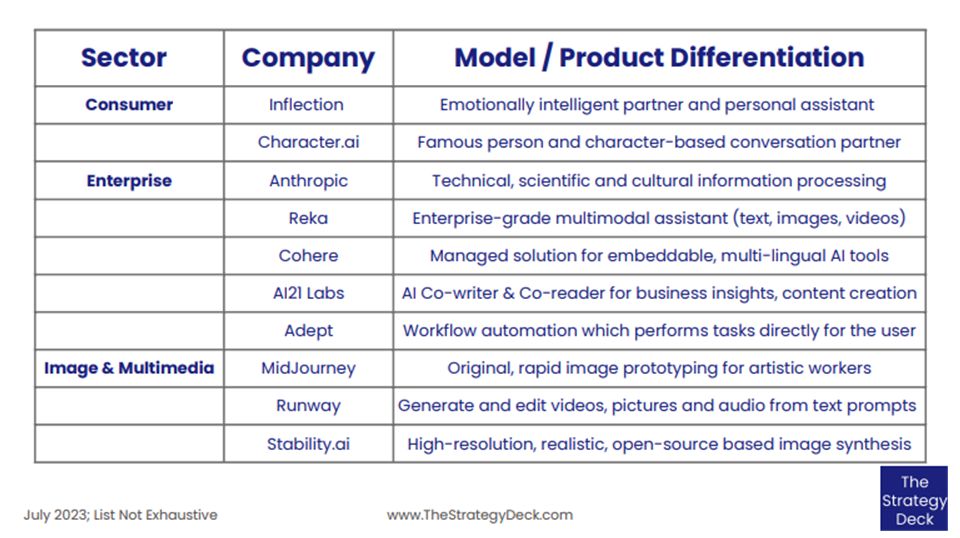
2.3. Pulsar Adaptors适配器
2.3.1.kafka适配器
2.3.2.Spark适配器
2.3. Pulsar Adaptors适配器
2.3.1.kafka适配器
Pulsar 为使用 Apache Kafka Java 客户端 API 编写的应用程序提供了一个简单的解决方案。
在生产者中, 如果想不改变原有kafka的代码架构, 就切换到Pulsar的平台中, 那么Pulsar adaptor on kafka就变的非常的有用了, 它可以帮助我们在不改变原有kafka的代码基础上, 即可接入pulsar, 但是需要注意, 相关配置信息需要进行一些调整, 例如: 地址与topic
- 1- 需要导入Pulsar集成kafka的依赖包, 删除掉原有Kafka-client包
<dependency> <groupId>org.apache.pulsar</groupId> <artifactId>pulsar-client-kafka</artifactId> <version>2.8.0</version>
</dependency>
注: 目前Pulsar并在Maven中央仓库中并没有提供Pulsar-client-kafka 2.8.1的包, 故此处导入2.8.0
- 2-编写生产者
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;
import java.util.concurrent.ExecutionException;public class KafkaAdaptorProducer {public static void main(String[] args) throws ExecutionException, InterruptedException {//1. 创建kafka生产者的核心类对象: KafkaProducer// 1.1: 创建生产者配置对象: 设置相关配置Properties props = new Properties();props.put("bootstrap.servers", "pulsar://node1:6650,node2:6650,node3:6650");// 消息的确认方案props.put("acks", "all");// key序列化类型props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// value 序列化类型props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props); //2. 发送数据 for (int i = 0; i < 10; i++) { //2.1: 创建 生产者数据承载对象 一个对象代表是一条消息数据ProducerRecord<String, String> producerRecord = new ProducerRecord<>("persistent://public/default/txn_t1",Integer.toString(i), Integer.toString(i)); producer.send(producerRecord).get(); }//3. 释放资源 producer.close();}}
- 3-编写消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;public class KafkaAdaptorConsumer {public static void main(String[] args) {//1. 创建kafka的消费者的核心对象: KafkaConsumer//1.1: 创建消费者配置对象, 并设置相关的参数:Properties props = new Properties();props.setProperty("bootstrap.servers", "pulsar://node1:6650,node2:6650,node3:6650");//消费者组的 idprops.setProperty("group.id", "test");//是否启动消费者自动提交消费偏移量props.setProperty("enable.auto.commit", "true");//每间隔多长时间提交一次偏移量:单位 毫秒props.setProperty("auto.commit.interval.ms","1000");//key 反序列化props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");//val 发序列化props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);//2. 给消费者设置订阅topic:consumer.subscribe(Arrays.asList("persistent://public/default/txn_t1"));//3. 循环获取相关的消息数据while (true) {//3.1: 从kafka中获取消息数据: 参数表示等待超时时间//注意: 如果没有获取到数据, 返回一个空集合对象, 如果数据集合中有多个 ConsumerRecord 对象ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));//3.2 遍历ConsumerRecords 获取每一个 ConsumerRecord 对象 : ConsumerRecord 消费者数据承载对象, 一个对象就是一条消息for (ConsumerRecord<String, String> record : records) {String massage = record.value();System.out.println("消息数据为:"+massage);}} }
}
- 4- 先运行消费者, 进行监听, 然后运行生产者, 观察消费者是否可以正常消费到数据

2.3.2.Spark适配器
Pulsar 的 Spark Streaming 接收器是一个自定义的接收器,它使用 Apache Spark Streaming 能够从 Pulsar 接
收原始数据。
应用程序可以通过 Spark Streaming receiver 接收 Resilient Distributed Dataset (RDD) 格式的数据,并可
以通过多种方式对其进行处理。
- 1-导入相关的依赖包
<dependency><groupId>org.apache.pulsar</groupId><artifactId>pulsar-spark</artifactId><version>2.8.0</version>
</dependency>
- 2-编写spark的流式代码
String serviceUrl = "pulsar://localhost:6650/";
String topic = "persistent://public/default/test_src";
String subs = "test_sub";
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("Pulsar Spark Example");
JavaStreamingContext jsc = new JavaStreamingContext(sparkConf, Durations.seconds(60));
ConsumerConfigurationData<byte[]> pulsarConf = new ConsumerConfigurationData();
Set<String> set = new HashSet<>();
set.add(topic);
pulsarConf.setTopicNames(set);
pulsarConf.setSubscriptionName(subs);
SparkStreamingPulsarReceiver pulsarReceiver = new SparkStreamingPulsarReceiver(
serviceUrl,
pulsarConf,
new AuthenticationDisabled());
JavaReceiverInputDStream<byte[]> lineDStream = jsc.receiverStream(pulsarReceiver);