目录
1,连接数据库
2,连接池
1.何为连接池?
2.连接池运行原理。
3.如何查看连接池?
4.连接池注意事项。
3,一般SQL语句。
4,控制语句
1.判断语句
2.循环语句
5,视图
1.使用MSSM创建视图:
2.使用SQL脚本创建
3.调用视图。
4.视图注意事项。
6,事务
7,临时表
8,存储过程
9,类型转换
10,表格
11,账号管理
1,连接数据库
- 普通连接字符串:
<connectionStrings><add name="constr" connectionString="server=.;database=SMDB;uid=sa;pwd=1”/></connectionStrings>- 启用连接池的连接字符串:
<connectionStrings><add name="constr" connectionString="server=.;database=SMDB;uid=sa;pwd=1;Pooling=true;Max pool size=10;Min Pool size=5"/></connectionStrings> --Pooling =true :表示启用连接池
--Max Pool Size=10:表示连接池中最大允许的连接数量
--Min Pool Size=5;表示连接池中最小的连接数量
当第一次访问时即建立5个连接,以后根据需要自动增加连接数量,但最多不超过规定的10个连接,如果超过10个并发请求时,在连接池之外建立连接对象,在连接池以外建立的连接关闭后会释放连接。
2,连接池
1.何为连接池?
连接池是DataProvider提供的一个机制,使得应用程序的链接保存在连接池中,从而避免每次都要完成建立/关闭物理连接的整个过程。
2.连接池运行原理。
当使用连接池以后,执行Open()方法的时候,系统从连接池中提取一个现有的连接对象,这时打开的是一个逻辑连接如果连接池中的连接对象都被占用了,则会创建一个新的物理连接对象。当使用Close()方法关闭连接池时,系统把连接对象放回到连接池中,这时关闭的是一个逻辑连接。如果是独立创建的对象则会被GC释放。
3.如何查看连接池?
调用存储过程:exec sp_who可以查看当前数据库连接详情
exec sp_who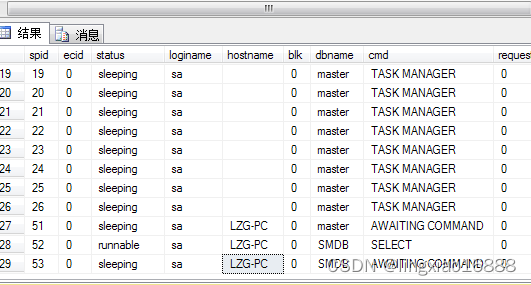
4.连接池注意事项。
在winform中,连接字符串必须一致,这样不同应用程序可以共享数据库中的连接池的连接对象,如果应用程序的连接字符串不同,则数据库会给每个连接创建一个连接池,一定要避免这种情况。
在web应用程序中,因为连接字符串只在服务端,所以不会出现以上情况。
3,一般SQL语句。
--将结果以xml格式显示
select * from StudentInfo where Sid<30 for xml raw ('Student')--清空表格
truncate table students--查询表格
select * from tempStudent--查询前3行
select top 3 * from tb_UserInfo--查询前20%
select top 20 percent * from tb_UserInfo--模糊查询
select * from tb_UserInfo where Phone like '%张三%'
select * from tb_UserInfo where Phone like '%[2,7]'--右外连接查询
select * from tb_Course as a
right outer join tb_Category as b
on a.CateId=b.Id--查询重复
select * from tb_UserInfo where Nick in(select Nick from tb_UserInfo group by Nick having COUNT(*)>1)order by Nick--查询空值列
select * from tb_userinfo where LogonDate is null--批量插入数据
insert into tempStudent (Sname,Sphone,Sbirthday,Semail)
select Sname,Sphone,Sbirthday,Semail from tempStudent--向查询结果中插入常量
select *,'OK' 结果 from tb_UserInfo--删除指定的几个数据
delete from StudentInfoCopy where Sid in (10,11,14)--多列排序
select * from tb_UserInfo order by Name,Phone desc--同时执行多个sql语句时使用;进行分割insert into tb_UserInfo values('lisi4','李四',123,'122222222',0,null);insert into tb_UserInfo values('lisi5','李四',123,'122222222',0,null);insert into tb_UserInfo values('lisi6','李四',123,'122222222',0,null)--通过全局变量@@IDENTITY返回插入行生成的标识列值insert into tb_UserInfo values('lisi7','李四',123,'122222222',0,null);select @@IDENTITY--In 与 Not In使用
select StudentId,StudentName from Students where StudentId in (select StudentId from ScoreList where SQLServerDB>60)--使用 NotIn反向查询
select StudentId,StudentName from Students where StudentId not in (select StudentId from ScoreList where SQLServerDB>60)--Exists使用:Exists(表达式),表达式中结果个数大于0即为true ,否则为falseif (exists(select * from ScoreList where SQLServerDB<60))print '存在未及格同学'elseprint '全部合格'--Exists反向查询 :Not Existsif(not exists(select * from ScoreList where SQLServerDB<60))print '全部合格'elseprint '存在未及格同学'4,控制语句
1.判断语句
declare @len intset @len=4if(@len%2=1)beginprint '奇数'endelsebeginprint '偶数'enduse SMDB
go--case条件语句应用select StudentId,SQLServerDB,
'评价'=case
when SQLServerDB>=90 then '优秀'
when SQLServerDB between 80 and 89 then '良好'
when SQLServerDB between 60 and 79 then '合格'
else '不及格'
end
from ScoreList2.循环语句
use SMDB
go
declare @StudentId int,@count int
set @StudentId=0
while(1=1)beginset @count=(select COUNT(*) from ScoreList where CSharp<60)if(@count=0)breakselect @StudentId=(select top 1 studentid from ScoreList where CSharp<60)update ScoreList set CSharp=60 where StudentId=@StudentId
end5,视图
1.使用MSSM创建视图:
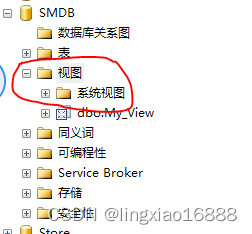
- 选择视图选项,右击选择新建视图
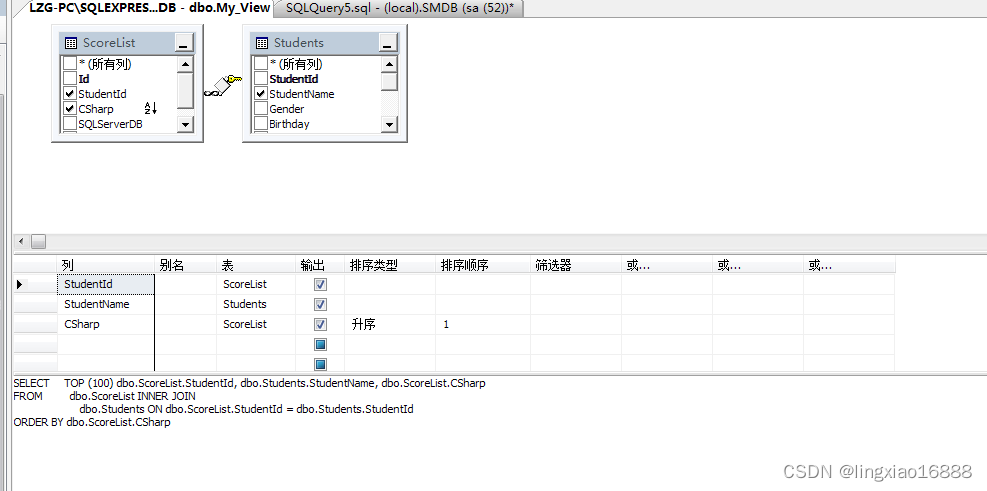
- 勾选需要查询的字段后保存。
2.使用SQL脚本创建
--使用脚本创建视图if(exists(select * from sysobjects where name='My_View'))drop view My_Viewgocreate view My_Viewasselect top 100 ScoreList.StudentId,StudentName,CSharp from ScoreList join Studentson ScoreList.StudentId=Students.StudentId order by CSharpgo
3.调用视图。
--以查询表格的方式直接调用视图select * from My_View4.视图注意事项。
- 视图保存于服务端,仅用于查询,不能用于增删改。
- 视图中可以使用多张表
- 一个视图可以嵌套另一个视图(尽量少套用)
- 视图中的select语句不能使用以下内容
- OrderBy子句,除非在Select 语句的选择列表中也有一个top子句
- into关键字
- 引用临时变量和表变量
6,事务
--transaction事务使用--定义一个变量承接执行sql语句时可能产生的异常(通过@@Error获取实时异常代码)declare @errorSum int =0--开始事务begin tranbegindelete from Students where StudentId=100094--获取执行语句可能产生的异常代码值set @errorSum=@errorSum+@@ERRORdelete from StudentClass where ClassId=1set @errorSum=@errorSum+@@ERRORif(@errorSum>0)begin--出现异常,进行回滚rollback tranendelse--无异常,提交事务commit tranend go7,临时表
--临时表:位于系统数据库->tempdb->临时表
--临时表,在语句调用完毕后自动删除,在管理器端使用脚本生成的临时表,重启管理软件自动删除
--使用into #临时表名,将结果插入到临时表中select StudentId,StudentName into #mylist from Students
--查询临时表select * from #mylist--手动删除临时表drop table #mylist8,存储过程
--定义存储过程语法
--系统存储过程以sp_开头,扩张存储过程以xp_开头
CREATE PROC[EDURE] 存储过程名@参数1 数据类型=默认值 ,@参数2 数据类型=默认值 OUTPUT.......
ASSQL 语句
GO带默认值得参数使用
以存储过程名为usp_MyProc为例--带有默认参数的存储过程if(exists(select * from sysobjects where name='usp_MyProc'))drop proc usp_MyProcgocreate proc usp_MyProc--带有默认值的参数格式为 变量名 类型=默认值@Id int=100000,@name varchar(20)=''asselect * from ScoreList where StudentId=@Idselect * from Students where StudentName=@namego--调用带有默认值得存储过程--方式1 exec usp_MyProc--方式2exec usp_MyProc 100001,'张三'--方式3exec usp_MyProc default,'张三'--方式4exec usp_MyProc @name='张三'--使用带有output声明的形参作为结果输出接口--分析学员成绩的存储过程if(exists(select * from sysobjects where name='usp_queryScore'))drop proc usp_queryScoregocreate proc usp_queryScore @className varchar(20),@total int output,@miss int output,@csharp float output,@db float outputas--判断@classname是否为空if(LEN(@className)=0)beginselect Students.StudentId,StudentName,Gender,ClassName,PhoneNumber,CSharp,SQLServerDB from ScoreListjoin Studentson ScoreList.StudentId=Students.StudentIdjoin StudentClasson StudentClass.ClassId=Students.ClassIdselect @total=COUNT(*),@csharp=SUM(CSharp)*1.0/COUNT(*),@db=AVG(SQLServerDB) from ScoreListselect @miss=COUNT(*) from Students where StudentId not in (select StudentId from ScoreList)--缺考人员列表select StudentName from Students where StudentId not in (select StudentId from ScoreList) endelsebegin--显示列表select Students.StudentId,StudentName,Gender,ClassName,PhoneNumber,CSharp,SQLServerDB from ScoreListjoin Studentson ScoreList.StudentId=Students.StudentIdjoin StudentClasson StudentClass.ClassId=Students.ClassIdwhere ClassName=@className--该班级总参加人数--declare @className varchar(20)='软件1班'select @total=COUNT(*),@csharp=SUM(CSharp)*1.0/COUNT(*),@db=AVG(SQLServerDB) from ScoreList join Studentson ScoreList.StudentId=Students.StudentIdinner join StudentClasson Students.ClassId=StudentClass.ClassIdwhere StudentClass.ClassName=@className--该班级未参加考试人员select @miss=COUNT(*) from Students where StudentId not in (select StudentId from ScoreList) and ClassId=(select top 1 ClassId from StudentClass where ClassName=@className)--该班级缺考人员列表select StudentName,ClassId from Students where StudentId not in (select StudentId from ScoreList) and ClassId=(select top 1 ClassId from StudentClass where ClassName=@className)endgo
declare @className varchar(20)='软件2班'
declare @total int
declare @miss int
declare @csharp float
declare @db float
exec usp_queryScore @className,@total output,@miss output,@csharp output,@db output
select 班级名= @className ,参考总人数= @total,缺考人数=@miss,Csharp平均分=@csharp,@db 数据库平均分C#端调用
/// <summary>/// 执行存储过程/// </summary>/// <param name="procName">存储过程名</param>/// <param name="paras">参数</param>/// <returns>返回的数据集</returns>public static DataSet ExecutProcedure(string procName,params SqlParameter[] paras){SqlConnection con = new SqlConnection(constr);DataSet set = new DataSet();try{using (SqlCommand com=new SqlCommand()){com.Connection = con;com.CommandText = procName;com.Parameters.AddRange(paras);//指定文本类型com.CommandType = CommandType.StoredProcedure;using (SqlDataAdapter sda=new SqlDataAdapter(com)){sda.Fill(set); }}}finally{con.Close();}return set;}public AnalyseResult GetScoreAnalyse(string className){AnalyseResult result = new AnalyseResult();//declare @className varchar(20)//declare @total int//declare @miss int//declare @csharp float//declare @db float//定义参数SqlParameter[] paras = new SqlParameter[]{new SqlParameter("@className",className) ,new SqlParameter("@total",SqlDbType.Int) { Direction = ParameterDirection.Output } ,new SqlParameter("@miss",SqlDbType.Int) { Direction = ParameterDirection.Output } ,new SqlParameter("@csharp",SqlDbType.Float) { Direction = ParameterDirection.Output } ,new SqlParameter("@db",SqlDbType.Float) { Direction = ParameterDirection.Output }};DataSet set = SqlHelper.ExecutProcedure("usp_queryScore", paras);result.Total = Convert.ToInt32(paras[1].Value);result.Missing = Convert.ToInt32(paras[2].Value);result.CSharp = paras[3].Value is DBNull ? 0 : Convert.ToSingle(paras[3].Value);result.Db = paras[4].Value is DBNull ? 0 : Convert.ToSingle(paras[4].Value);//获取集合result.ScoreDataTable = set.Tables[0];result.MissingDataTable = set.Tables[1];return result;}9,类型转换
--数字不能与字符串通过+直接相加所以使用convert进行转换
select CONVERT(varchar(20), @first)+@second
--获取日期部分
select CONVERT(date,getdate())
--数字转为字符串
select CAST(100 as varchar(20))10,表格
--创建数据表
if (exists(select * from sysobjects where name='MenuList'))
drop table MenuList
go
create table MenuList
(MenuId int identity(100,1) primary key,MenuName varchar(50),MenuCode varchar(50),Tag int,ParentId int not null
)
go--清空表格
truncate table menulist--彻底删除表格
drop table menulist11,账号管理
--创建登录账号,登录密码
use master
go
exec sp_addlogin 'lzg','1'
--创建数据库用户,指定用户可以访问哪些数据库
use SMDB
go
exec sp_grantdbaccess 'lzg'--dbo用户
--表示数据库的所有者(DB Owner),无法删除dbo用户,该用户始终出现在每个数据库中。
--abo用户默认分配给sa登录账号--删除登录账号
use master
go
exec sp_droplogin 'lzg'--删除数据库用户
use SMDB
exec sp_dropuser 'lzg'