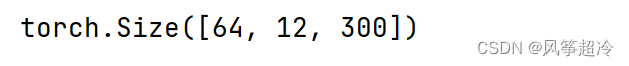- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:TensorFlow入门实战|第3周:天气识别
- 🍖 原作者:K同学啊|接辅导、项目定制
Self-Attention 机制和多头注意力机制是Transformer 模型中的核心组件
1. Self-Attention 机制
Self-Attention 机制是一种能够根据序列中不同位置的重要性来分配权重的注意力机制。它允许模型在一个序列中的不同位置之间进行交互,从而实现对序列的全局依赖建模,而不是像循环神经网络(RNN)那样依赖于顺序迭代。
原理: 在 Self-Attention 中,输入序列被视为一组向量,每个向量表示序列中的一个位置或词。通过计算每对位置之间的关联度得到一个注意力矩阵,该矩阵表征了每个位置对其他位置的重要性。然后,利用注意力矩阵对每个位置的向量进行加权求和,得到该位置的输出向量。
工作流程:
- 输入序列表示: 将输入序列表示为一组向量,通常通过嵌入层(embedding layer)将输入的符号序列(如词或字符)转换为向量表示。
- 计算注意力权重: 对于每个位置的输入向量,计算它与其他位置的关联度。这通常通过计算查询(Query)、键(Key)和值(Value)之间的点积来实现。
- 加权求和: 根据计算得到的注意力权重,对每个位置的值向量进行加权求和,得到该位置的输出向量。
- 输出: 得到所有位置的输出向量,作为 Self-Attention 层的输出。
优点:
- 能够捕捉长距离依赖关系,使得模型在处理长序列时表现优异。
- 允许并行计算,提高了计算效率。
2. 多头注意力机制
多头注意力机制是在 Self-Attention 的基础上进行扩展的一种机制,它允许模型同时关注输入序列的不同子空间,从而提高了模型的表征能力。
原理: 在多头注意力机制中,将 Self-Attention 操作应用多次,每次使用不同的查询、键和值投影矩阵,得到多组注意力权重和输出。然后将这些输出拼接在一起,并通过一个线性变换层(dense layer)进行处理,得到最终的多头注意力输出。
工作流程:
- 多头投影: 对输入向量分别应用多组投影矩阵,得到多组查询、键和值。
- 多头注意力计算: 对每组查询、键和值分别计算注意力权重,并得到多组输出向量。
- 拼接与线性变换: 将多组输出向量拼接在一起,并通过一个线性变换层进行处理,得到最终的多头注意力输出。
3.Attention代码实例
import torch
import torch.nn as nnclass MultiHeadAttention(nn.Module):def __init__(self, hid_dim, n_heads, dropout):super().__init__()self.hid_dim = hid_dimself.n_heads = n_heads# hid_dim必须整除assert hid_dim % n_heads == 0# 定义wqself.w_q = nn.Linear(hid_dim, hid_dim)# 定义wkself.w_k = nn.Linear(hid_dim, hid_dim)# 定义wvself.w_v = nn.Linear(hid_dim, hid_dim)self.fc = nn.Linear(hid_dim, hid_dim)self.do = nn.Dropout(dropout)self.scale = torch.sqrt(torch.FloatTensor([hid_dim//n_heads]))def forward(self, query, key, value, mask=None):# Q与KV在句子长度这一个维度上数值可以不一样bsz = query.shape[0]Q = self.w_q(query)K = self.w_k(key)V = self.w_v(value)# 将QKV拆成多组,方案是将向量直接拆开了# (64, 12, 300) -> (64, 12, 6, 50) -> (64, 6, 12, 50)# (64, 10, 300) -> (64, 10, 6, 50) -> (64, 6, 10, 50)# (64, 10, 300) -> (64, 10, 6, 50) -> (64, 6, 10, 50)Q = Q.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)K = K.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)V = V.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)# 第1步,Q x K / scale# (64, 6, 12, 50) x (64, 6, 50, 10) -> (64, 6, 12, 10)attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale# 需要mask掉的地方,attention设置的很小很小if mask is not None:attention = attention.masked_fill(mask == 0, -1e10)# 第2步,做softmax 再dropout得到attentionattention = self.do(torch.softmax(attention, dim=-1))# 第3步,attention结果与k相乘,得到多头注意力的结果# (64, 6, 12, 10) x (64, 6, 10, 50) -> (64, 6, 12, 50)x = torch.matmul(attention, V)# 把结果转回去# (64, 6, 12, 50) -> (64, 12, 6, 50)x = x.permute(0, 2, 1, 3).contiguous()# 把结果合并# (64, 12, 6, 50) -> (64, 12, 300)x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))x = self.fc(x)return xquery = torch.rand(64, 12, 300)
key = torch.rand(64, 10, 300)
value = torch.rand(64, 10, 300)
attention = MultiHeadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
print(output.shape)