文章目录
- 1. 什么是大模型
- 2. 检索增强生成 RAG
- 一、什么是 RAG
- 二、RAG 的工作流程
- 3. langChain介绍
- 一、什么是 LangChain
- 二、LangChain 的核心组件
- 4. 开发 LLM 应用的整体流程
- 一、何为大模型开发
- 二、大模型开发的一般流程
- 三、搭建 LLM 项目的流程简析(以知识库助手为例)
- 步骤一:项目规划与需求分析
- 步骤二:数据准备与向量知识库构建
- 步骤三:大模型集成与 API 连接
- 步骤四:核心功能实现
- 步骤五:核心功能迭代优化
- 步骤六:前端与用户交互界面开发
- 步骤七:部署测试与上线
- 步骤八:维护与持续改进
1. 什么是大模型
一种旨在理解和生成人类语言的人工智能模型
2. 检索增强生成 RAG
一、什么是 RAG
指导大型语言模型生成更为精准的答案
LLM面临如下挑战
- 信息偏差/幻觉: LLM 有时会产生与客观事实不符的信息。RAG 通过检索数据源,确保输出内容的精确性和可信度,减少信息偏差
- 知识更新滞后性:LLM 基于静态的数据集训练,这可能导致模型的知识更新滞后,RAG 通过实时检索最新数据,保持内容的时效性
- …
二、RAG 的工作流程
RAG工作可以分为以下4个阶段:数据处理、检索、增强和生成
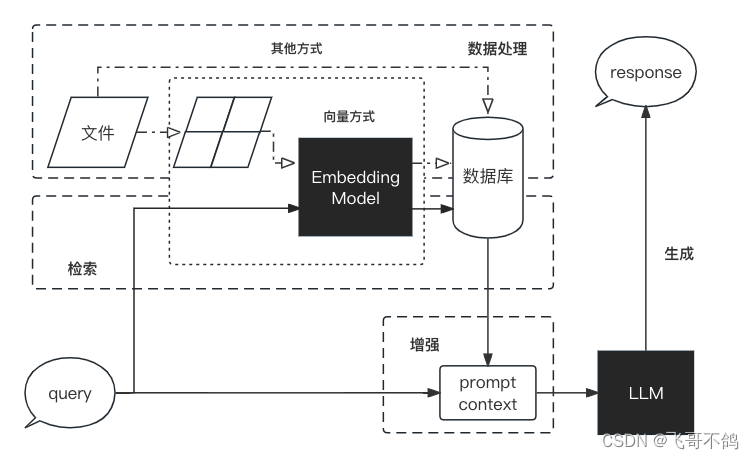
- 数据处理:清洗原始数据,转换为可检索格式,然后存入db
- 检索:将用户的问题在db中检索
- 增强:增强检索到的信息,让模型更容易理解
- 生成:生成模型依据增强结果,生成回答
3. langChain介绍
一、什么是 LangChain
LangChain是一个开源框架,为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程,帮助开发者们快速构建基于大型语言模型的端到端应用程序或工作流程
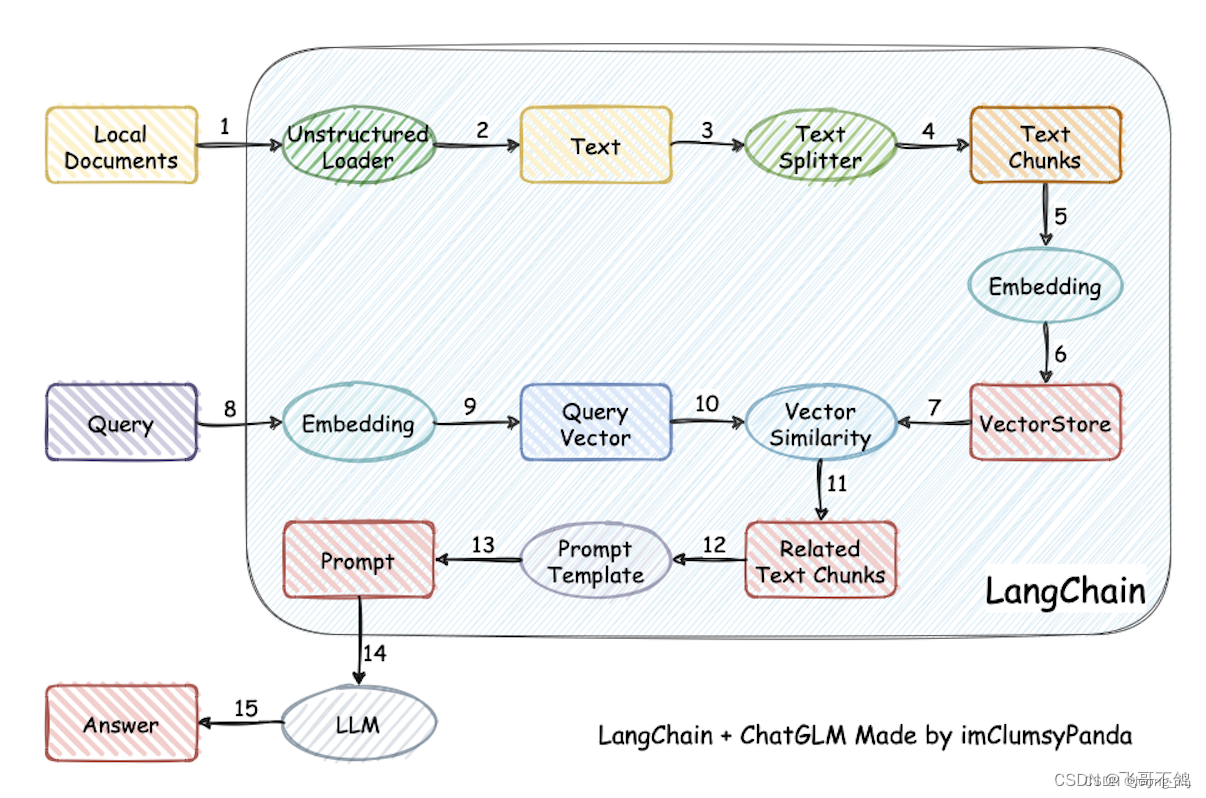
利用 LangChain 框架,我们可以轻松地构建如下所示的 RAG 应用
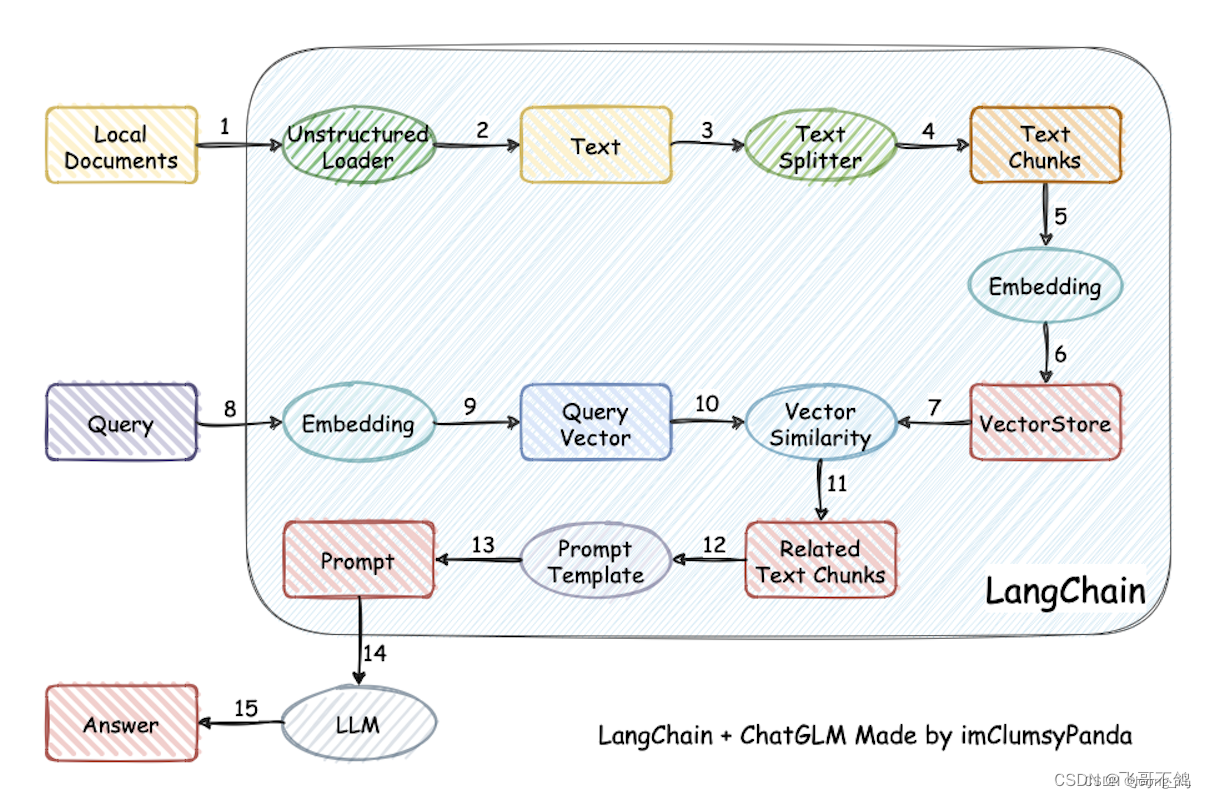
二、LangChain 的核心组件
LangChain 主要由以下 6 个核心组件组成:
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。比如后续我们会将搭建检索问答链来完成检索问答。
- 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
4. 开发 LLM 应用的整体流程
一、何为大模型开发
通过大预言模型强大的理解生成能力,结合自身数据与业务,开发出来的应用程序称为大模型发开
用通俗的话来说,就是调用大模型api,开发属于自己的产品。比如暴躁女友在线聊天软件

大模型开发要素:

二、大模型开发的一般流程
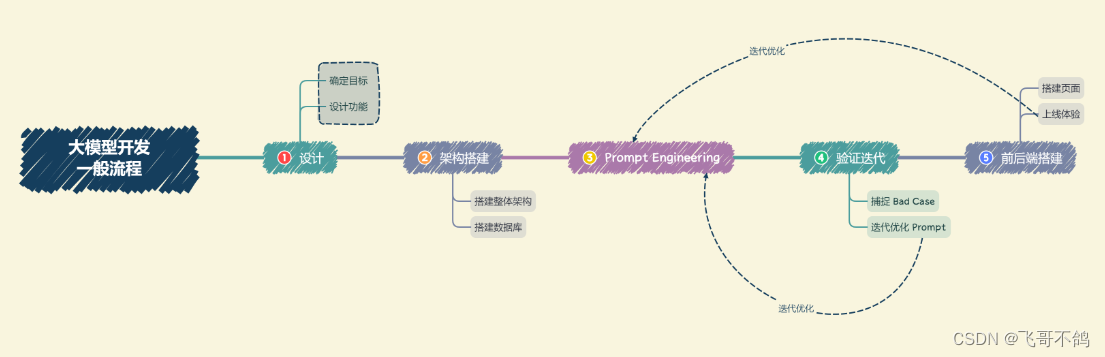
-
确定目标: 在开发之前,明确应用的目标、场景和受众,尽量首选最小可行产品(MVP)作为起点,逐步完善。
-
设计功能: 根据目标,设计应用的功能和实现逻辑,着重于核心功能,逐步扩展上下游功能,确保全面覆盖用户需求。
-
搭建整体架构: 基于特定数据库、Prompt和通用大模型的架构,使用LangChain等框架,构建从用户输入到应用输出的完整流程。
-
搭建数据库: 建立个性化数据库支持,使用Chroma等向量数据库进行数据预处理、向量化存储,确保数据质量和向量化构建。
-
Prompt工程化: 通过迭代构建高质量的Prompt,对大模型性能具有重要影响,包括原则、技巧、小型验证集设计和Prompt的持续优化。
-
验证迭代: 通过发现Bad Case并改进Prompt工程化,不断优化系统效果,应对各种边界情况,直至达到稳定且能实现目标的Prompt版本。
-
前后端搭建: 核心功能完成后,进行前后端搭建,设计产品页面,利用Gradio和Streamlit等工具帮助快速搭建可视化页面,实现Demo上线。
-
体验优化: 上线后,持续跟踪用户体验,记录Bad Case和用户反馈,针对性优化,确保长期用户满意度。
三、搭建 LLM 项目的流程简析(以知识库助手为例)
以下我们将结合本实践项目与上文的整体流程介绍,简要分析知识库助手项目开发流程:
步骤一:项目规划与需求分析
1.项目目标:基于个人知识库的问答助手
2.核心功能:
- 将爬取并总结的MD文件及用户上传文档向量化,并创建知识库;
- 选择知识库,检索用户提问的知识片段;
- 提供知识片段与提问,获取大模型回答;
- 流式回复;
- 历史对话记录
3.确定技术架构和工具
- 框架:LangChain
- Embedding模型:GPT、智谱、M3E
- 数据库:Chroma
- 大模型:GPT、讯飞星火、文心一言、GLM 等
- 前后端:Gradio 和 Streamlit
步骤二:数据准备与向量知识库构建
加载本地文档 -> 读取文本 -> 文本分割 -> 文本向量化 -> question 向量化 -> 在文本向量中匹配出与问句向量最相似的 top k 个 -> 匹配出的文本作为上下文和问题一起添加到 Prompt 中 -> 提交给 LLM 生成回答。
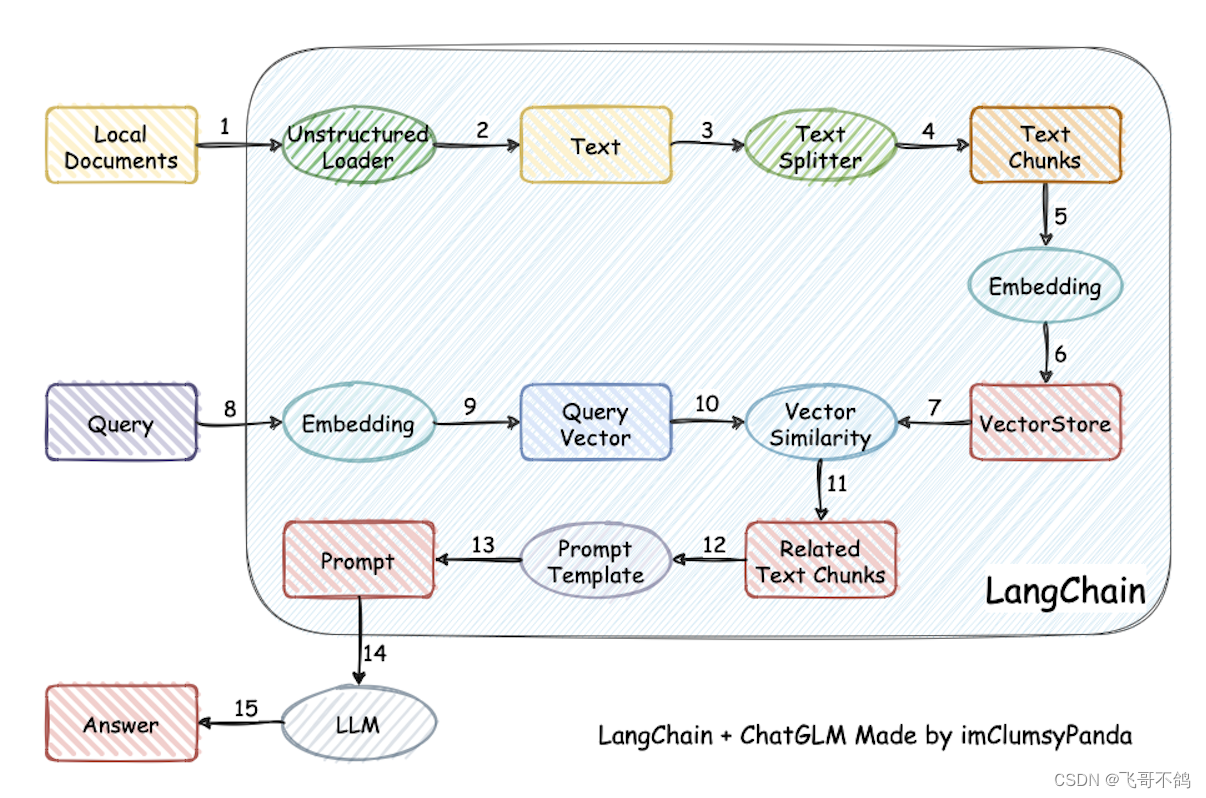
-
文档收集与处理:
- 收集用户提供的文档,如PDF、TXT、MD等格式。
- 使用LangChain的文档加载器或Python包进行读取。
- 将长文档切分为短文本,每段文本作为一个知识单位。
-
文档向量化:
- 利用文本嵌入技术将文档片段向量化,保持语义相似性。
- 将向量化的文本存入向量数据库,建立索引以实现快速检索。
-
建立知识库索引:
- 将向量化的文档导入Chroma知识库,利用LangChain集成向量数据库。
- 通过向量相关性算法(如余弦算法)匹配最相似的知识库片段,作为上下文与用户问题一起提交给LLM进行回答。
步骤三:大模型集成与 API 连接
- 集成 GPT、星火、文心、GLM 等大模型,配置 API 连接。
- 编写代码,实现与大模型 API 的交互,以便获取问题回答。
步骤四:核心功能实现
-
Prompt工程化和流式回复:
- 建立Prompt工程,使大模型能够根据用户提问和知识库内容生成回答。
- 实现流式回复功能,支持用户进行多轮对话,提高交互自然度和连贯性。
-
历史对话记录功能:
- 添加历史对话记录功能,记录用户与助手的交互历史。
- 保存对话记录,为用户提供更好的个性化服务和回溯功能。
步骤五:核心功能迭代优化
- 进行验证评估,收集 Bad Case。
- 根据 Bad Case 迭代优化核心功能实现。
步骤六:前端与用户交互界面开发
- 使用 Gradio 和 Streamlit 搭建前端界面。
- 实现用户上传文档、创建知识库的功能。
- 设计用户界面,包括问题输入、知识库选择、历史记录展示等。
步骤七:部署测试与上线
部署问答助手到服务器或云平台,上线并向用户发布。
步骤八:维护与持续改进
-
系统监测与用户反馈:
- 监测系统性能和用户反馈,快速响应并处理问题,确保系统稳定运行。
-
知识库更新:
- 定期更新知识库,添加新文档和信息,保持知识库内容的时效性和全面性。
-
用户需求收集与改进:
- 主动收集用户需求,进行系统改进和功能扩展,提升用户体验和系统功能。