目录
- 背景描述
- 数据说明
- 数据集来源
- 问题描述
- 分析目标以及导入模块
- 1. 数据导入
- 2. 数据基本信息和基本处理
- 3. 数据处理
- 3.1 新建data_clean数据框
- 3.2 数值型数据处理
- 3.2.1 “auth_capital”(注册资本)
- 3.2.2 “day_per_week”(每周工作天数)
- 3.2.3 “num_employee”(公司规模)
- 3.2.4 “time_span”(实习月数)
- 3.2.5 “wage”(每天工资)
- 3.3 时间数据处理
- 3.3.1 “est_date”(公司成立日期)
- 3.3.2 “job_deadline”(截止时间)
- 3.3.3 “released_time”(发布时间)
- 3.3.4 “update_time”(更新时间)
- 3.4 字符型数据处理
- 3.4.1 “city”(城市)处理
- 3.4.2 “com_class”(公司和企业类型)处理
- 3.4.3 “com_logo”(公司logo)、“industry”(行业)也暂时不处理
- 4. 数据分析
- 4.1 数据基本情况
- 4.2 城市与职位数量
- 4.3 薪资
- 4.3.1 平均薪资
- 4.3.2 薪资与城市
- 4.4 学历
- 4.4.1 数据挖掘、机器学习算法的学历要求
- 4.4.2 学历与薪资
- 4.5 行业
- 4.6 公司
- 4.6.1 公司与职位数量、平均实习月薪
- 4.6.2 公司规模与职位数量
- 4.6.3 公司规模与实习月薪
- 4.6.4 公司实习期长度
- 4.6.5 企业成立时间
- 5. 给小E挑选实习公司
- 6. logo拼图
- 附录
背景描述
主要对“实习僧网站”招聘数据挖掘、机器学习的实习岗位信息进行分析。数据主要来自“数据挖掘”、“机器学习”和“算法”这3个关键词下的数据。由于原始数据还比较脏,本文使用pandas进行数据处理和分析,结合seaborn和pyecharts包进行数据可视化。
数据说明
准备数据集以及一个空文件
1.datamining.csv
2.machinelearning.csv
3.mlalgorithm.csv
4.data_clean.csv(空文件,以便清洗后存放干净数据)
数据集来源
https://github.com/Alfred1984/interesting-python/tree/master/shixiseng
问题描述
该数据主要用于“实习僧网站”招聘数据挖掘、机器学习的实习岗位信息进行分析
分析目标以及导入模块
1.由于小E想要找的实习公司是机器学习算法相关的工作,所以只对“数据挖掘”、“机器学习”、“算法”这三个关键字进行了爬取;
2.因此,分析目标就是国内公司对机器学习算法实习生的需求状况(仅基于实习僧网站),以及公司相关的分析。
1. 数据导入

2. 数据基本信息和基本处理



3. 数据处理
3.1 新建data_clean数据框

3.2 数值型数据处理
3.2.1 “auth_capital”(注册资本)




3.2.2 “day_per_week”(每周工作天数)


3.2.3 “num_employee”(公司规模)


3.2.4 “time_span”(实习月数)


3.2.5 “wage”(每天工资)

3.3 时间数据处理
3.3.1 “est_date”(公司成立日期)


3.3.2 “job_deadline”(截止时间)


3.3.3 “released_time”(发布时间)

3.3.4 “update_time”(更新时间)


3.4 字符型数据处理
3.4.1 “city”(城市)处理



3.4.2 “com_class”(公司和企业类型)处理



3.4.3 “com_logo”(公司logo)、“industry”(行业)也暂时不处理

4. 数据分析
4.1 数据基本情况

4.2 城市与职位数量





4.3 薪资
4.3.1 平均薪资

4.3.2 薪资与城市



4.4 学历
4.4.1 数据挖掘、机器学习算法的学历要求


4.4.2 学历与薪资


4.5 行业




4.6 公司
4.6.1 公司与职位数量、平均实习月薪
4.6.2 公司规模与职位数量

4.6.3 公司规模与实习月薪

4.6.4 公司实习期长度

4.6.5 企业成立时间




5. 给小E挑选实习公司


6. logo拼图



附录
导入模块
!pip install pyecharts==0.5.6
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pyecharts
plt.style.use('ggplot')
%matplotlib inline
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
1. 数据导入
data_dm = pd.read_csv("datamining.csv")
data_ml = pd.read_csv("machinelearning.csv")
data_al = pd.read_csv("mlalgorithm.csv")
data = pd.concat([data_dm, data_ml, data_al], ignore_index = True)
2. 数据基本信息和基本处理
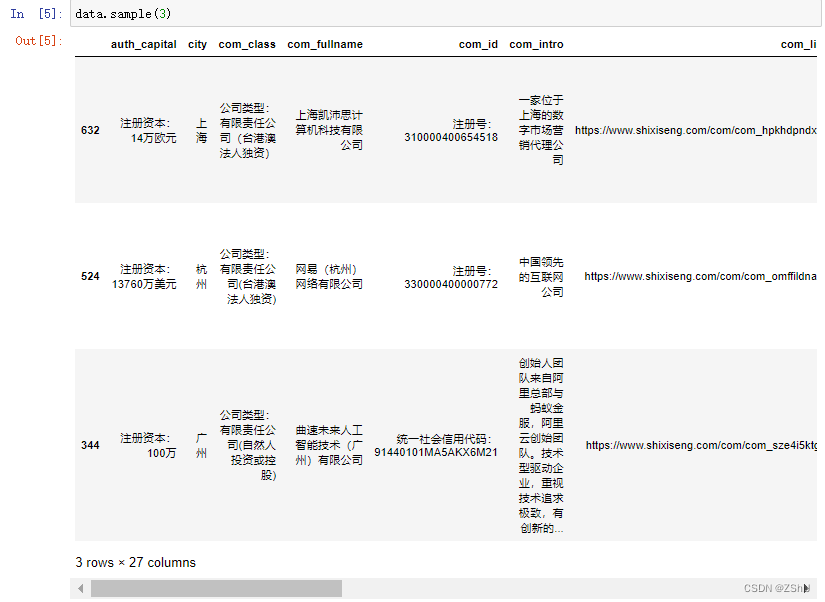
data.sample(3)
data.loc[666]
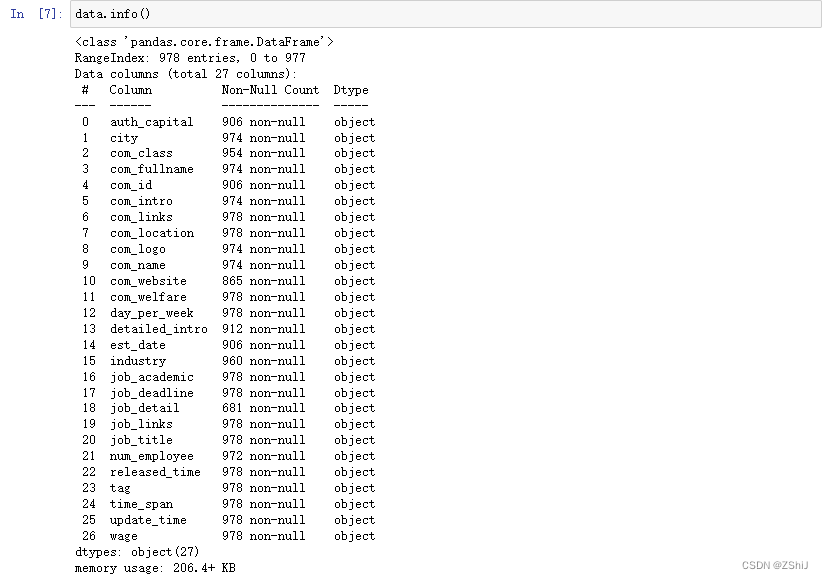
data.info()
data.drop_duplicates(subset='job_links', inplace=True)
data.shape
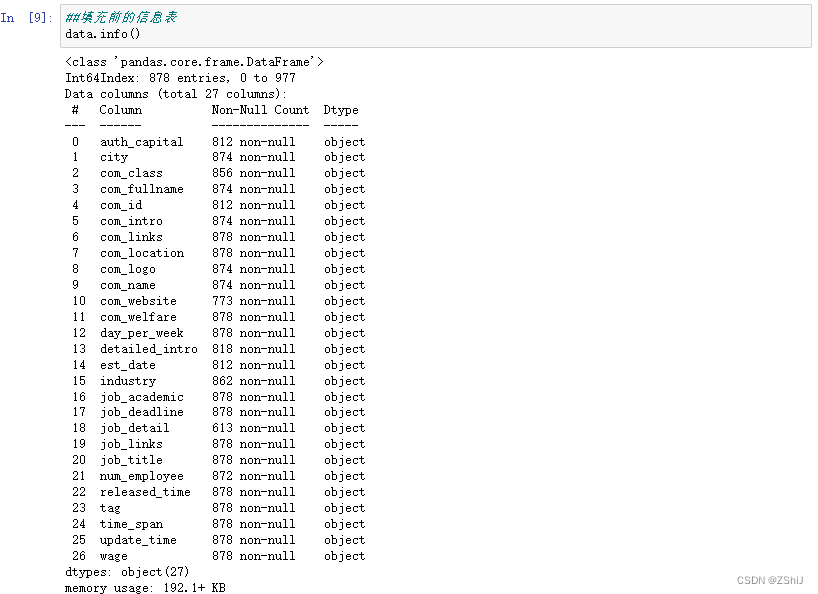
##填充前的信息表
data.info()
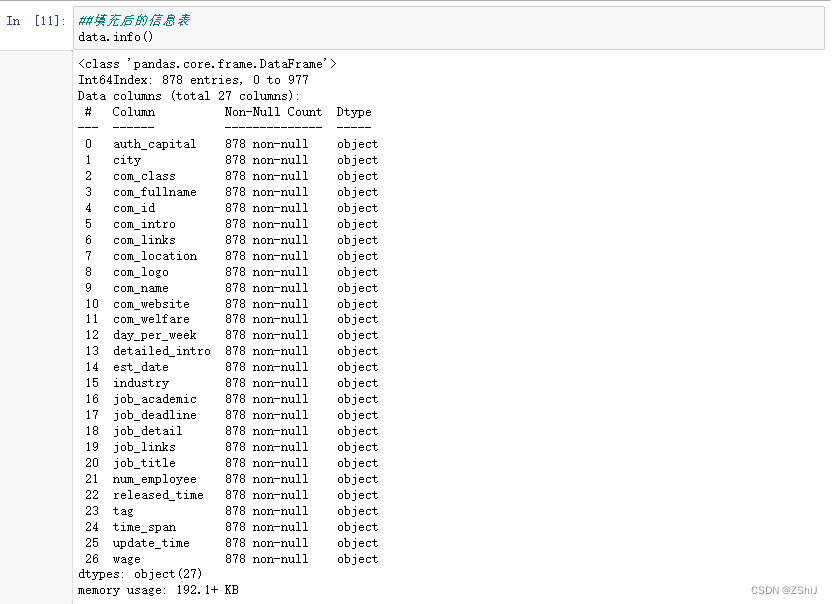
####将所有缺失值均补为'无')
data=data.fillna('无')##填充后的信息表
data.info()
*3. 数据处理
3.1 新建data_clean数据框
data_clean = data.drop(['com_id', 'com_links', 'com_location', 'com_website', 'com_welfare', 'detailed_intro', 'job_detail'], axis = 1)
3.2 数值型数据处理
3.2.1 “auth_capital”(注册资本)
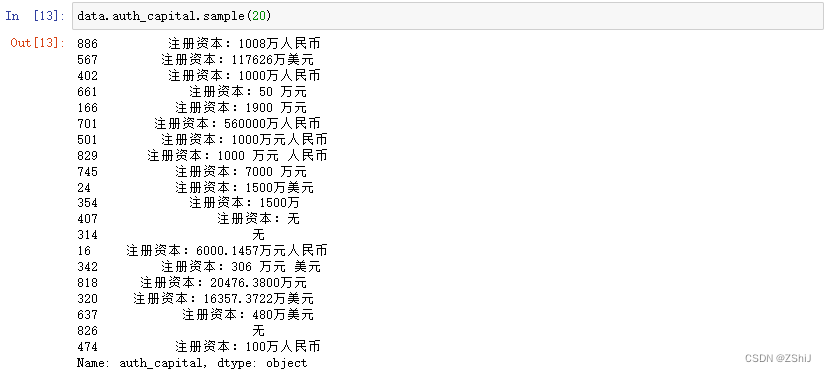
data.auth_capital.sample(20)
auth_capital = data['auth_capital'].str.split(':', expand = True)
auth_capital.sample(5)
auth_capital['num'] = auth_capital[1].str.extract('([0-9.]+)', expand=False).astype('float')
auth_capital.sample(5)
auth_capital[1].str.split('万', expand = True)[1].unique()
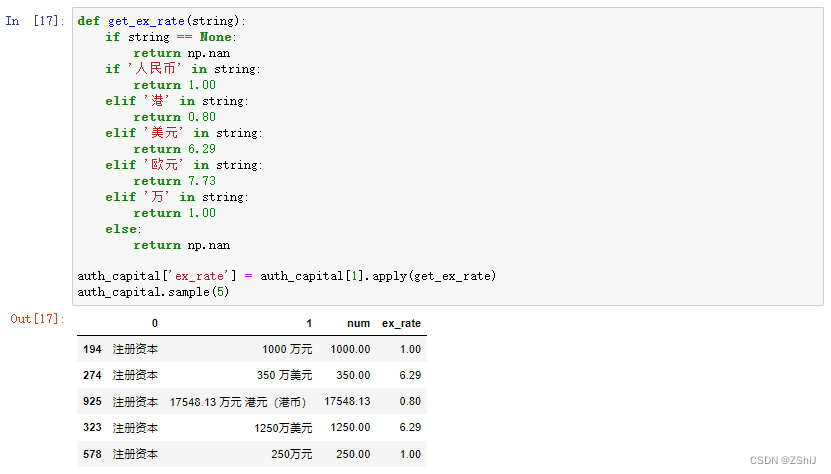
def get_ex_rate(string):if string == None:return np.nanif '人民币' in string:return 1.00elif '港' in string:return 0.80elif '美元' in string:return 6.29elif '欧元' in string:return 7.73elif '万' in string:return 1.00else:return np.nanauth_capital['ex_rate'] = auth_capital[1].apply(get_ex_rate)
auth_capital.sample(5)
data_clean['auth_capital'] = auth_capital['num'] * auth_capital['ex_rate']
data_clean['auth_capital'].head() ##此方法用于返回数据帧或序列的前n行(默认值为5)。
3.2.2 “day_per_week”(每周工作天数)
data.day_per_week.unique()
data_clean.loc[data['day_per_week'] == '2天/周', 'day_per_week'] = 2
data_clean.loc[data['day_per_week'] == '3天/周', 'day_per_week'] = 3
data_clean.loc[data['day_per_week'] == '4天/周', 'day_per_week'] = 4
data_clean.loc[data['day_per_week'] == '5天/周', 'day_per_week'] = 5
data_clean.loc[data['day_per_week'] == '6天/周', 'day_per_week'] = 6
3.2.3 “num_employee”(公司规模)
data.num_employee.unique()
data_clean.loc[data['num_employee'] == '少于15人', 'num_employee'] = '小型企业'
data_clean.loc[data['num_employee'] == '15-50人', 'num_employee'] = '小型企业'
data_clean.loc[data['num_employee'] == '50-150人', 'num_employee'] = '小型企业'
data_clean.loc[data['num_employee'] == '150-500人', 'num_employee'] = '中型企业'
data_clean.loc[data['num_employee'] == '500-2000人', 'num_employee'] = '中型企业'
data_clean.loc[data['num_employee'] == '2000人以上', 'num_employee'] = '大型企业'
data_clean.loc[data['num_employee'] == '5000人以上', 'num_employee'] = '大型企业'
data_clean.loc[data['num_employee'].isna(), 'num_employee'] = np.nan
3.2.4 “time_span”(实习月数)
data.time_span.unique()
mapping = {}
for i in range(1,19):mapping[str(i) + '个月'] = i
print(mapping)
data_clean['time_span'] = data['time_span'].map(mapping)
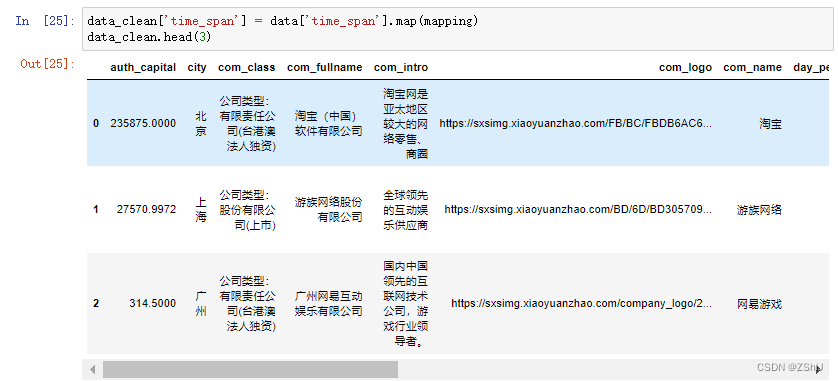
data_clean.head(3)
3.2.5 “wage”(每天工资)
data['wage'].sample(5)
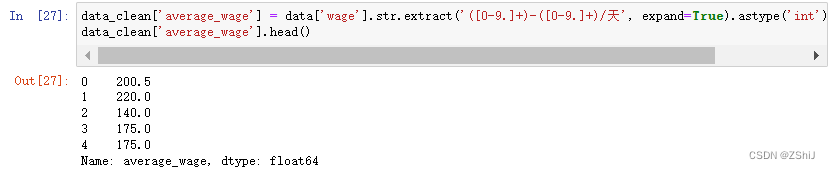
data_clean['average_wage'] = data['wage'].str.extract('([0-9.]+)-([0-9.]+)/天', expand=True).astype('int').mean(axis = 1)
data_clean['average_wage'].head()
3.3 时间数据处理
3.3.1 “est_date”(公司成立日期)
data['est_date'].sample(5)
data_clean['est_date'] = pd.to_datetime(data['est_date'].str.extract('成立日期:([0-9-]+)', expand=False))
data_clean['est_date'].sample(5)
3.3.2 “job_deadline”(截止时间)
data['job_deadline'].sample(5)
data_clean['job_deadline'] = pd.to_datetime(data['job_deadline'])
3.3.3 “released_time”(发布时间)
data['released_time'].sample(5)
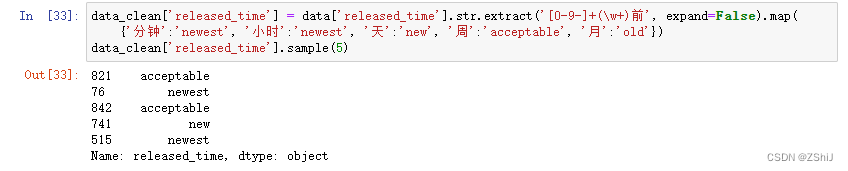
data_clean['released_time'] = data['released_time'].str.extract('[0-9-]+(\w+)前', expand=False).map({'分钟':'newest', '小时':'newest', '天':'new', '周':'acceptable', '月':'old'})
data_clean['released_time'].sample(5)
3.3.4 “update_time”(更新时间)
data['update_time'].sample(5)
data_clean['update_time'] = pd.to_datetime(data['update_time'])
3.4 字符型数据处理
3.4.1 “city”(城市)处理
data['city'].unique()
data_clean.loc[data_clean['city'] == '成都市', 'city'] = '成都'
data_clean.loc[data_clean['city'].isin(['珠海市', '珠海 深圳', '珠海']), 'city'] = '珠海'
data_clean.loc[data_clean['city'] == '上海漕河泾开发区', 'city'] = '上海'
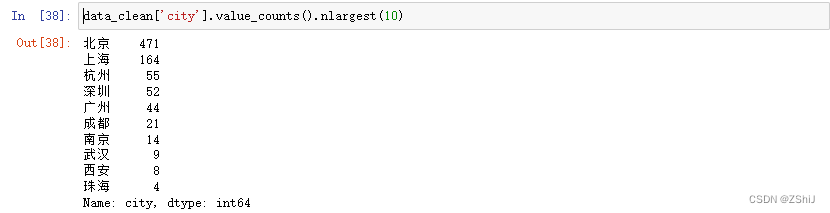
#招聘实习生前10的城市
data_clean['city'].value_counts().nlargest(10)
data_clean['city'].value_counts().nlargest(10).plot(kind = 'bar')
3.4.2 “com_class”(公司和企业类型)处理
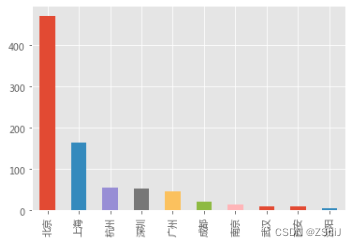
list(data['com_class'].unique())
def get_com_type(string):if string == None:return np.nanelif ('非上市' in string) or ('未上市' in string):return '股份有限公司(未上市)'elif '股份' in string:return '股份有限公司(上市)'elif '责任' in string:return '有限责任公司'elif '外商投资' in string:return '外商投资公司'elif '有限合伙' in string:return '有限合伙企业'elif '全民所有' in string:return '国有企业'else:return np.nan
com_class = data['com_class'].str.split(':', expand = True)
com_class['com_class'] = com_class[1].apply(get_com_type)
com_class.sample(5)
data_clean['com_class'] = com_class['com_class']
3.4.3 “com_logo”(公司logo)、“industry”(行业)也暂时不处理
data_clean = data_clean.reindex(columns=['com_fullname', 'com_name', 'job_academic', 'job_links', 'tag','auth_capital', 'day_per_week', 'num_employee', 'time_span','average_wage', 'est_date', 'job_deadline', 'released_time','update_time', 'city', 'com_class', 'com_intro', 'job_title','com_logo', 'industry'])
data_clean.to_csv('data_clean.csv', index = False)
4. 数据分析
4.1 数据基本情况
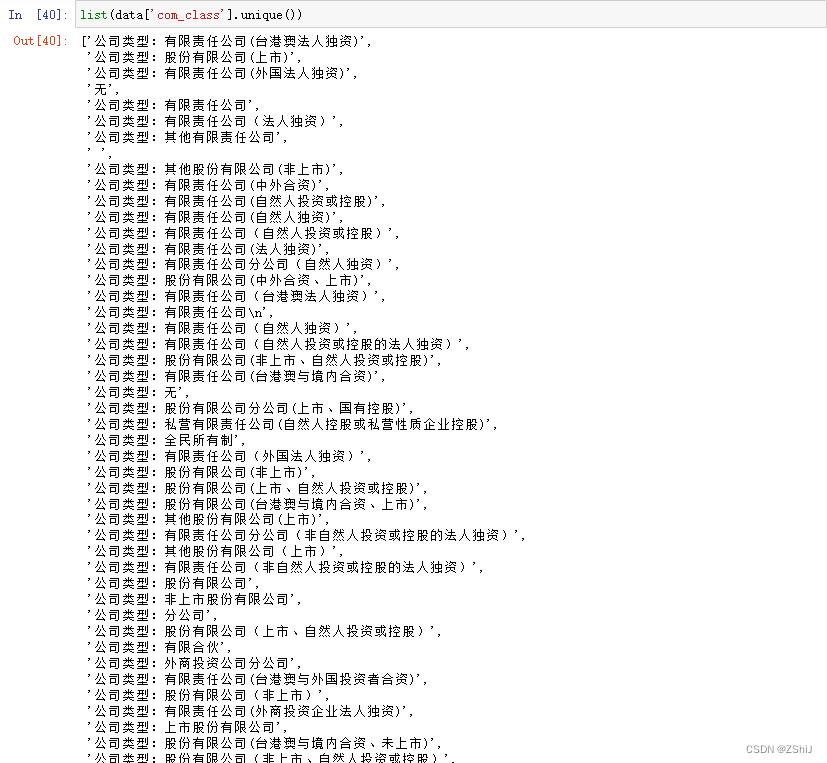
data_clean.sample(3)
data_clean.info()
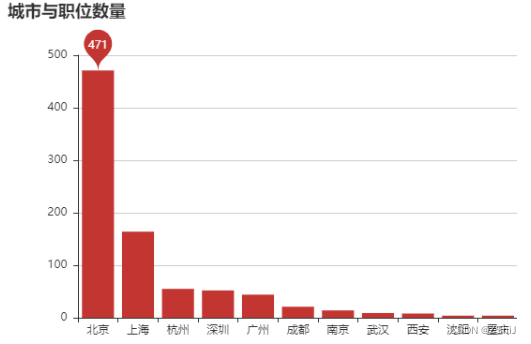
4.2 城市与职位数量
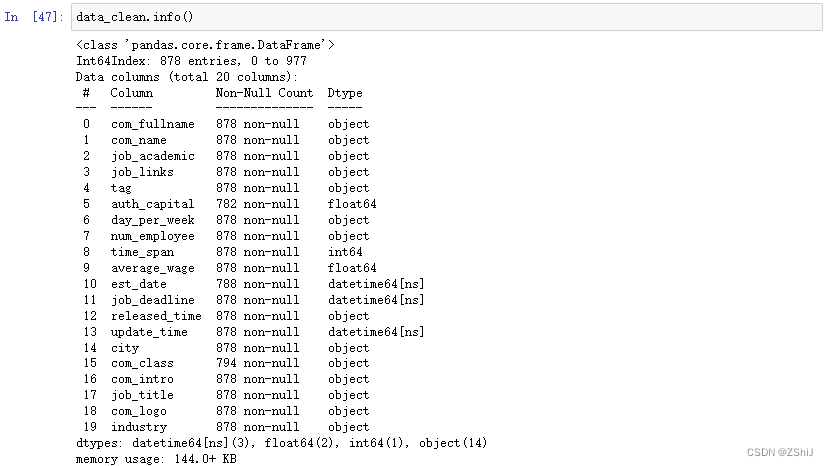
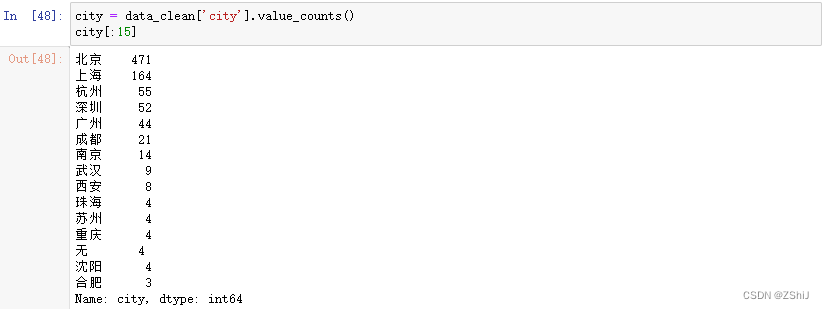
city = data_clean['city'].value_counts()
city[:15]
bar = pyecharts.Bar('城市与职位数量')
bar.add('', city[:15].index, city[:15].values, mark_point=["max"])
bar
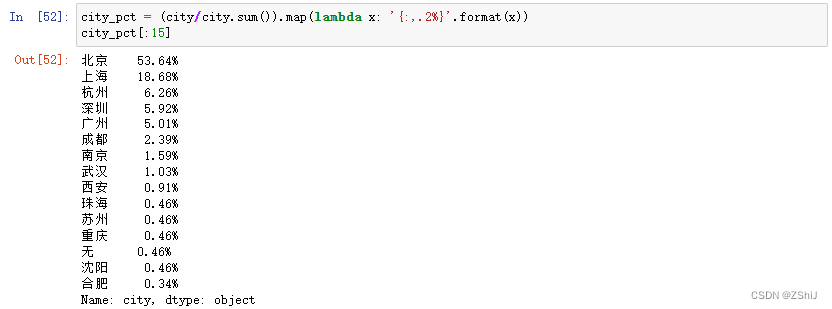
city_pct = (city/city.sum()).map(lambda x: '{:,.2%}'.format(x))
city_pct[:15]
(city/city.sum())[:5].sum()
data_clean.loc[data_clean['city'] == '杭州', 'com_name'].value_counts()[:5]
def topN(dataframe, n=5):counts = dataframe.value_counts()return counts[:n]
data_clean.groupby('city').com_name.apply(topN).loc[list(city_pct[:15].index)]
4.3 薪资
4.3.1 平均薪资
data_clean['salary'] = data_clean['average_wage'] * data_clean['day_per_week'] * 4
data_clean['salary'].mean()
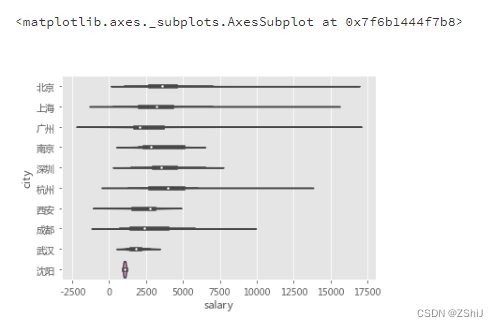
4.3.2 薪资与城市
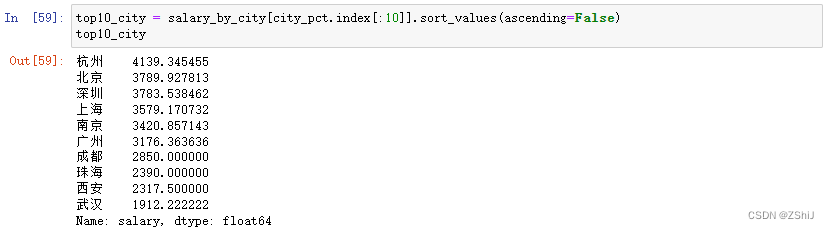
salary_by_city = data_clean.groupby('city')['salary'].mean()
salary_by_city.nlargest(10)
top10_city = salary_by_city[city_pct.index[:10]].sort_values(ascending=False)
top10_city
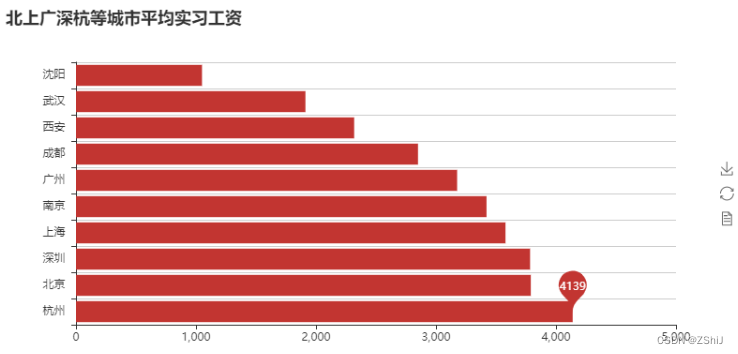
bar = pyecharts.Bar('北上广深杭等城市平均实习工资')
bar.add('', top10_city.index, np.round(top10_city.values, 0), mark_point=["max"], is_convert=True)
bar
top10_city_box = data_clean.loc[data_clean['city'].isin(top10_city.index),:]
sns.violinplot(x ='salary', y ='city', data = top10_city_box)
4.4 学历
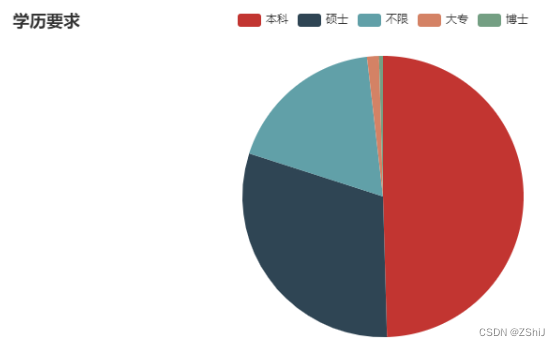
4.4.1 数据挖掘、机器学习算法的学历要求
job_academic = data_clean['job_academic'].value_counts()
job_academic
pie = pyecharts.Pie("学历要求")
pie.add('', job_academic.index, job_academic.values)
pie
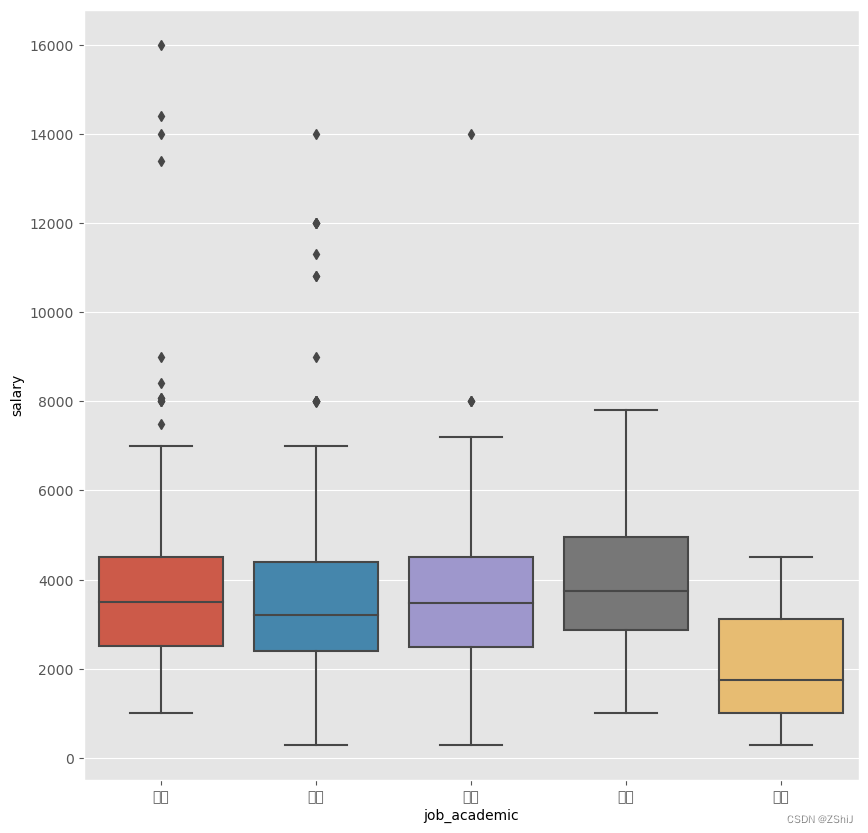
4.4.2 学历与薪资
data_clean.groupby(['job_academic'])['salary'].mean().sort_values()
sns.boxplot(x="job_academic", y="salary", data=data_clean)
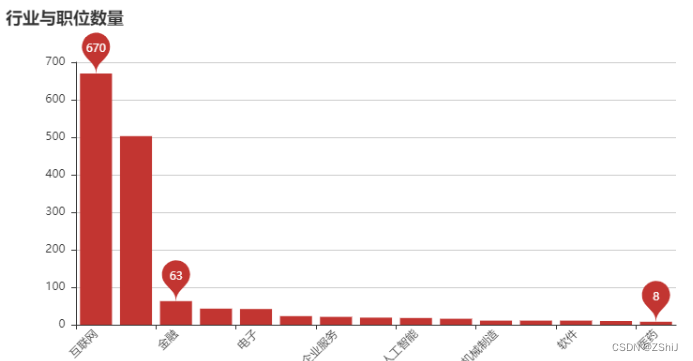
4.5 行业
data_clean['industry'].sample(5)
industry = data_clean.industry.str.split('/|,|,', expand = True)
industry_top15 = industry.apply(pd.value_counts).sum(axis = 1).nlargest(15)
bar = pyecharts.Bar('行业与职位数量')
bar.add('', industry_top15.index, industry_top15.values, mark_point=["max","min","average"], xaxis_rotate=45)
bar
4.6 公司
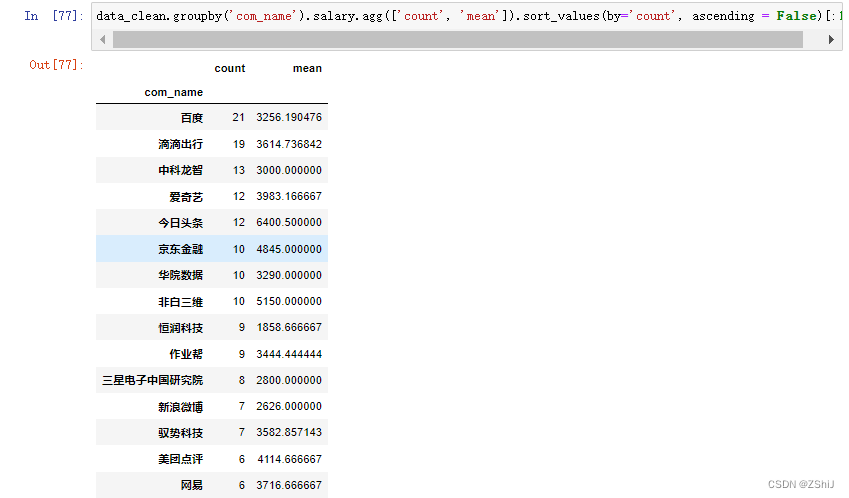
4.6.1 公司与职位数量、平均实习月薪
data_clean.groupby('com_name').salary.agg(['count', 'mean']).sort_values(by='count', ascending = False)[:15]
4.6.2 公司规模与职位数量
data_clean['num_employee'].value_counts()
4.6.3 公司规模与实习月薪
data_clean.groupby('num_employee')['salary'].mean()
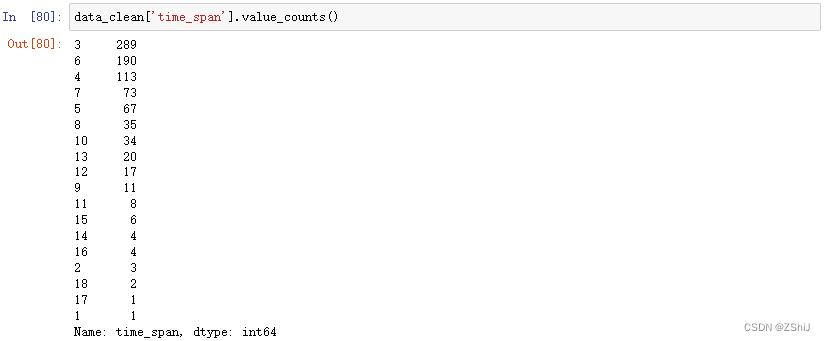
4.6.4 公司实习期长度
data_clean['time_span'].value_counts()
data_clean['time_span'].mean()
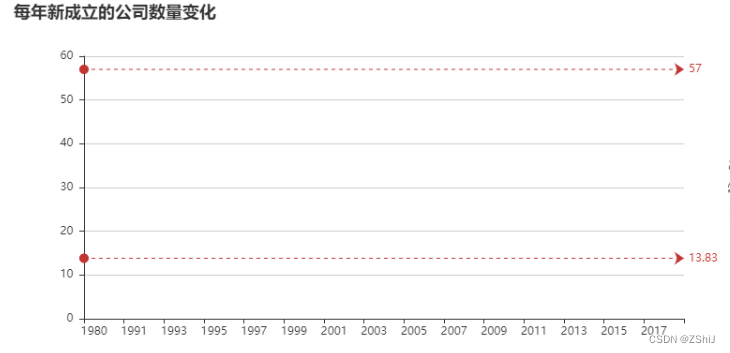
4.6.5 企业成立时间
est_date = data_clean.drop_duplicates(subset='com_name')
import warnings
warnings.filterwarnings('ignore')
est_date['est_year'] = pd.DatetimeIndex(est_date['est_date']).year
num_com_by_year = est_date.groupby('est_year')['com_name'].count()
line = pyecharts.Line("每年新成立的公司数量变化")
line.add("", num_com_by_year.index, num_com_by_year.values, mark_line=["max", "average"])
line
scale_VS_year = est_date.groupby(['num_employee', 'est_year'])['com_name'].count()
scale_VS_year_s = scale_VS_year['小型企业'].reindex(num_com_by_year.index, fill_value=0)
scale_VS_year_m = scale_VS_year['中型企业'].reindex(num_com_by_year.index, fill_value=0)
scale_VS_year_l = scale_VS_year['大型企业'].reindex(num_com_by_year.index, fill_value=0)line = pyecharts.Line("新成立的企业与规模")
line.add("小型企业", scale_VS_year_s.index, scale_VS_year_s.values, is_label_show=True)
line.add("中型企业", scale_VS_year_m.index, scale_VS_year_m.values, is_label_show=True)
line.add("大型企业", scale_VS_year_l.index, scale_VS_year_l.values, is_label_show=True)
line
5. 给小E挑选实习公司
E_data = data_clean.loc[(data_clean['city'] == '深圳') & (data_clean['job_academic'] != '博士') & (data_clean['time_span'].isin([1,2,3])) & (data_clean['salary'] > 3784) & (data_clean['released_time'] == 'newest'), :]
E_data['com_name'].unique()
data.loc[E_data.index, ['job_title', 'job_links']]
6. logo拼图
import os
import requests
from PIL import Imagedata_logo = data_clean[['com_logo', 'com_name']]
data_logo.drop_duplicates(subset='com_name', inplace=True)
data_logo.dropna(inplace=True)
data_logo['com_name'] = data_logo['com_name'].str.replace('/', '-')
com_logo = list(data_logo['com_logo'])
com_name = list(data_logo['com_name'])path_list = []
num_logo = 0
#####注意:先在左边文件树创建文件夹
for logo_index in range(len(com_logo)):try:response = requests.get(com_logo[logo_index])suffix = com_logo[logo_index].split('.')[-1]path = 'logo/{}.{}'.format(com_name[logo_index], suffix)##logo 文件logo的路径path_list.append(path)with open(path, 'wb') as f:f.write(response.content)num_logo += 1except:print('Failed downloading logo of', com_name[logo_index])
print('Successfully downloaded ', str(num_logo), 'logos!')
x = y = 0
line = 20
NewImage = Image.new('RGB', (128*line, 128*line))
for item in path_list:try:img = Image.open(item)img = img.resize((128, 128), Image.ANTIALIAS)NewImage.paste(img, (x * 128, y * 128))x += 1except IOError:print("第%d行,%d列文件读取失败!IOError:%s" % (y, x, item))x -= 1if x == line:x = 0y += 1if (x + line * y) == line * line:break
##注:先在左侧文件上传一jpg(建议纯白)
NewImage.save("test.JPG") ##test.JPG是自己创建图片的路径
##显示生成的logo拼图
import matplotlib.image as mpimg # mpimg 用于读取图片lena = mpimg.imread('test.JPG') # 读取和代码处于同一目录下的 lena.png
# 此时 lena 就已经是一个 np.array 了,可以对它进行任意处理
lena.shape #(512, 512, 3)plt.imshow(lena) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()