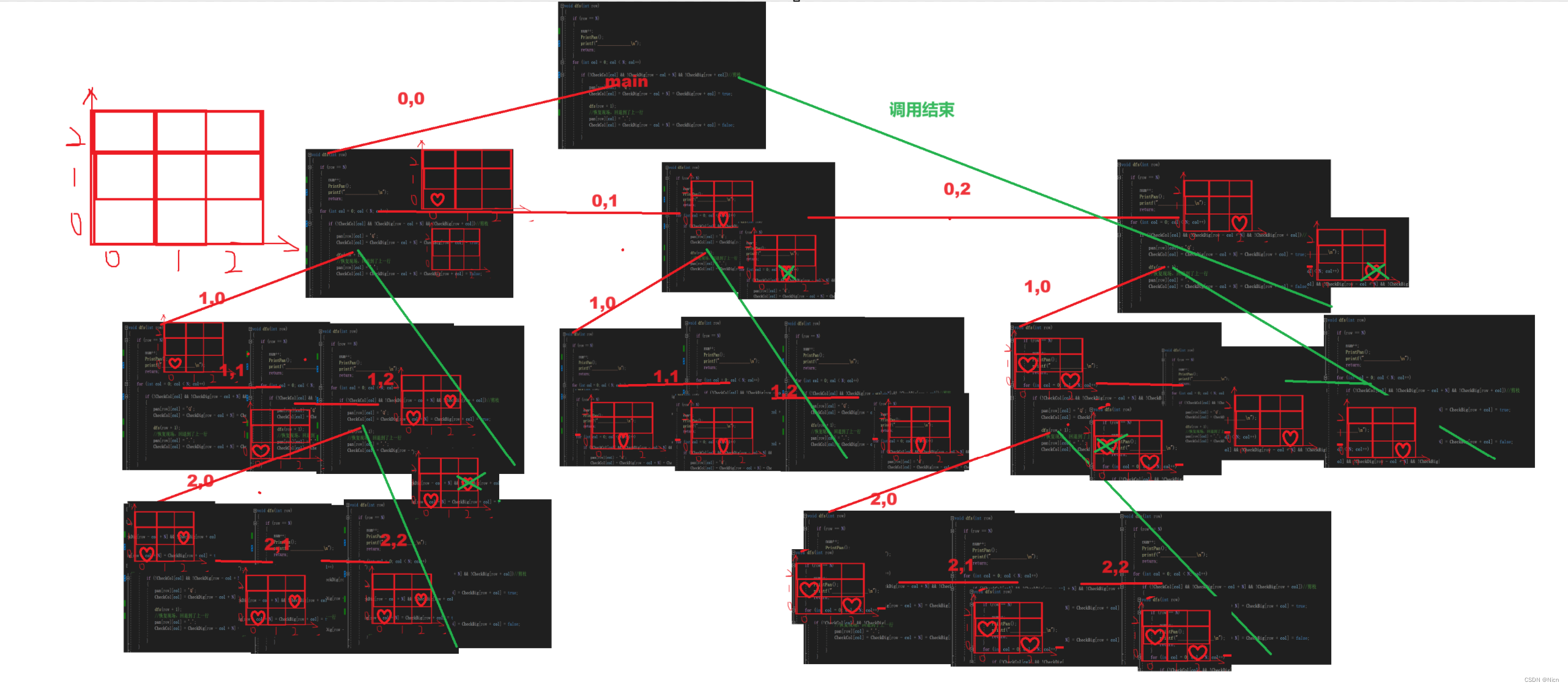
递归展开图
时间复杂度
空间复杂度
6.总结
1.什么是回溯
如果说递归是一个大的集合,搜索是递归的一个分支,如果说搜索是一个大的集合,回溯是搜索的分支,二者之间就差一步。
一个故事引入:
在初中的时候,那时候黑网吧很多,几个小伙伴周五放学没事就要去网吧玩几把lol,但是黑网吧为了不被查封,往往很隐蔽,那么现在有个网吧老板反侦察意识很强,把网吧放在一个迷宫后面,几个同学听说这边新网吧刚开业,冲一送四个钟,泡面随便冲,周五放学就按捺不住要去了,但是第一次去也没有路线,没有办法,只能走迷宫,越是几个哥们就出发了,来到分叉路口,哥几个决定先走一边尝试一下,万一就选对路线了呢。
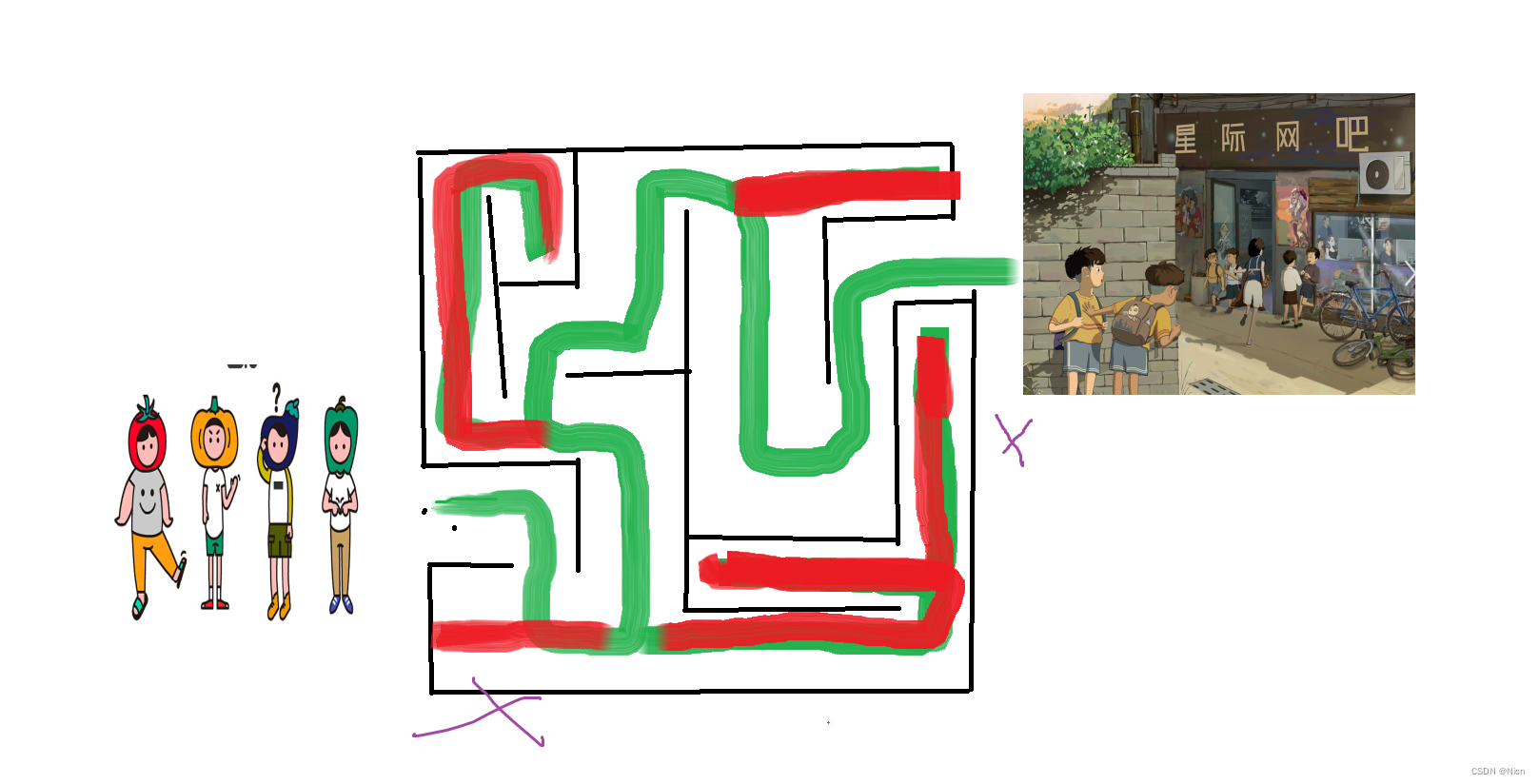
然后来到第一个路口向右转,发现走不同,然后就回头到上一个路口,从新选择方向。
(从哥几个撞墙走不通回到上一个起点重新选择的这个过程就叫做回溯)。哥几个回到了路口,重新选择,这时候有个伙伴珊珊来迟,看见几个伙伴站在路口,就问,走那边,所有人都说走左边,新来的说为什么不走右边,几个弟兄回答说:左边去过了走不通,果断放弃,你要去你就自己去。 (明确知道其中一个选择不是我们想要的结果的时候,我们不走这个选择。这个就叫做剪枝)于是哥几个就用这样的方法走出迷宫,来到网吧度过了一个快乐的周五。
所以:
回溯算法实际上一个类似枚举的搜索尝试过程,在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法本质是一种深度搜索法,按条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择达不到目标,就退回一步重新选择,这种走不通就退回再走的方法为回溯法,可以说回溯就是深度搜索。
啊,这么一说回溯不就是递归吗?实际上这么说也对,因为递归当中就隐藏着回溯的过程,我们来看一下深度搜索的一种例子:比如我们二叉树的后续遍历,(遍历是一种方法,搜索是目的)
二叉树的后续遍历中,我们先访问左子树,在访问右子树,最后访问节点,是不是涉及到到左右子树在回到左右子树的过程,这实际上就是一种深度遍历,
深度优先遍历 dfs:一条道走到黑,走到不可以再往下走,回去有分支往深处走
深度优先搜索:遍历目的就是为了找值也就是搜索(可以画出决策树的问题都可以使用搜索。)
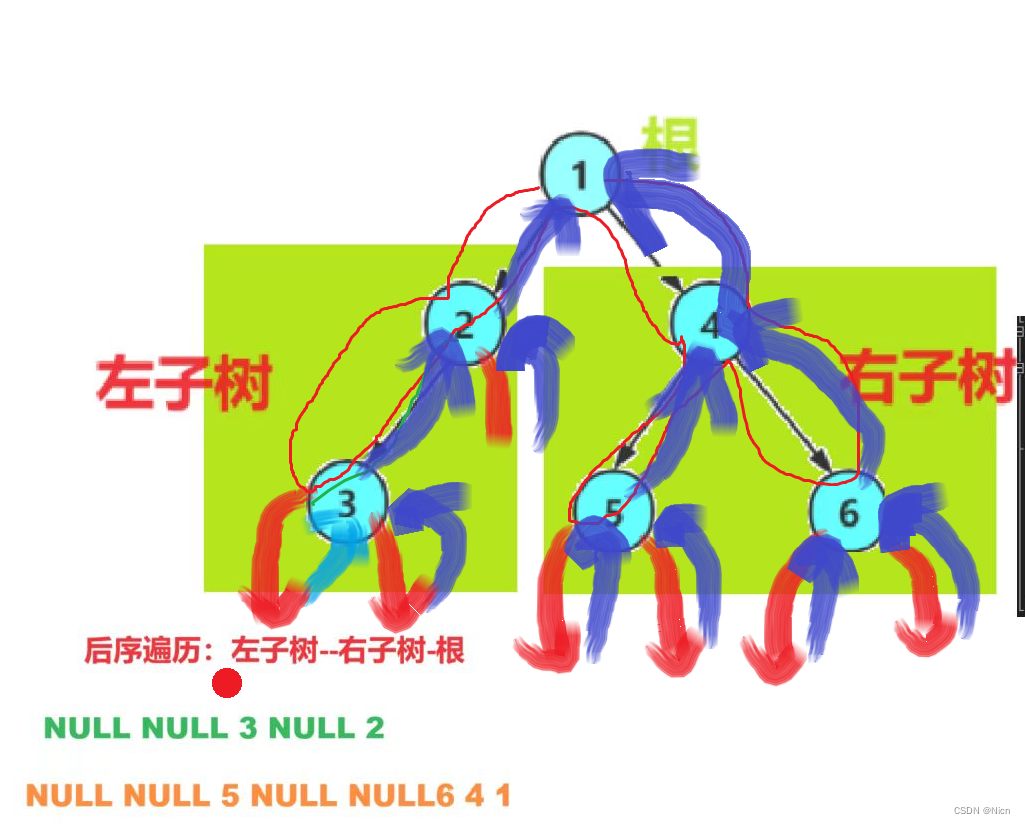
紫色的过程就是回溯
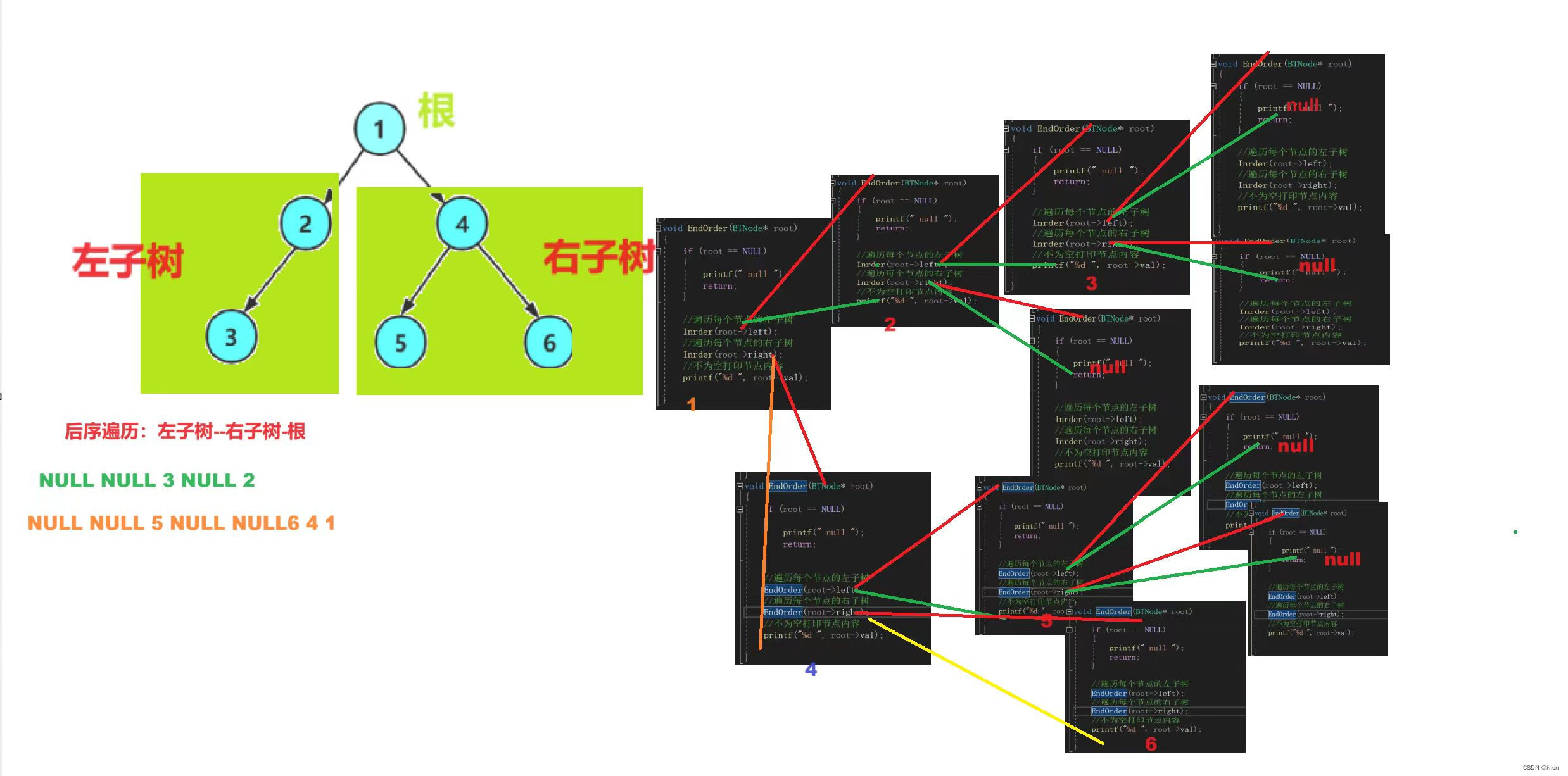
这是递归和深度搜索dfs
而回溯算法的基本思想:从⼀个初始状态开始,按照⼀定的规则向前搜索,当搜索到某个状态⽆法前进 时,回退到前⼀个状态,再按照其他的规则搜索。回溯算法在搜索过程中维护⼀个逻辑状态树,通过遍历 状态树来实现对所有可能解的搜索。
回溯算法的核⼼思想:“试错”,即在搜索过程中不断地做出选择,如果选择正确,则继续向前搜 索;否则,回退到上⼀个状态,重新做出选择。回溯算法通常⽤于解决具有多个解,且每个解都需要 搜索才能找到的问题。关于多米洛问题的理解:问题衍生出子问题,子问题又衍生出相同的子问题。
那么深度搜索和回溯算法的区别在哪里呢:
回溯本质是深搜这个说法没错,先说结论:在我的理解中,回溯和递归或者深度优先搜索算法的区别是在某些题目回溯强化了:①”剪枝的动作 ②回溯里面的‘恢复现场’的概念和实现。
就是说深度优先搜索或者遍历来说是一种穷举就是列出所有的情况,但是回溯算法中可以通过剪枝动作来规避掉一些不想要的结果,一般情况下,这就减少了工程量,虽然在算法复杂度量级上体现的不明显。 但是如果所有的结果都是我们想要的,此时剪枝动作就没有很大的意义,或者说没有办法发挥作用,那么我们的回溯和一个深度穷举效率是差不多的。也可以理解为二者是一个方法
所以:我们可以说:回溯 = 深度搜索+强化剪枝+强化恢复现场
下面我们理解一下什么叫做剪枝和恢复现场:
2.关于剪枝
在我们家乡,二三月份果树开苞的时候,就要将那些没有果和果少的树枝剪去,让好的和大的果苞能吸收到更多的养分。我们减去的树枝首先就是不符合我们的要求才剪去了,比如没有果子。

在回溯算法中,我们将明确知道其的中一个选择不是我们想要的结果的时候,我们不走或者叫做排除这个选择。由于回溯算法的问题一般都可以转换成一颗逻辑决策树,
比如求3皇后的问题:不用知道只是介绍剪枝
所以在使用回溯算法时,将我们不需要的结果规避掉(直接不走那个分支,因为知道那个分支没有我们需要的结果),也就叫做剪枝,生动形象。
3.关于恢复现场
在刚才的迷宫问题中,所有人回退到路口重新进行选择的过程就是一种恢复现场的动作。
很多时候,特别是当我们学完回溯过后,有一种错觉:看到了代码中的“恢复现场”动作,我们就大脑自动反应:这个题解使用了回溯算法,实际上这种想法需要纠正一下:是因为出现了回溯我们才要想到去恢复现场。这样我们在代码实现的时候才能反应过来,出现了回溯的过程,那么就要考虑恢复现场。
所以:
什么是回溯:只要出现递归就伴随着回溯,只要出现深度优先遍历就伴随着回溯,只不过,在某些简单的题目中,我们递归调用函数传入参数的时候实际上已经是一个恢复现场的动作了。
比如二叉树的后续遍历中,

左子树遍历完,进行右子树的遍历,这个传递的参数实际上就是一种简单的恢复现场
但是如果传递的参数是一个全局变量或者是传地址调用的时候,我们在进行下步操作的时候就要考虑一下需不需要恢复现场了。
有了上面的铺垫大家心里应该对回溯有了一点认识,接下来我们来一道简单的题目来配合理解一下上面的概念。
4.题目:二叉树的所有路径(凸显恢复现场:切实感受回溯与深搜)

问题分析
首先我们需要两个数组,一个用来存储所有的路径,也就是最终的结果。一个就是我们保存我们的单条路径。
- 1. 如果当前节点不为空,就将当前节点的值加⼊路径 path 中,否则直接返回;
- 2. 判断当前节点是否为叶⼦节点,如果是,则将当前路径加⼊到所有路径的存储数组 paths 中;
- 3. 否则,将当前节点值加上 "->" 作为路径的分隔符,继续递归遍历当前节点的左右⼦节点。
- 4. 返回结果数组。
①函数设置为:void Dfs(root)
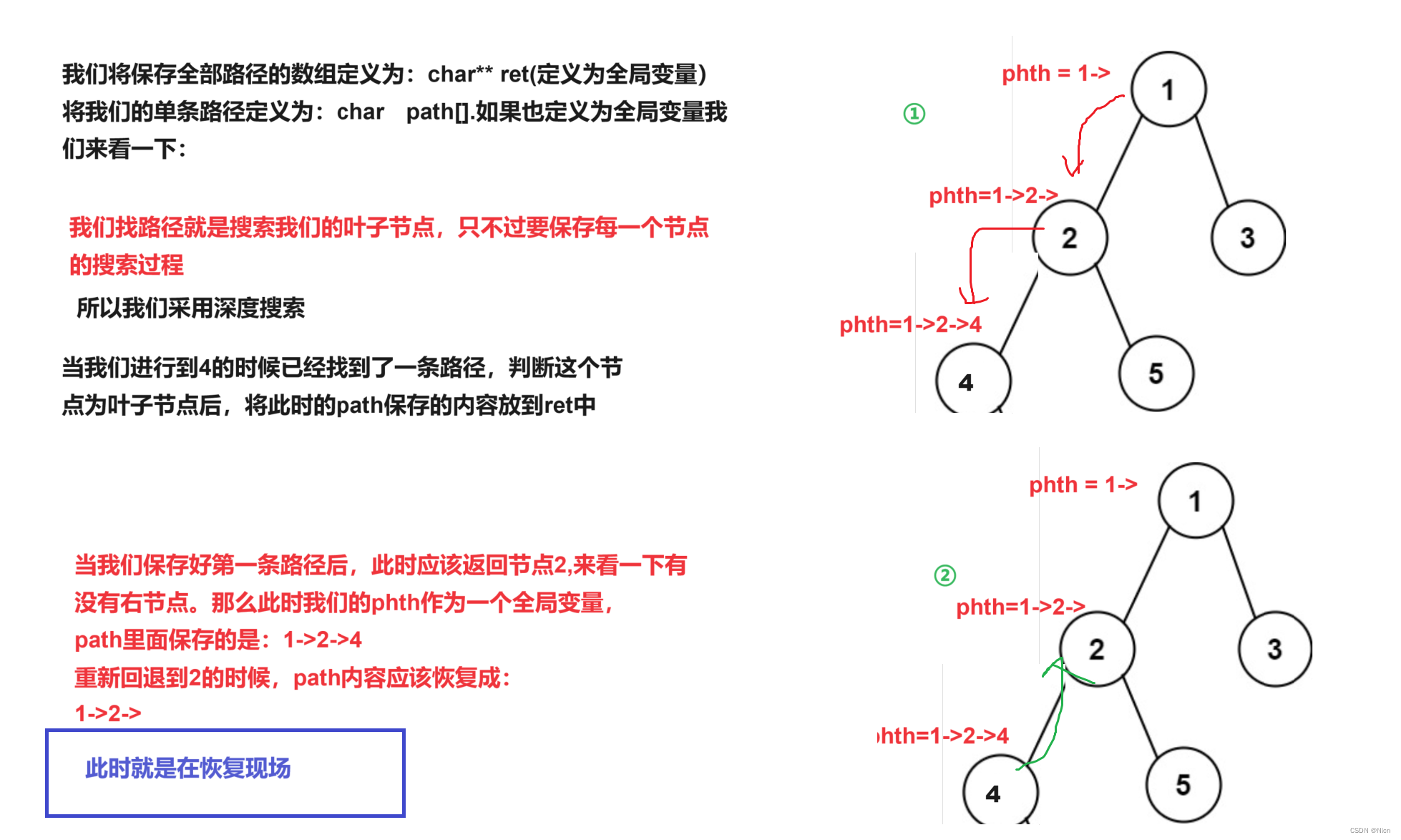
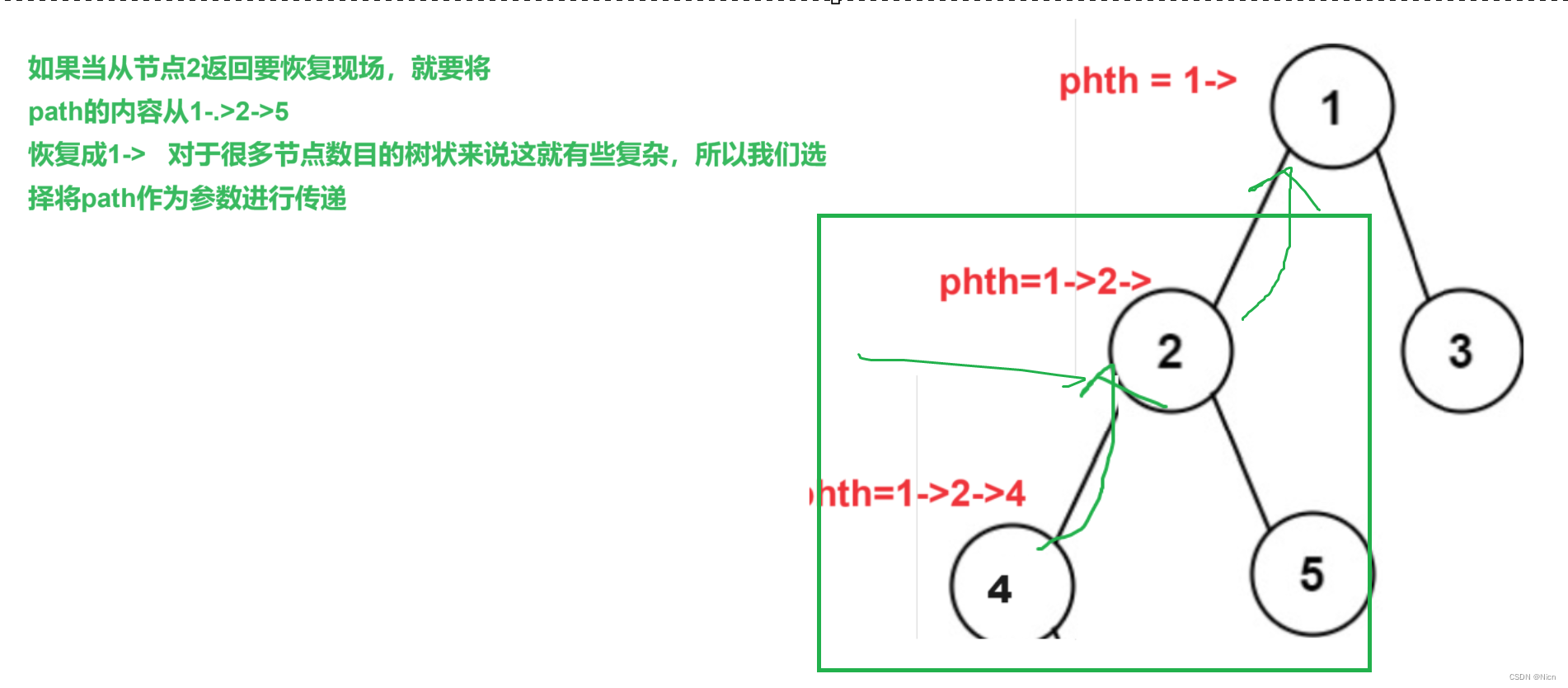
②函数设置为:void Dfs(root,path)
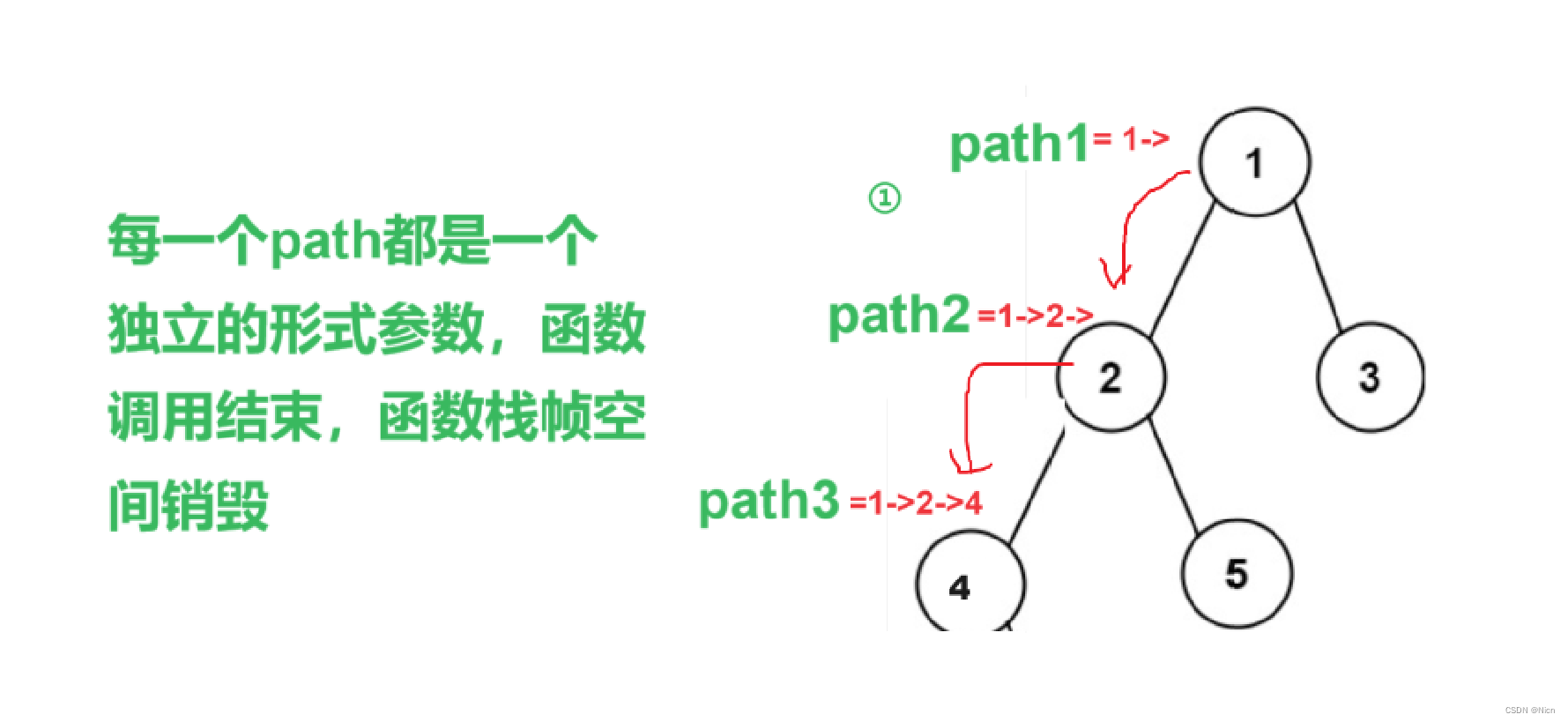
剪枝的体现:在判断叶子节点的时候,如果当前节点的左右节点不为空我们就进入,为空不满足我们的条件,我们就不进入。这道题目剪枝不剪枝都可以,不剪枝可能就理解成深度搜索算法,有个剪枝也可以进一步理解为回溯。
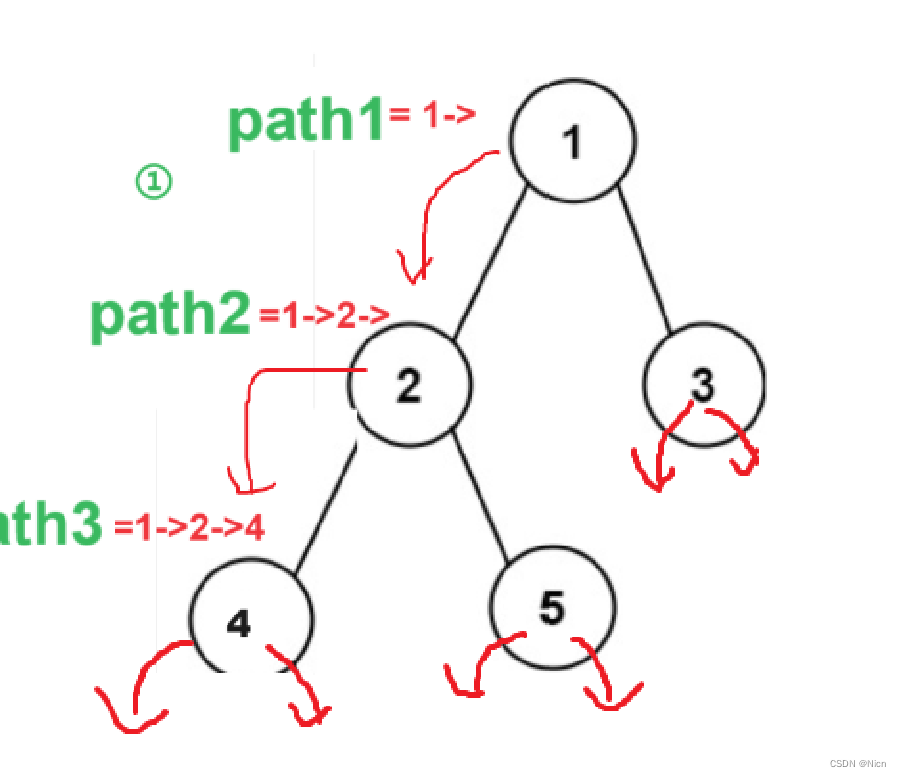
解题思想:使⽤深度优先遍历(DFS)求解。
代码实现
void dfs(struct TreeNode* root,char* path,int len , char** str,int * strcount){assert(root);sprintf(path+len,"%d",root->val);len = len+1;if(root->left==NULL&&root->right==NULL){str[*strcount] = path;*strcount++;return;}if(root->left){sprintf(path+len,"->");len = len+1;dfs(root->left,path,len,str,strcount);}if(root->right){sprintf(path+len,"->");len = len+1;dfs(root->right,path,len,str,strcount);}{}}char** str = (char**)malloc(sizeof(char*)*n);//定义一个字符串数组来存储路径char *path = (char*)malloc(1001);int len = 0; int strcount = 0;dfs(root,path,len,str,&strcount);free(path);path = NULL;return str;
C语言代码目前有点问题,不过可以提供参考。
5.N后问题
. - 力扣(LeetCode)
问题分析
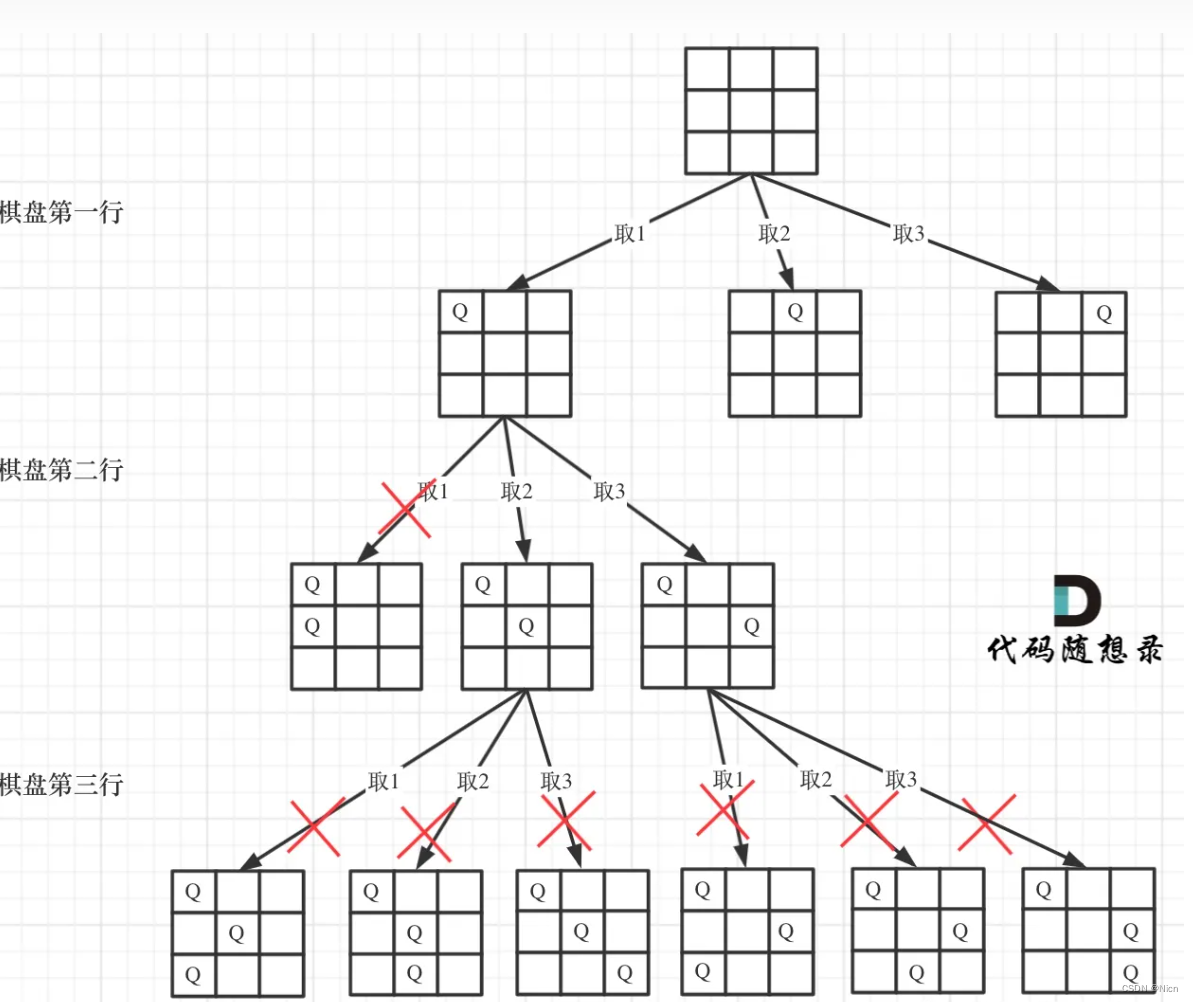
简单点:有几个皇后就是一个几乘以几的棋盘,然后当我们在一个位置放上一个棋子后,同行同列,同对角线不可以放第二枚棋子,然后要求n个棋子有多少种方法。
算法思想:①对每个位置进行枚举,也就是一个小格子一个小格子的去判断,就是对于每个位置试着放,看能不能放,如果是从1到N个位置进行判断,时间复杂度为:O(N^3)
第一次放第一个格子,,然后去判断N^2-1个格子可不可以放置
第二次放在第二个格子,然后去判断剩下N^2-2个格子可不可以放置
时间复杂度应该为O(N^3)
②以行为单位,去看每一行的棋子应该怎么放:每一行落子后就考虑下一行,然后当我们行数来到n行的时候,就得到一个合理的结果了
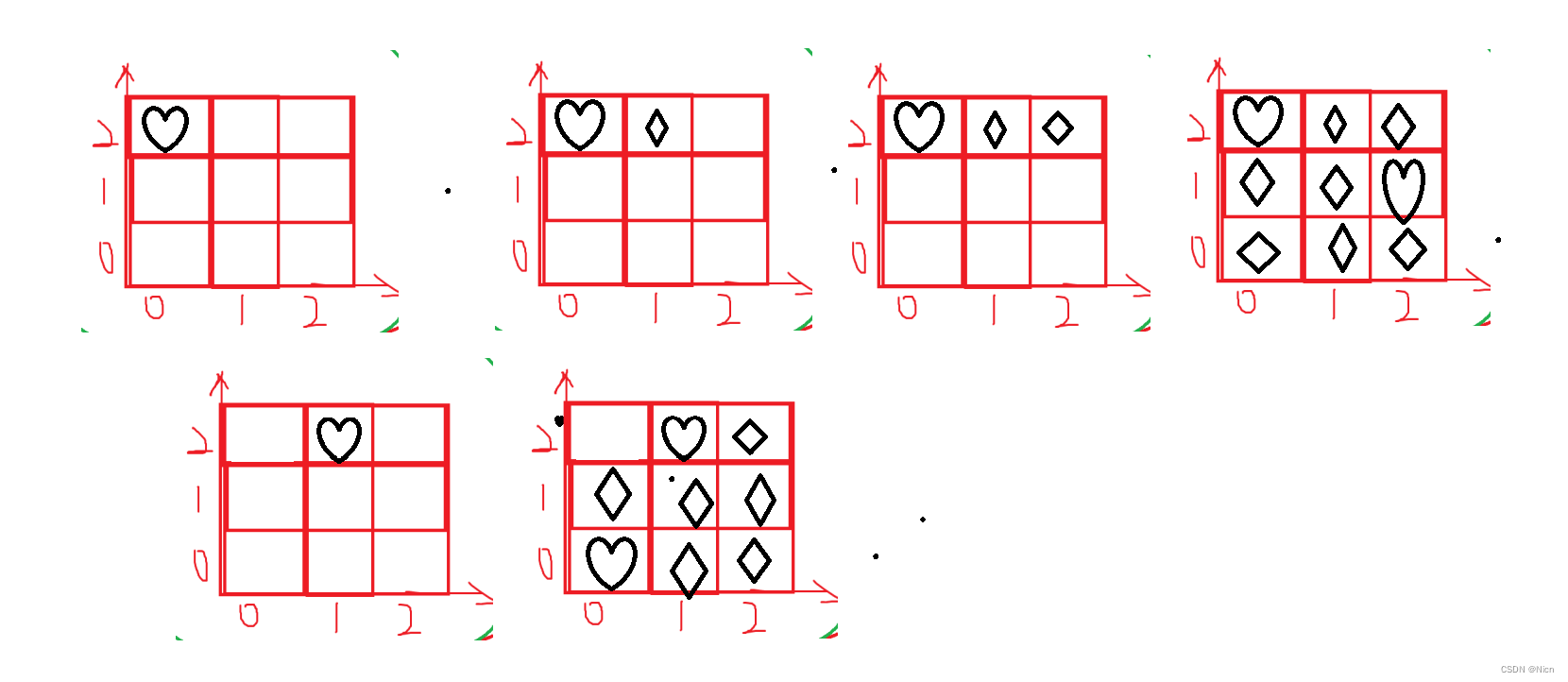
4皇后的放置方式
首先我们先在第一行进行落子:共有四种放置方式
接下来我们考虑往第二行的落子:
第二行依然是四种情况,但是对角线和同行同列排除不放:

接下来我们考虑第三行落子:
接下来我们考虑第4行落子:
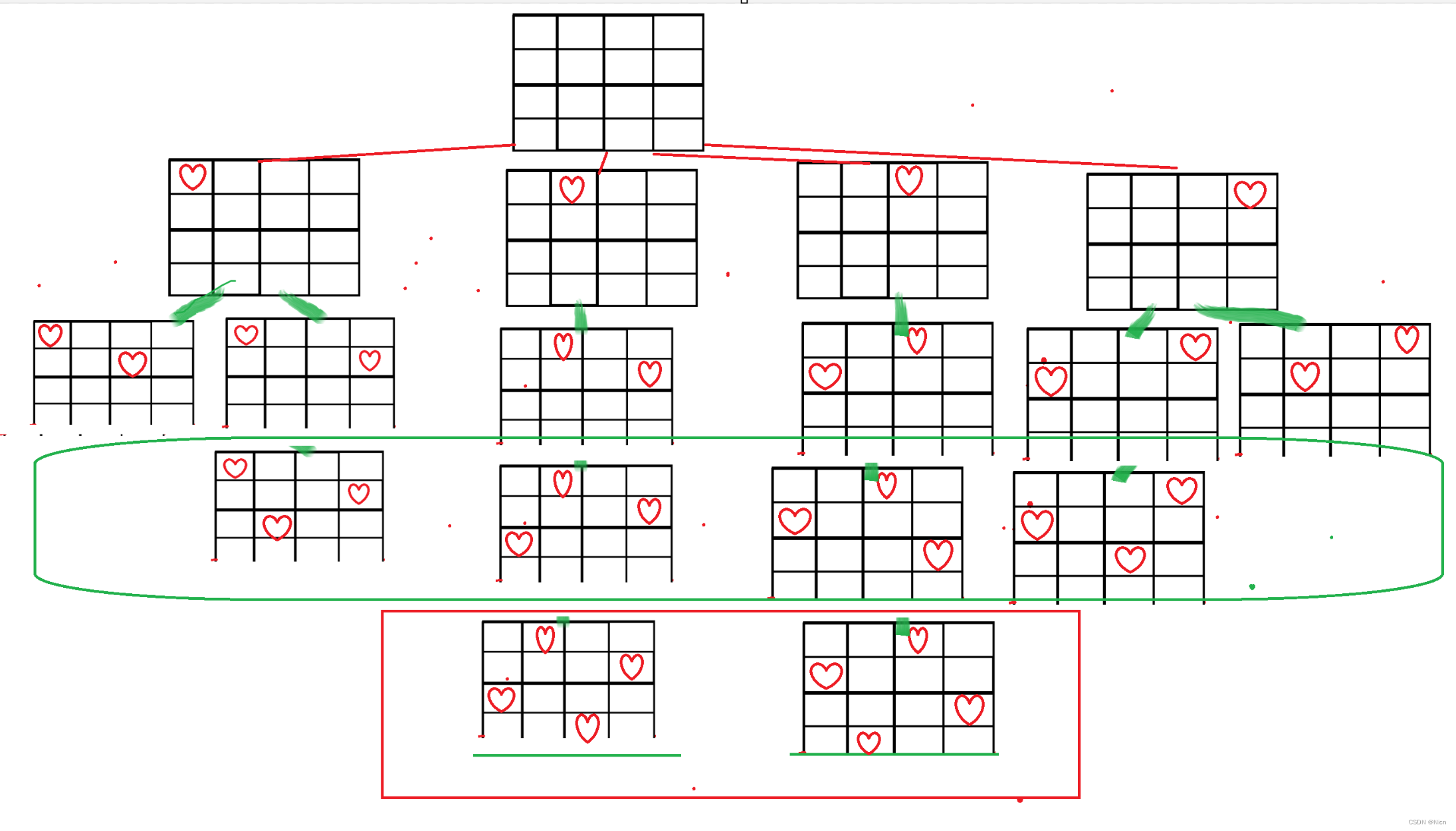
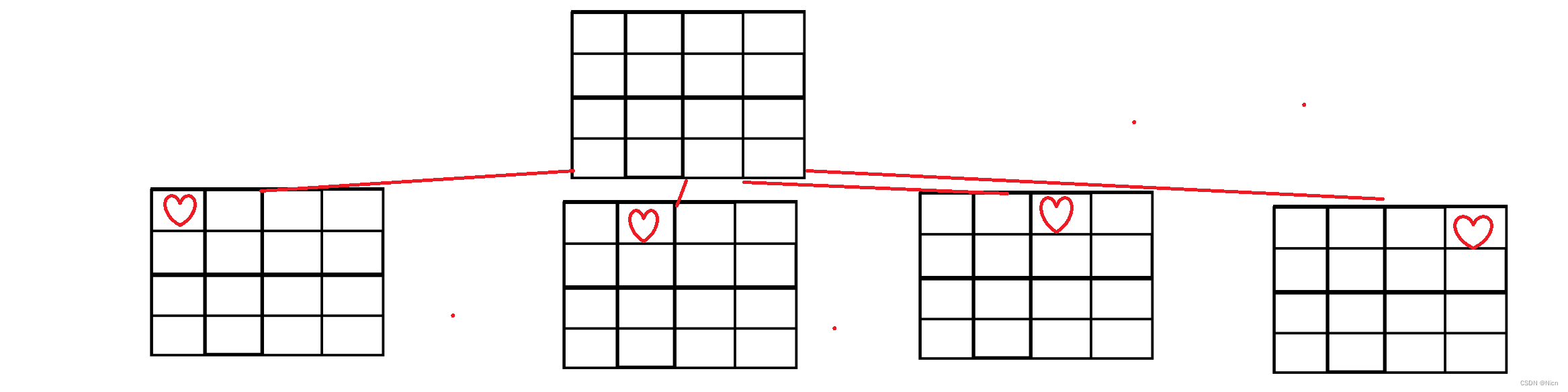
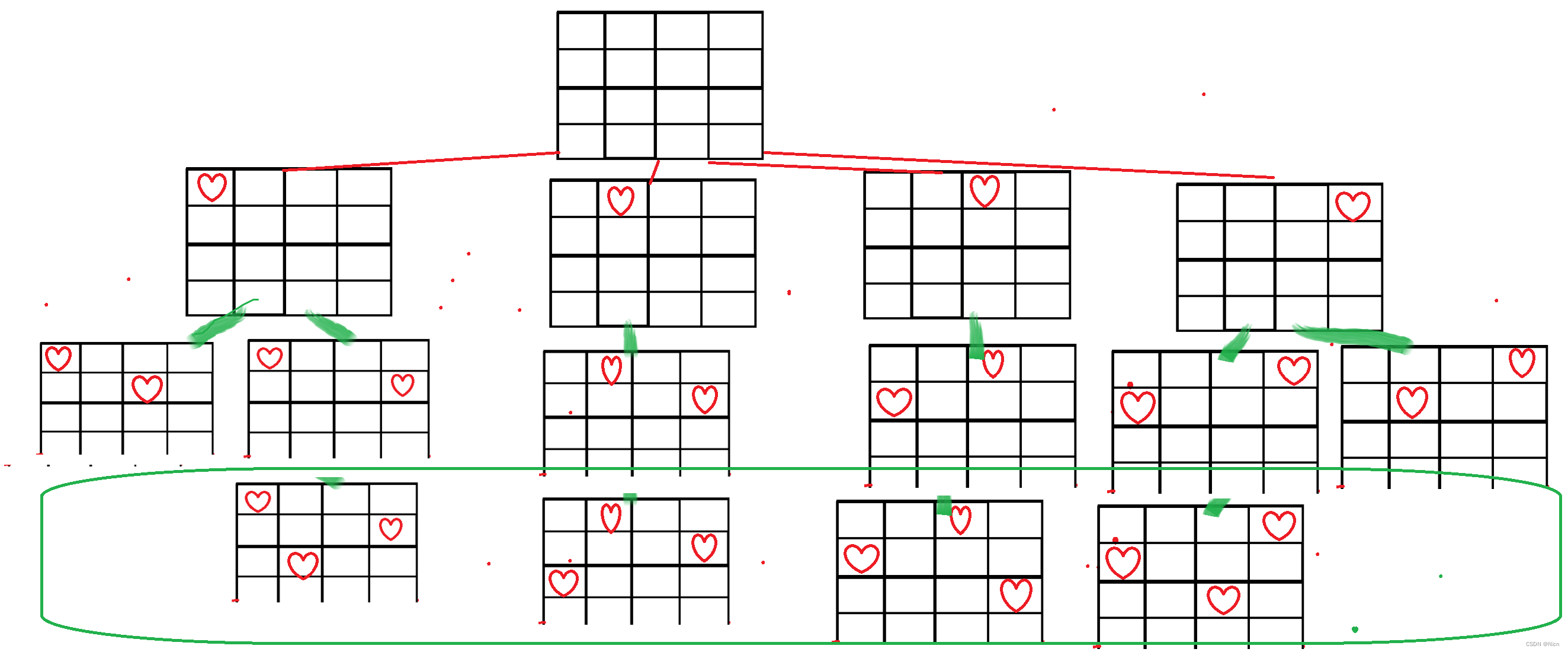
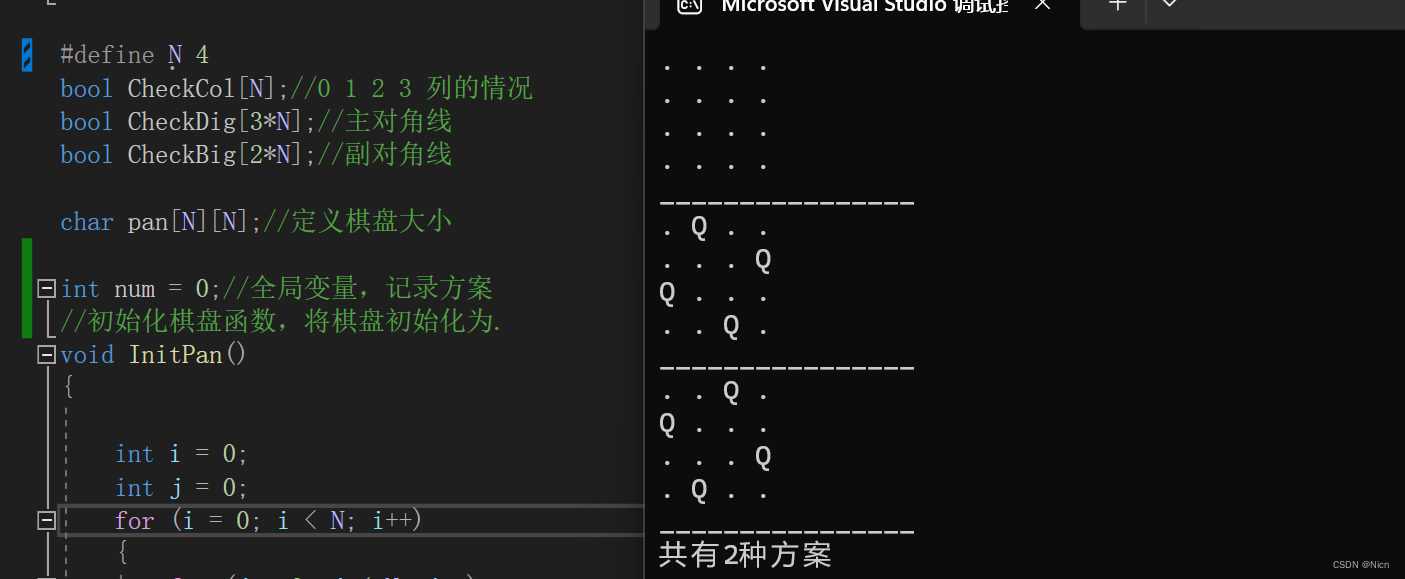
按照这样的方法就可以得到结果,我们的4皇后的结果是以上两种方法。最后得到的这个树状图就是经过剪枝的效果。
代码实现:
首先创建一个N*N的棋盘,然后在每一行试着放上一个皇后,判断是否可以放;
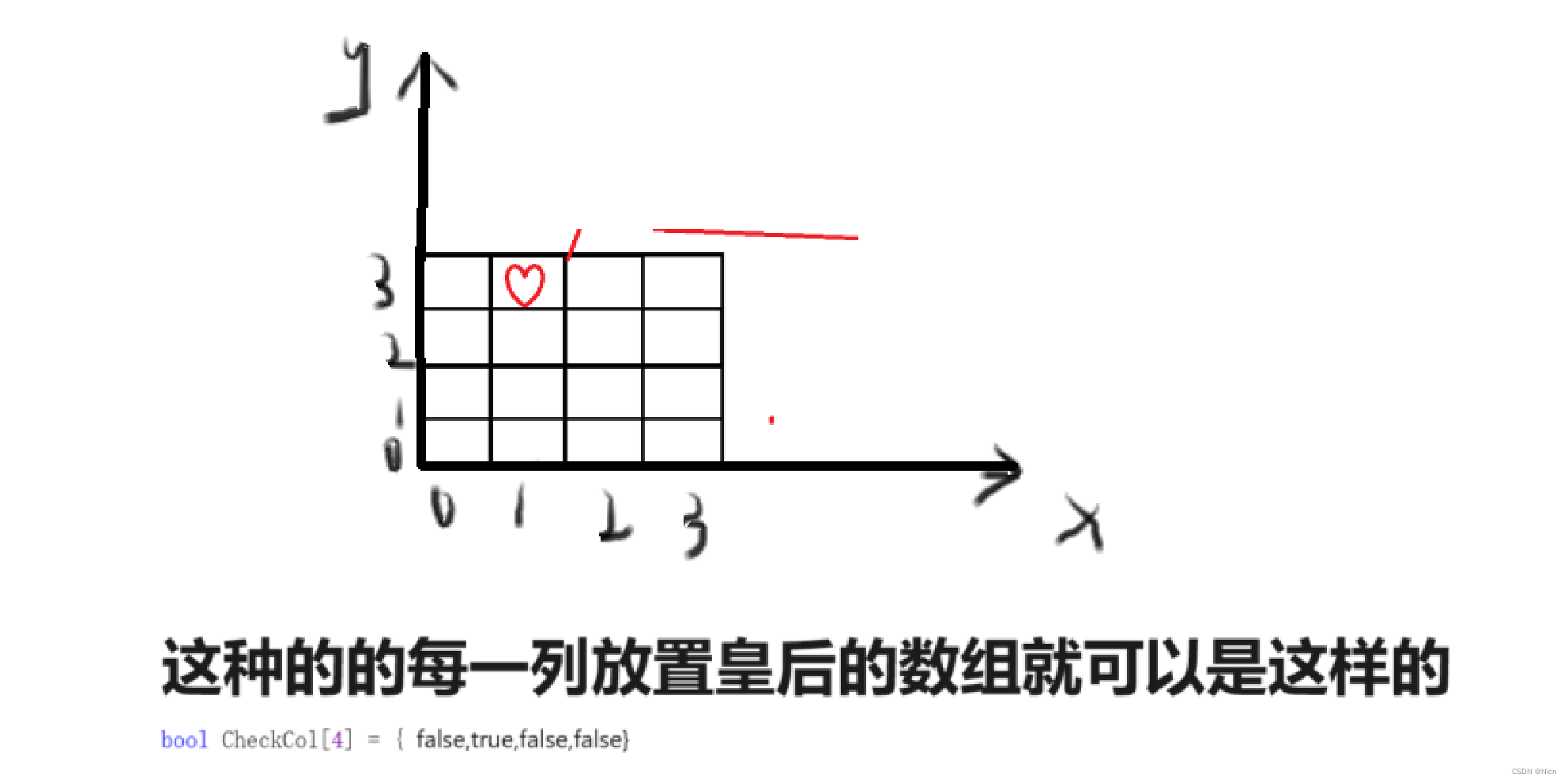
①对同列分析
首先检查该位置所在的列有没有皇后。这里我们这样用一个bool类型的数组来保存每一列的情况,某一列上有皇后,我们就保存为true,没有就保存folse:由于放置皇后位置这一列的的列数是一样的

那么通过列数作为数组下标,访问这个数组的值,就可以知道这一行有没有元素。
②对于对角线的位置:
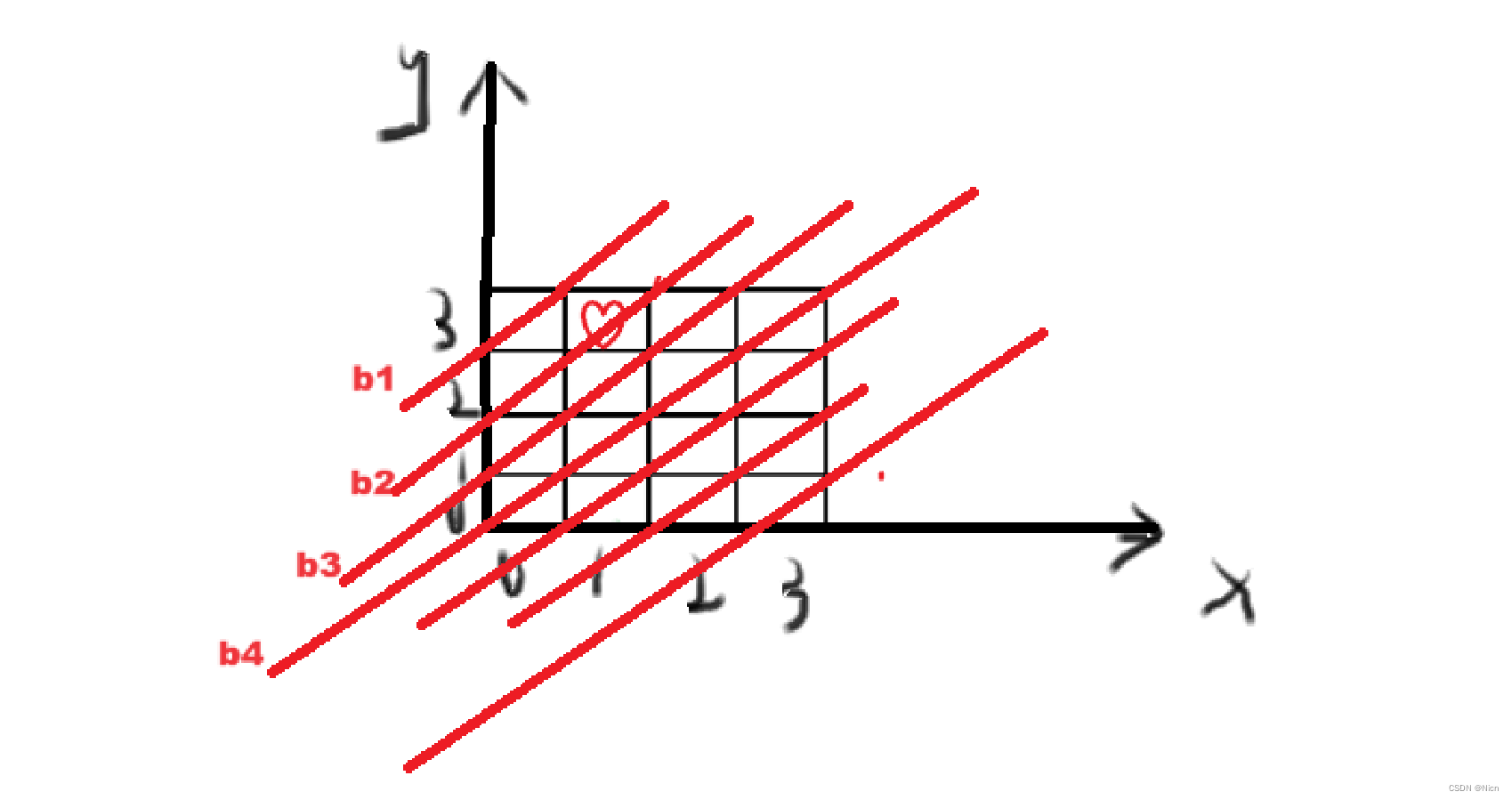
主对角线:
处于同一条对角线的格子,都在一条直线上:y = X+b
也就是说,处于一条对角线上的格子都满足:y-x = b,
那么我们就可以像列一样将对角线的情况用一个数组存储起来,然后当放置皇后的时候,用该点的横纵坐标来计算出当前在那条对角线上,然后通过数组就可以知道这条对角线上有没有皇后。
但是由于数组的下标不能出现负数,所以这里计算的时候,可以将等式两边同时加上n,x相当于将棋盘向上平移n.
y-x+n = b+n
副对角线:

代码实现:
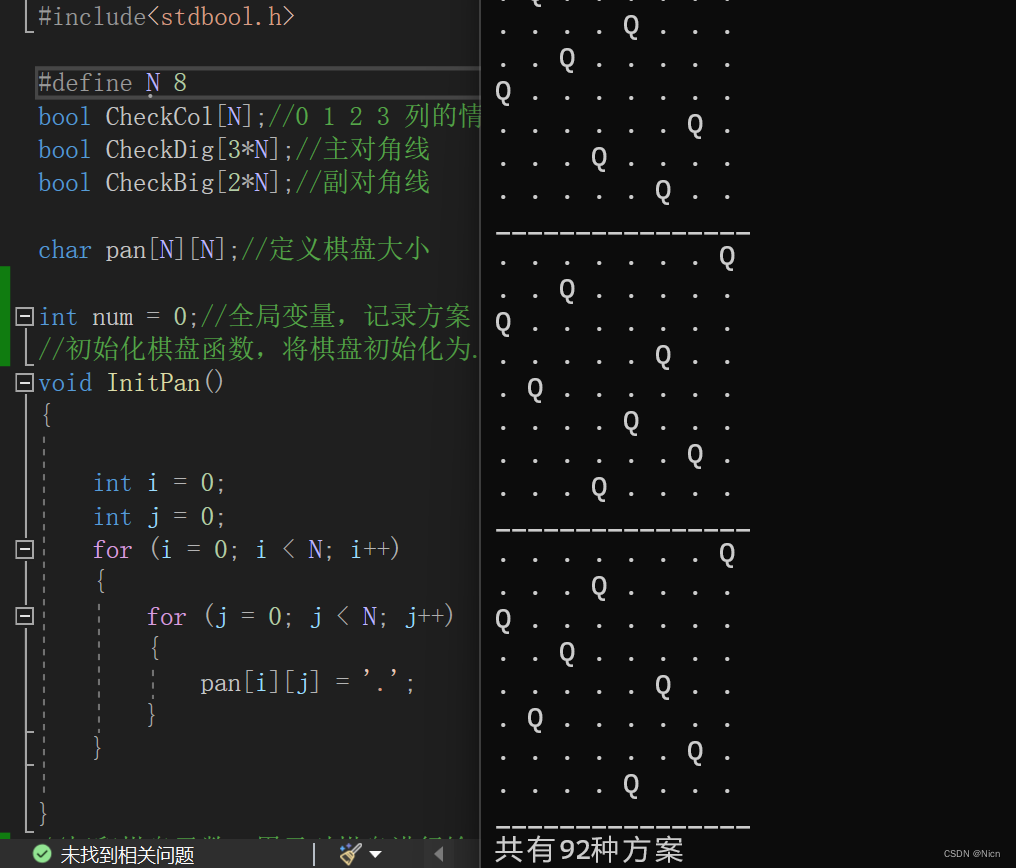
#include<stdio.h>
#include<stdbool.h>#define N 4//定义宏,控制皇后数量
bool CheckCol[N];//0 1 2 3 列的情况
bool CheckDig[3*N];//主对角线
bool CheckBig[2*N];//副对角线char pan[N][N];//定义棋盘大小int num = 0;//全局变量,记录方案
//初始化棋盘函数,将棋盘初始化为.
void InitPan()
{int i = 0;int j = 0;for (i = 0; i < N; i++){for (j = 0; j < N; j++){pan[i][j] = '.';}}}
//打印棋盘函数,用于对棋盘进行输出
void PrintPan()
{int i = 0;int j = 0;for (i = 0; i < N; i++){for (j = 0; j < N; j++){printf("%c ", pan[i][j]);}printf("\n");}}void dfs(int row)
{if (row == N){num++;PrintPan();printf("________________\n");return;}for (int col = 0; col < N; col++){if (!CheckCol[col] && !CheckDig[row - col + N] && !CheckBig[row + col])//剪枝{pan[row][col] = 'Q';CheckCol[col] = CheckDig[row - col + N] = CheckBig[row + col] = true;dfs(row + 1);//恢复现场,回退到了上一行pan[row][col] = '.';CheckCol[col] = CheckDig[row - col + N] = CheckBig[row + col] = false;}}
}int main()
{InitPan();//初始化一下棋盘PrintPan();printf("________________\n");dfs(0);printf("共有%d种方案\n",num);return 0;
}
递归展开图
时间复杂度
时间复杂度是一个稳健的保守预期,就是一般只关注最坏的情况,算法复杂度和算法调用中执行的基本语句的次数成正比。
最坏的情况:第一行有N中方法,第一行的每一种方法都匹配第2行的n-1中方法
第二行:至多N-1中放法
第三行:至多N-2中放法:
第N行:至多1中方法
时间复杂度为:N*N-1*n-2......*1
时间复杂度为O(N!)
空间复杂度
对算法使用的一个额外空间进行估算。
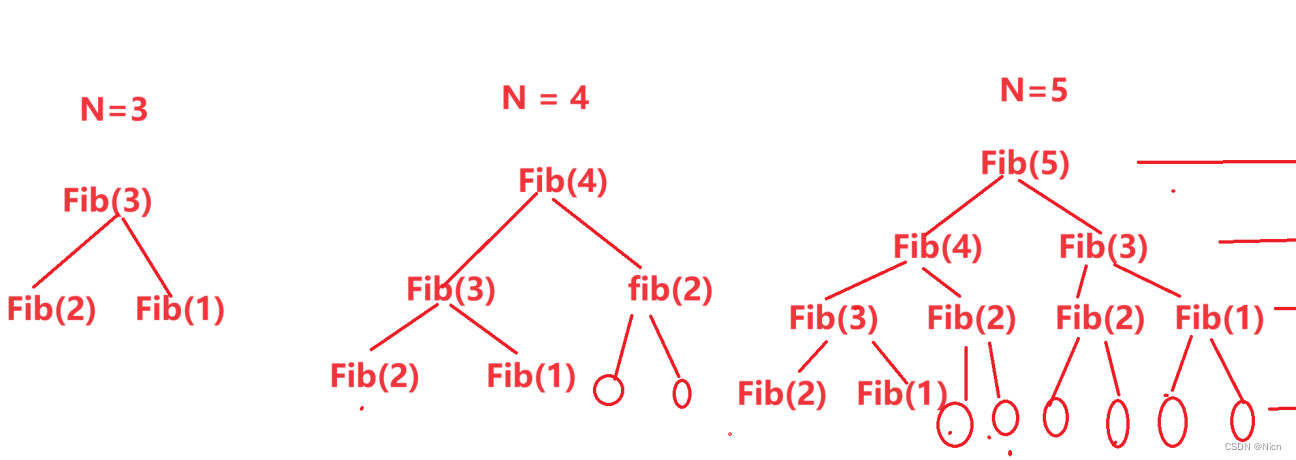
引入斐波那契数列的递归计算进行讲解:
重点:计算时间复杂度的时候时间是可以累加的,但是空间却是可以重复利用的
先上代码:
// 计算斐波那契递归Fib的时间复杂度? long long Fib(size_t N) {if(N < 3)return 1;return Fib(N-1) + Fib(N-2); }我们在计算其时间复杂度的时候我们这样来理解这个算法的调用的:
在这个时候我们理解的是:递归调用函数是一起调用的,但是在真正的递归在内存中跑起来却不是这样调用的:
我们以Fib(4)举例讲解:
然后后面的调用都是使用这片空间,我们如果在程序中调试去看,我们的N的值应该会这样变化:4-3-2-1-3-4-2-4:
那么当我们有n个递归:
是不是只会总的开辟N个空间从N到1,那么空间复杂度就为O(N)

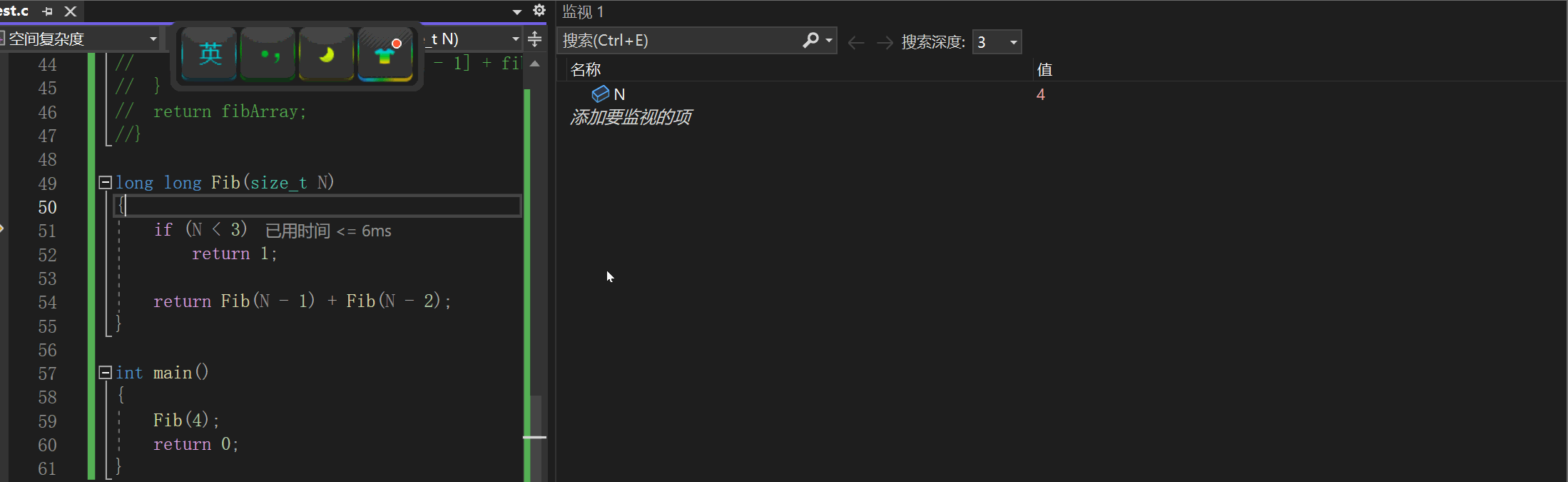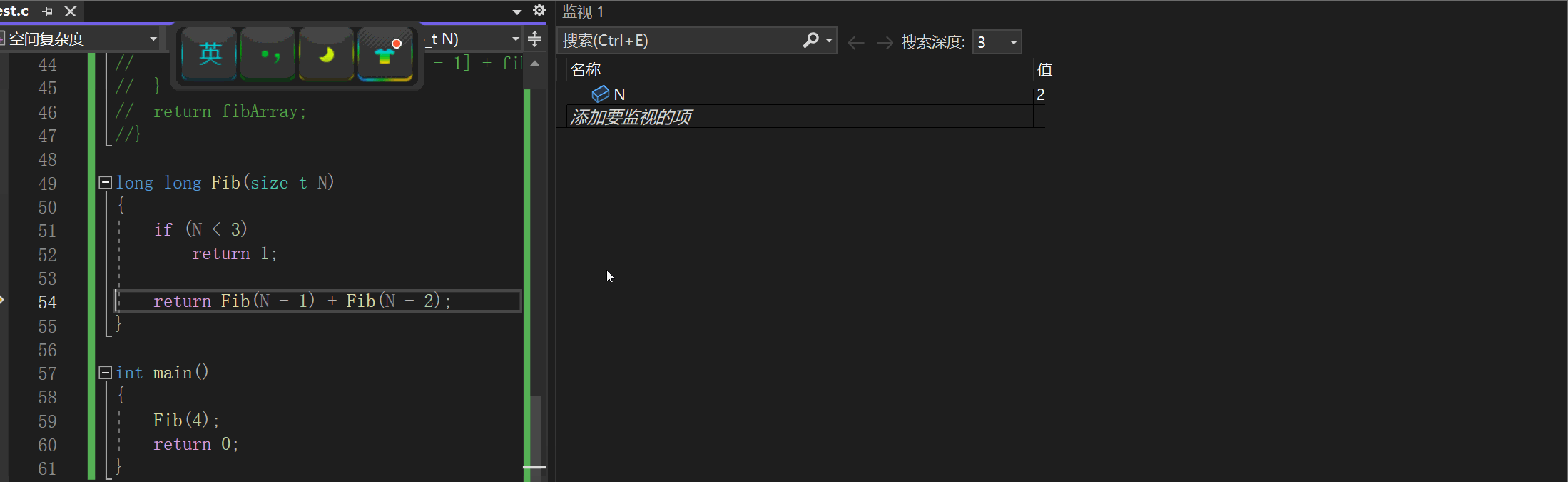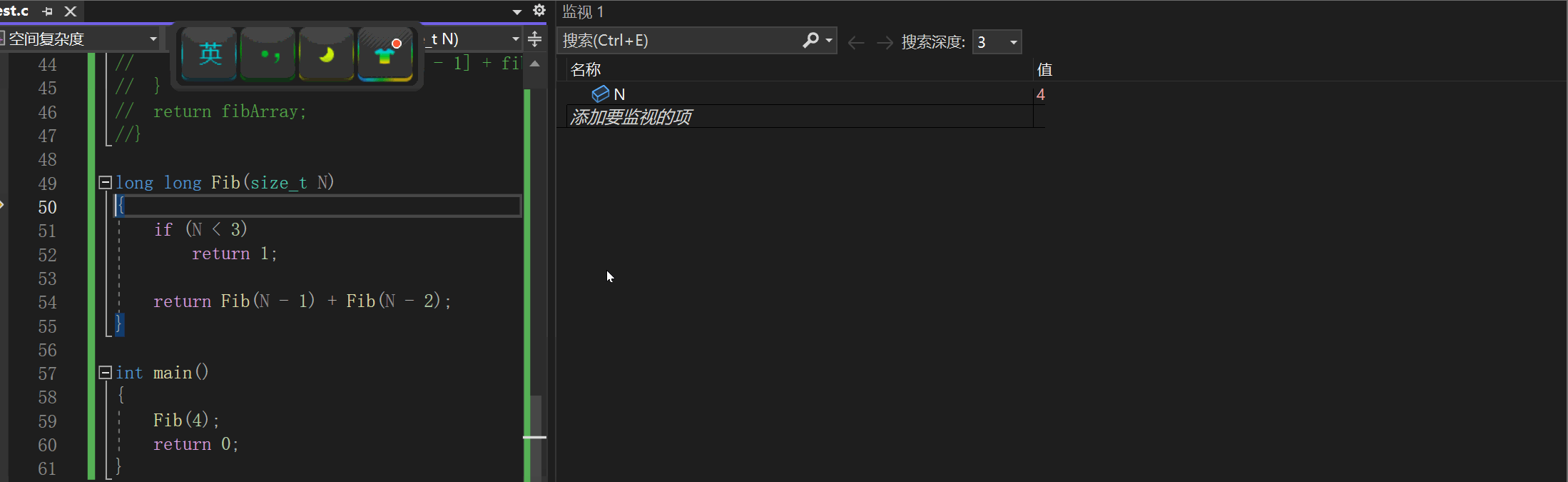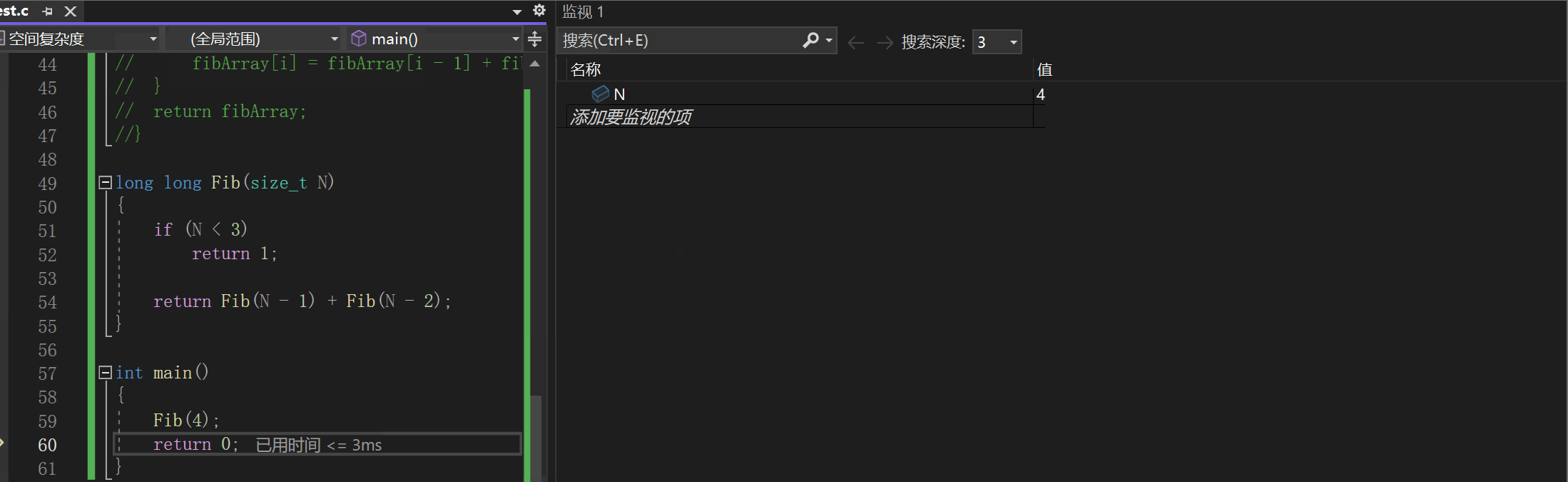

时间一去不复返,空间可以重复再利用。函数最多递归n次,也就是开辟n次栈帧空间,
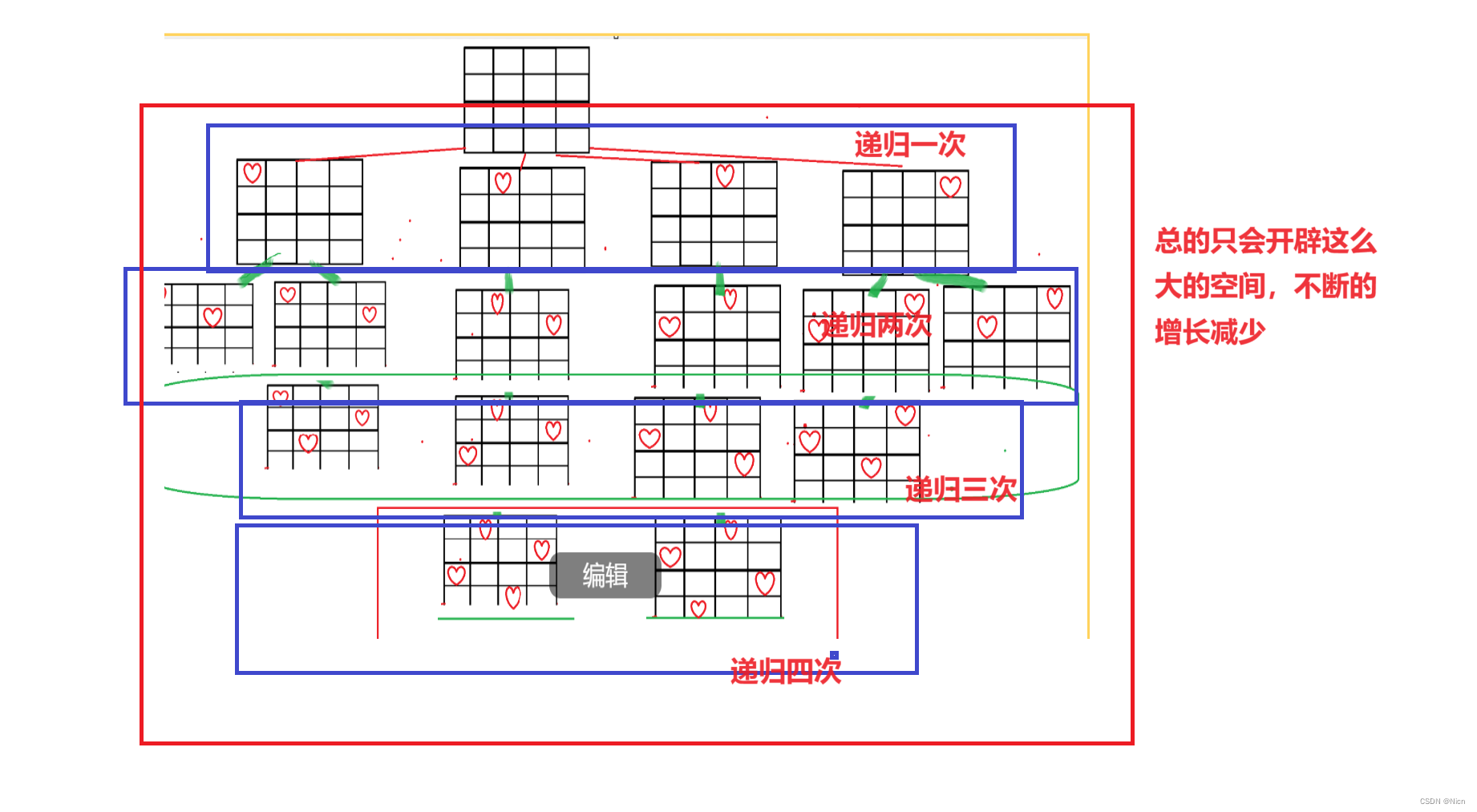
所以时间复杂度为O(N)
6.总结
本文先带大家了解什么是回溯:走不通回头,然后给出了第一个回溯算法的定义,然后给大家区分了递归和深度搜素和回溯的区别,然后引出了对回溯的剪枝和恢复现场的讲解,接着通过二叉树路径这道简单题目让大家对以上概念得到运用和更深入理解,最后使用递归解决了n皇后的问题,分析了时间复杂度和空间复杂度。创作不易,希望大家多多指教,如果觉得今天讲解的有学到东西,可以留下一个三连,持续关注后续的文章。

![[管理者与领导者-163] :团队管理 - 高效执行力 -1- 高效沟通的架构、关键问题、注意事项](https://img-blog.csdnimg.cn/direct/364a6da3aa4e4fe2affb311e89c33c71.png)