1.摘要
本文主要研究内容是开发一种发型推荐系统,旨在识别用户的面部形状,并根据此形状推荐最适合的发型。首先,收集具有各种面部形状的用户照片,并标记它们的脸型,如长形、圆形、椭圆形、心形或方形。接着构建一个面部分类器,以确定用户的脸型,如长形、圆形、椭圆形、心形或方形。然后,使用机器学习或深度学习技术构建一个面部分类器模型。该模型接受用户照片作为输入,并输出对应的面部形状分类结果。基于分类结果,根据面部分类器的输出结果,为每种面部形状设计一组适合的发型。最终实现的系统将推荐适合用户面部形状的发型。该系统将利用用户对不同发型的偏好和不喜欢程度进行持续更新,以提供个性化的推荐。
2. 算法研究
2.1 数据分析及数据集收集过程:
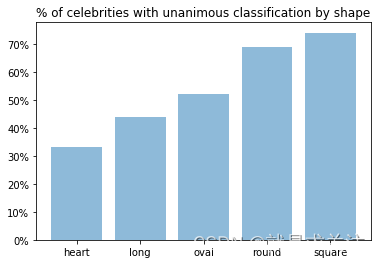
通过查阅22个网站和234位名人的信息来收集具有正确面部形状标签的图像。其中,有33位名人的面部形状在3个或更多网站中得到了一致的分类(65位在2个或更多网站中一致)。还有49位名人虽然在某些网站上的分类存在冲突,但有强烈的共识可以用于分类。最终,利用74位名人的数据进行了分析。
面部形状特征描述:
- 心形脸形(heart-shaped face):具有宽阔的颧骨,逐渐变窄至下巴。
- 长形脸形(long face):长而非常狭窄。
- 椭圆形脸形(oval face):类似于长形脸,但比长形脸更丰满。
- 圆形脸形(round face):短而宽的形状,与其他脸形明显不同。
- 方形脸形(square-shaped face):具有强烈的下颌线。
最终,数据集包含了约 74 名名人的约 1500 张图像,存储到DATA 文件夹中。
基于上述收集的data数据,创建了一个包含各种特征的数据框,这些特征包括面部关键点的坐标、计算出的长度和比率,以及图像名称和分类形状。该数据框的列包括了大量的特征,如面部关键点坐标、长度、比率以及图像名称和分类形状等。接着,通过调用主要函数和第二个用于推荐目的的函数,对上述目录中的所有照片运行主要函数,从而生成了一个整洁的数据集。
data = pd.DataFrame()
data.reset_index
shape_df = pd.DataFrame(columns = ['filenum','filename','classified_shape'])
shape_array = []
def store_features_and_classification():filenum = -1sub_dir = [q for q in pathlib.Path(image_dir).iterdir() if q.is_dir()]start_j = 0end_j = len(sub_dir)for j in range(start_j, end_j):images_dir = [p for p in pathlib.Path(sub_dir[j]).iterdir() if p.is_file()]for p in pathlib.Path(sub_dir[j]).iterdir():print(p)shape_array= []if 1 == 1:face_file_name = os.path.basename(p)classified_face_shape = os.path.basename(os.path.dirname(p)) filenum += 1make_face_df(p,filenum)shape_array.append(filenum)shape_array.append(face_file_name) shape_array.append(classified_face_shape)shape_df.loc[filenum] = np.array(shape_array)store_features_and_classification()
data = pd.concat([df, shape_df], axis=1)
# Add all the faces features with shape to a DATA CSV file for model purpose.
data.to_csv('all_features.csv')这段代码的主要目的是创建一个数据集,其中包含了面部特征和分类形状的信息,并将其保存到一个CSV文件中以供模型使用。
2.2 模型训练过程
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, normalize
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt# 导入数据
data = pd.read_csv('all_features.csv', index_col=None).drop('Unnamed: 0', axis=1).dropna()# 准备数据
X = normalize(data.drop(['filenum', 'filename', 'classified_shape'], axis=1))
Y = data['classified_shape']# 标准化特征
scaler = StandardScaler()
X = scaler.fit_transform(X)# PCA降维
pca = PCA(n_components=18, svd_solver='randomized', whiten=True).fit(X)
X = pca.transform(X)# 划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=1200)# MLP模型
mlp_best = MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', hidden_layer_sizes=(60, 100, 30, 100),learning_rate='constant', learning_rate_init=0.01, max_iter=100, random_state=525)
mlp_best.fit(X_train, Y_train)# KNN模型
neigh = KNeighborsClassifier(n_neighbors=5)
neigh.fit(X_train, Y_train)# 随机森林模型
clf = RandomForestClassifier(n_estimators=100, max_depth=None, random_state=5)
clf.fit(X_train, Y_train)# 梯度提升模型
gb_best = GradientBoostingClassifier(n_estimators=300, max_depth=5, learning_rate=0.1)
gb_best.fit(X_train, Y_train)# LDA模型
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, Y_train)# 可视化模型比较结果
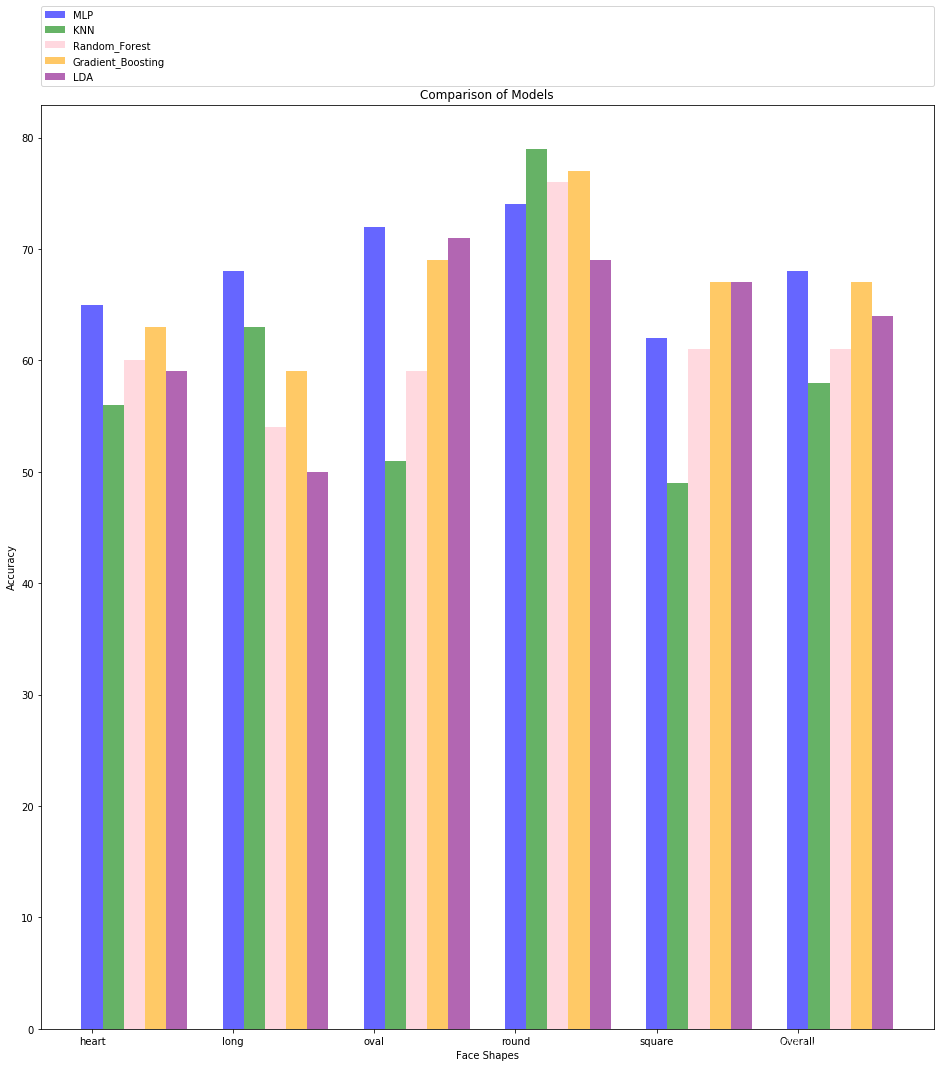
def model_graph():models = [mlp_best, neigh, clf, gb_best, lda]model_names = ['MLP', 'KNN', 'Random Forest', 'Gradient Boosting', 'LDA']accuracies = [model.score(X_test, Y_test) for model in models]plt.figure(figsize=(10, 6))plt.bar(model_names, accuracies, color=['blue', 'green', 'pink', 'orange', 'purple'])plt.xlabel('Model')plt.ylabel('Accuracy')plt.title('Comparison of Models')plt.show()model_graph()
该代码的主要目的为比较不同机器学习模型在识别面部形状方面的性能,以帮助选择最佳的模型用于面部形状分类任务。功能如下:
-
数据预处理:首先,导入必要的库,并加载以前处理过的数据。然后,将数据进行清理,去除任何包含NaN值的行,并准备好用于模型训练的特征矩阵 X 和目标向量 Y。
-
标准化:使用
StandardScaler对特征矩阵 X 进行标准化,即移除平均值并缩放到单位方差,以确保每个特征对模型的贡献大致相等。 -
PCA降维:对标准化后的特征矩阵 X 进行主成分分析(PCA)降维,以减少特征的数量。作者选择了包含 18 个主成分的 PCA 模型,通过
fit方法拟合 PCA 模型,并使用transform方法将数据转换为新的主成分空间。 -
模型选择与训练:作者尝试了多种监督学习模型,包括多层感知机(MLP)、K最近邻分类器(KNN)、随机森林分类器(Random Forest)、梯度提升分类器(Gradient Boosting)和线性判别分析(LDA)。对于每个模型,作者通过调整超参数和使用交叉验证选择最佳模型,并使用最佳模型在测试集上进行评估。
-
模型评估:评估了每个模型在测试集上的性能,并将结果可视化为条形图,展示了不同模型在识别不同面部形状上的准确率。最后,生成一个结果表格,汇总了每个模型对不同面部形状的识别准确率。实验结果如下:
3. 应用实现
基于flask技术实现一个用于面部特征识别和发型推荐的应用程序。
该系统包含:
-
上传照片功能:用户可以在页面中上传自己的照片。上传后,会显示用户的照片,并提供预测和推荐功能。
-
预测功能:用户可以点击“预测”按钮,对上传的照片进行预测,以推荐适合用户脸型和其他特征的发型。
点击开始预测

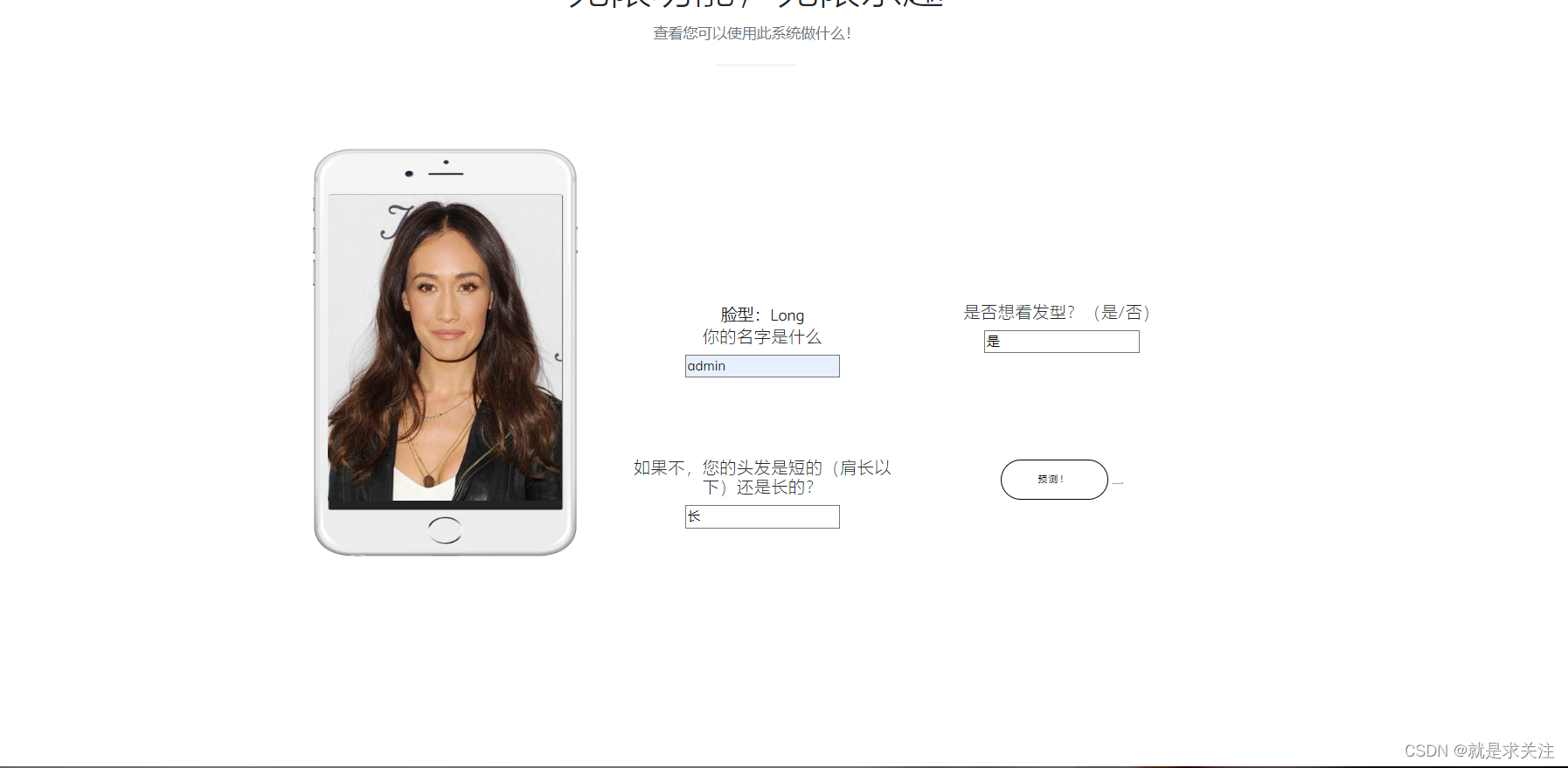
输出结果为:

4. 结语
该研究主要关注开发一种发型推荐系统,其目标是根据用户的面部形状识别最适合的发型。主要研究内容包括:
1.数据收集和分析:收集具有各种面部形状的用户照片,并标记其脸型,如长形、圆形、椭圆形、心形或方形。构建面部分类器以确定用户的脸型,使用机器学习技术构建模型。数据集包含约74位名人的约1500张图像,并存储到CSV文件中以供模型使用。
2.模型训练过程:导入数据,准备数据,并对特征进行标准化和降维。使用多种机器学习模型进行训练,包括MLP、KNN、随机森林、梯度提升和LDA模型。比较不同模型在面部形状分类任务上的性能,并选择最佳模型。
3.应用实现:基于Flask技术实现一个用于面部特征识别和发型推荐的应用程序。应用程序包括一个点击开始预测的功能,输出用户的面部形状分类结果和推荐的发型。
总的来说,该研究旨在帮助用户了解适合其脸型的最佳发型,并提供个性化的发型推荐服务。
上述代码的运行环境为基于python3.7.0配置pandas==1.1.5 Flask==1.0.2 sklearn==0.0 scikit-learn==0.23.1 Werkzeug==0.16.0 opencv-python==4.1.0.25 numpy==1.19.5 matplotlib==3.3.4 Pillow==8.4.0 requests==2.18.4 bs4==0.0.1 beautifulsoup4==4.7.1 seaborn==0.11.0 scipy==1.5.4。
完整代码:
https://download.csdn.net/download/weixin_40651515/89136480