作者:Philipp Kahr

Elasticsearch Service 用户的重要注意事项:目前,本文中描述的 Kibana 设置更改仅限于 Cloud 控制台,如果没有我们支持团队的手动干预,则无法进行配置。 我们的工程团队正在努力消除对这些设置的限制,以便我们的所有用户都可以启用内部 APM。 本地部署不受此问题的影响。
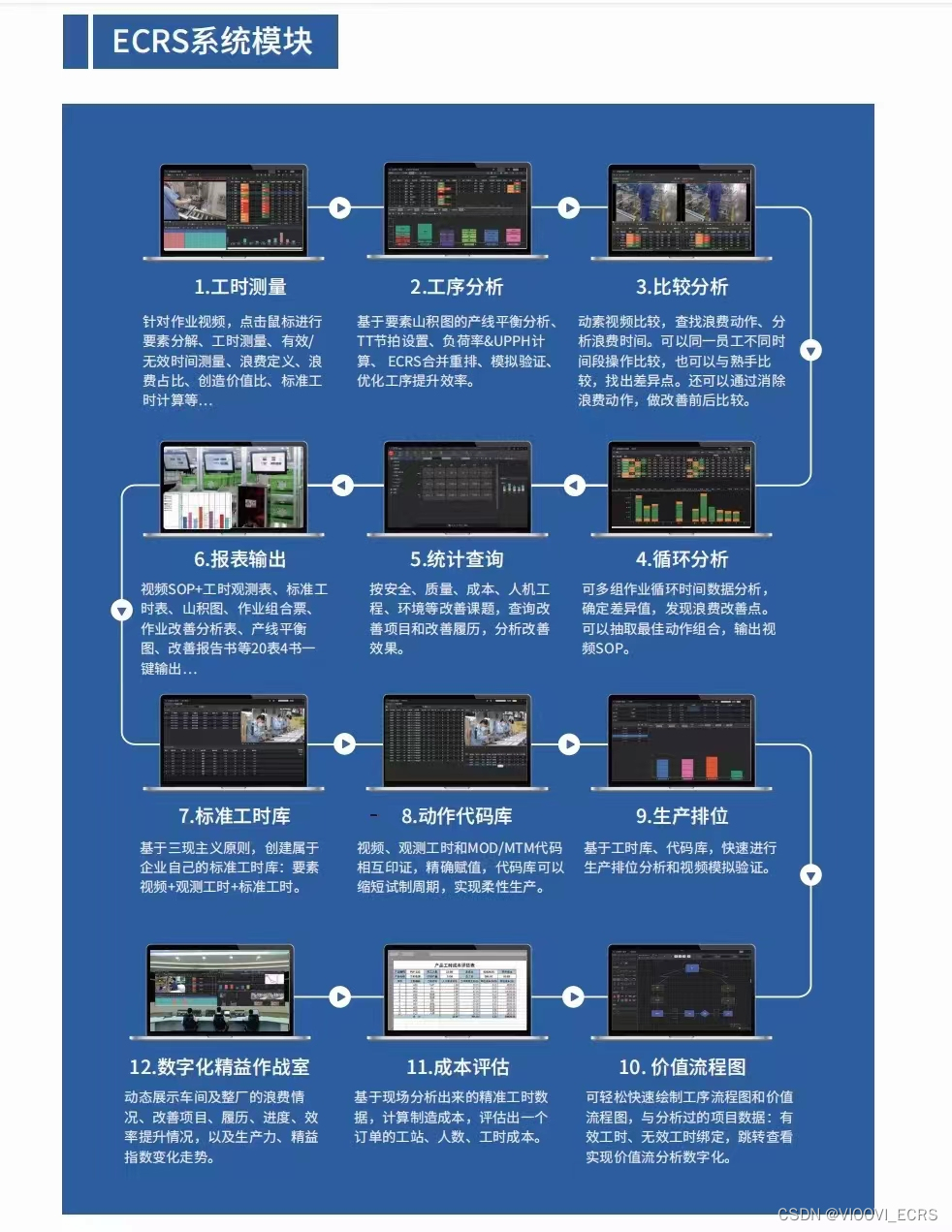
不久前,我们在 Elasticsearch® 中引入了检测,让你能够识别它在幕后所做的事情。 通过在 Elasticsearch 中进行追踪,我们获得了前所未有的见解。
当我们想要利用 Elastic 的学习稀疏编码器模型进行语义搜索时,本博客将引导你了解各种 API 和 transaction。 该博客本身可以应用于 Elasticsearch 内运行的任何机器学习模型- 你只需相应地更改命令和搜索即可。 本指南中的说明使用我们的稀疏编码器模型(请参阅文档)。
对于以下测试,我们的数据语料库是 OpenWebText,它提供大约 40GB 的纯文本和大约 800 万个单独的文档。 此设置在具有 32GB RAM 的 M1 Max Macbook 上本地运行。 以下任何交易持续时间、查询时间和其他参数仅适用于本博文。 不应对生产用途或你的安装进行任何推断。
让我们动手吧!
在 Elasticsearch 中激活跟踪是通过静态设置(在 elasticsearch.yml 中配置)和动态设置来完成的,动态设置可以在运行时使用 PUT _cluster/settings 命令进行切换(动态设置之一是采样率)。 某些设置可以在 runtime 时切换,例如采样率。 在elasticsearch.yml中,我们要设置以下内容:
tracing.apm.enabled: true
tracing.apm.agent.server_url: "url of the APM server"秘密令牌(或 API 密钥)必须位于 Elasticsearch 密钥库中。 使用以下命令 elasticsearch-keystore add Tracing.apm.secret_token 或 tracing.apm.api_key ,密钥库工具应该可以在 <你的 elasticsearch 安装目录>/bin/elasticsearch-keystore 中使用。 之后,你需要重新启动 Elasticsearch。 有关跟踪的更多信息可以在我们的跟踪文档中找到。
激活后,我们可以在 APM 视图中看到 Elasticsearch 自动捕获各种 API 端点。 GET、POST、PUT、DELETE 调用。 整理好之后,让我们创建索引:
PUT openwebtext-analyzed
{"settings": {"number_of_replicas": 0,"number_of_shards": 1,"index": {"default_pipeline": "openwebtext"}},"mappings": {"properties": {"ml.tokens": {"type": "rank_features"},"text": {"type": "text","analyzer": "english"}}}
}这应该给我们一个名为 PUT /{index} 的单个 transaction。 正如我们所看到的,当我们创建索引时发生了很多事情。 我们有创建调用,我们需要将其发布到集群状态并启动分片。

我们需要做的下一件事是创建一个摄取管道 —— 我们称之为 openwebtext。 管道名称必须在上面的索引创建调用中引用,因为我们将其设置为默认管道。 这可确保如果请求中未指定其他管道,则针对索引发送的每个文档都将自动通过此管道运行。
PUT _ingest/pipeline/openwebtext
{"description": "Elser","processors": [{"inference": {"model_id": ".elser_model_1","target_field": "ml","field_map": {"text": "text_field"},"inference_config": {"text_expansion": {"results_field": "tokens"}}}}]
}我们得到一个 PUT /_ingest/pipeline/{id} transaction。 我们看到集群状态更新和一些内部调用。 至此,所有准备工作都已完成,我们可以开始使用 openwebtext 数据集运行批量索引。

在开始批量摄入之前,我们需要启动 ELSER 模型。 转到 “Maching Learning(机器学习)”、“Trained Models(训练模型)”,然后单击 “Play(播放)”。 你可以在此处选择分配和线程的数量。
模型启动被捕获为 POST /_ml/trained_models/{model_id}/deployment/_start。 它包含一些内部调用,可能不如其他事务那么有趣。

现在,我们想通过运行以下命令来验证一切是否正常。 Kibana 开发工具有一个很酷的小技巧,你可以在文本的开头和结尾使用三引号(如”””),告诉 Kibana® 将其视为字符串并在必要时转义。 不再需要手动转义 JSON 或处理换行符。 只需输入你的文字即可。 这应该返回一个文本和一个显示所有令牌的 ml.tokens 字段。
POST _ingest/pipeline/openwebtext/_simulate
{"docs": [{"_source": {"text": """This is a sample text"""}}]
}此调用也被捕获为 transaction POST _ingest/pipeline/{id}/_simulate。 有趣的是,我们看到推理调用花费了 338 毫秒。 这是模型创建向量所需的时间。
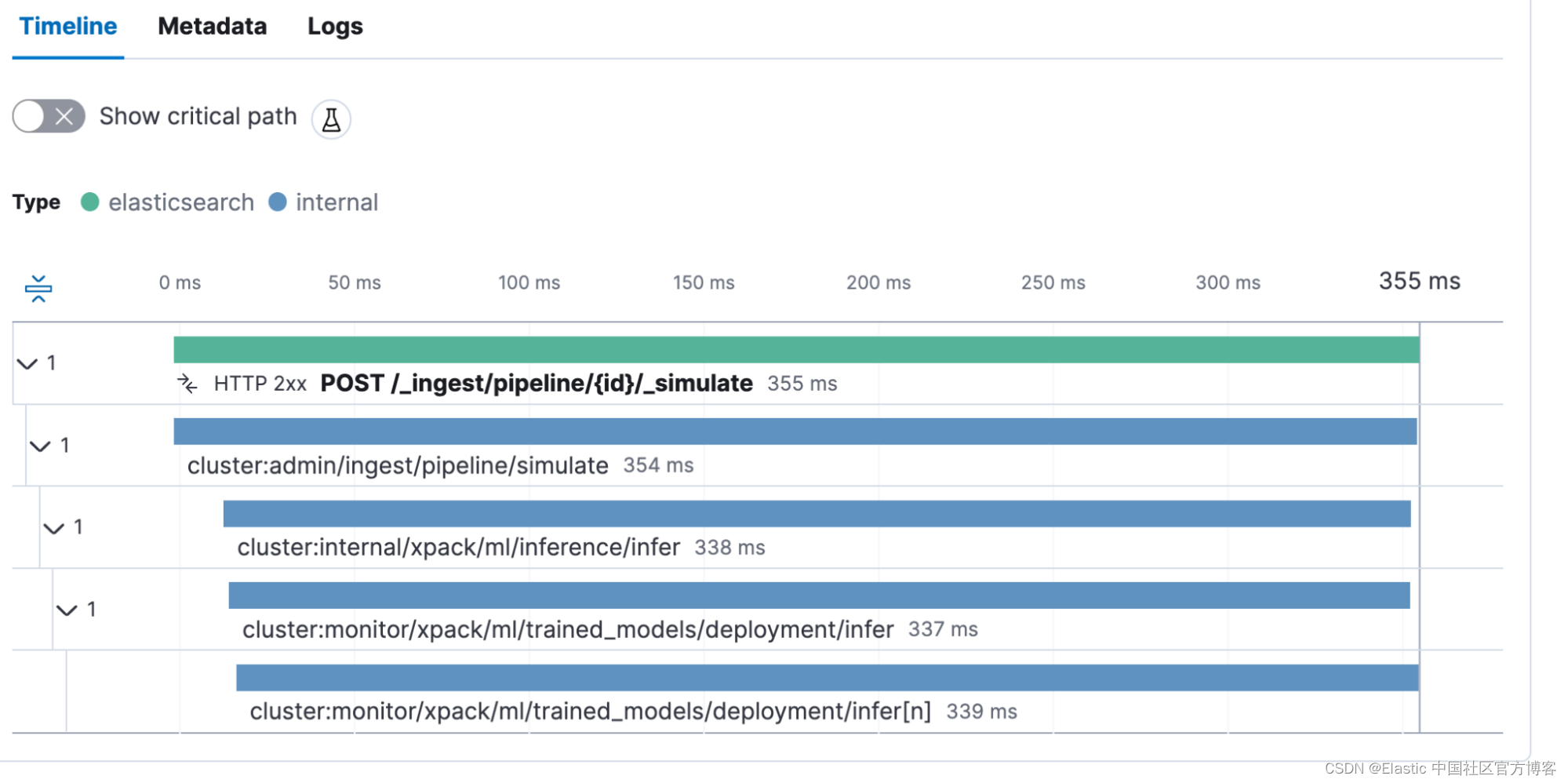
Bulk 摄入
openwebtext 数据集有一个文本文件,代表 Elasticsearch 中的单个文档。 这个相当 hack 的 Python 代码读取所有文件并使用简单的批量助手将它们发送到 Elasticsearch。 请注意,你不想在生产中使用它,因为它以序列化方式运行,因此速度相对较慢。 我们有并行批量帮助程序,允许你一次运行多个批量请求。
import os
from elasticsearch import Elasticsearch, helpers# Elasticsearch connection settings
ES_HOST = 'https://localhost:9200' # Replace with your Elasticsearch host
ES_INDEX = 'openwebtext-analyzed' # Replace with the desired Elasticsearch index name# Path to the folder containing your text files
TEXT_FILES_FOLDER = 'openwebtext'# Elasticsearch client
es = Elasticsearch(hosts=ES_HOST, basic_auth=('elastic', 'password'))def read_text_files(folder_path):for root, _, files in os.walk(folder_path):for filename in files:if filename.endswith('.txt'):file_path = os.path.join(root, filename)with open(file_path, 'r', encoding='utf-8') as file:content = file.read()yield {'_index': ES_INDEX,'_source': {'text': content,}}def index_to_elasticsearch():try:helpers.bulk(es, read_text_files(TEXT_FILES_FOLDER), chunk_size=25)print("Indexing to Elasticsearch completed successfully.")except Exception as e:print(f"Error occurred while indexing to Elasticsearch: {e}")if __name__ == "__main__":index_to_elasticsearch()我们看到这 25 个文档需要 11 秒才能被索引。 每次摄取管道调用推理处理器(进而调用机器学习模型)时,我们都会看到该特定处理器需要多长时间。 在本例中,大约需要 500 毫秒 — 25 个文档,每个文档约 500 毫秒,总共需约 12.5 秒来完成处理。 一般来说,这是一个有趣的观点,因为较长的文件可能会花费更多的时间,因为与较短的文件相比,需要分析的内容更多。 总体而言,整个批量请求持续时间还包括返回给 Python 代理的答案以及 “确定” 索引。 现在,我们可以创建一个仪表板并计算平均批量请求持续时间。 我们将在 Lens 中使用一些小技巧来计算每个文档的平均时间。 我会告诉你如何做。
首先,在事务中捕获了一个有趣的元数据 - 该字段称为 labels.http_request_headers_content_length。 该字段可能被映射为关键字,因此不允许我们运行求和、求平均值和除法等数学运算。 但由于运行时字段,我们不介意这一点。 我们可以将其转换为 Double。 在 Kibana 中,转到包含 traces-apm 数据流的数据视图,并执行以下操作作为值:
emit(Double.parseDouble($('labels.http_request_headers_content_length','0.0')))如果该字段不存在和/或丢失,则将现有值作为 Double 发出(emit),并将报告为 0.0。 此外,将格式设置为 Bytes。 这将使它自动美化! 它应该看起来像这样:

创建一个新的仪表板,并从新的可视化开始。 我们想要选择指标可视化并使用此 KQL 过滤器:data_stream.type: "traces" AND service.name: "elasticsearch" AND transaction.name: "PUT /_bulk"。 在数据视图中,选择包含 traces-apm 的那个,与我们在上面添加字段的位置基本相同。 单击 Prmary metric 和 fomula:
sum(labels.http_request_headers_content_length_double)/(count()*25)由于我们知道每个批量请求包含 25 个文档,因此我们只需将记录数(transaction 数)乘以 25,然后除以字节总和即可确定单个文档有多大。 但有一些注意事项 - 首先,批量请求会产生开销。 批量看起来像这样:
{ "index": { "_index": "openwebtext" }
{ "_source": { "text": "this is a sample" } }对于要索引的每个文档,你都会获得 JSON 中的第二行,该行会影响总体大小。 更重要的是,第二个警告是压缩。 当使用任何压缩时,我们只能说 “这批文档的大小为 x”,因为压缩的工作方式会根据批量内容而有所不同。 当使用高压缩值时,我们发送 500 个文档时可能会得到与现在发送 25 个文档相同的大小。 尽管如此,这是一个有趣的指标。

我们可以使用 transaction.duration.us 提示! 将 Kibana 数据视图中的格式更改为 Duration 并选择 microseconds,确保其渲染良好。 很快,我们可以看到,批量请求的平均大小约为 125kb,每个文档约为 5kb,耗时 9.6 秒,其中 95% 的批量请求在 11.8 秒内完成。

查询时间!
现在,我们已经对许多文档建立了索引,终于准备好对其进行查询了。 让我们执行以下查询:
GET /openwebtext/_search
{"query":{"text_expansion":{"ml.tokens":{"model_id":".elser_model_1","model_text":"How can I give my cat medication?"}}}
}我正在向 openwebtext 数据集询问有关给我的猫喂药的文章。 我的 REST 客户端告诉我,整个搜索(从开始到解析响应)花费了:94.4 毫秒。 响应中的语句为 91 毫秒,这意味着在 Elasticsearch 上的搜索花费了 91 毫秒(不包括一些内容)。 现在让我们看看 GET /{index}/_search transaction。
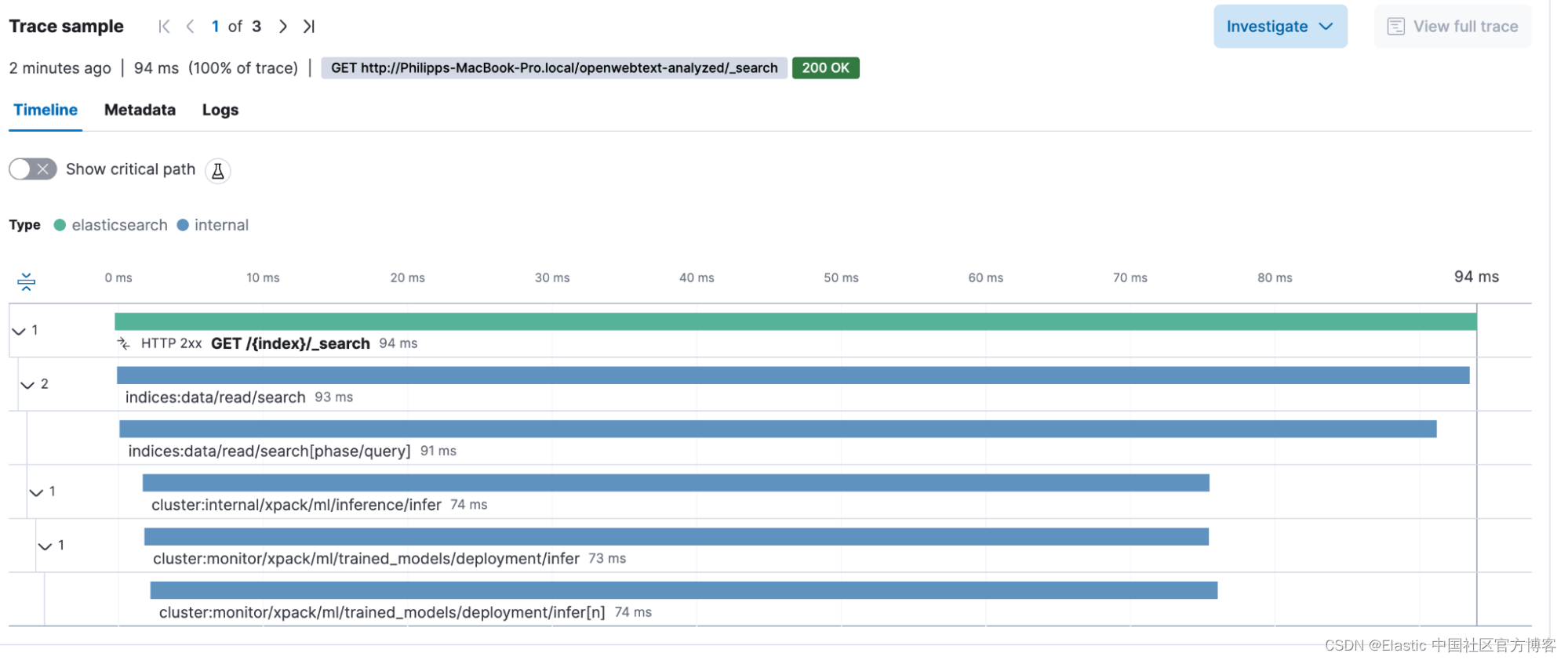
我们可以发现,机器学习(基本上是动态创建令牌)的影响占总请求的 74 毫秒。 是的,这大约占整个交易持续时间的 3/4。 有了这些信息,我们就可以就如何扩展机器学习节点以缩短查询时间做出明智的决策。
结论
这篇博文向你展示了将 Elasticsearch 作为仪表化应用程序并更轻松地识别瓶颈是多么重要。 此外,你还可以使用事务持续时间作为异常检测的指标,为你的应用程序进行 A/B 测试,并且再也不用怀疑 Elasticsearch 现在是否感觉更快了。 你有数据支持这一点。 此外,这广泛地关注了机器学习方面的问题。 查看一般慢日志查询调查博客文章以获取更多想法。
仪表板和数据视图可以从我的 Github 存储库导入。
原文:Identify slow queries in generative AI search experiences | Elastic Blog