YOLO可以说是单阶段的目标检测方法的集大成之作,必学的经典论文,从准备面试的角度来学习一下yolo系列。
YOLOv1
1.RCNN系列回顾
RCNN系列,无论哪种算法,核心思路都是Region Proposal(定位)+ classifier(修正定位+分类)。所以也被称为两阶段算法。但是难以达到实时检测的效果,因此yolov1将其修改为单阶段的算法,yolov1虽然牺牲了一定的精度,但是检测速度大幅提升,而后续的yolo版本在其之上改进,现在已经有yolov9和yolo-world了,成为主流的目标检测模型。
2.YOLOv1
(部分内容和图参考保姆级教程:图解目标检测算法YOLOv1 - 知乎 (zhihu.com))
论文原文:
1506.02640.pdf (arxiv.org)![]() https://arxiv.org/pdf/1506.02640.pdf在讲解过程中会出现很多专业词汇,会挨着进行说明。
https://arxiv.org/pdf/1506.02640.pdf在讲解过程中会出现很多专业词汇,会挨着进行说明。
YOLOv1的核心思路就是舍弃Region Proposal这个极其耗时的过程,转而进行回归。怎么实现舍弃RP的,就是学习的关键。
(1)核心思想
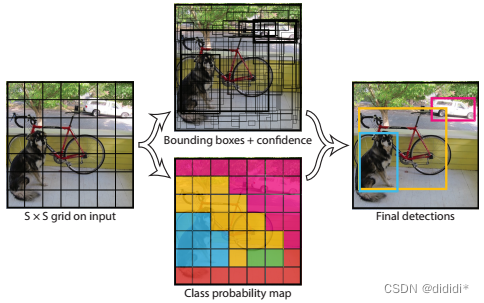
采用利用整张图作为网络的输入,将图像划分为S*S个grid,某一个grid只关注于预测物体中心在这个grid中的目标,整个网络最后直接在输出层回归 bounding box 的位置和 bounding box 所属的类别。

Grid和Bouding Box
这里可能会产生一点误解,故区分一下。
Grid:将图片直接划分为S*S个grid,位置是固定死的,比如上图中,划分为了7*7个grid。
Bouding Box:就是最后检测出物体的框,如上图中框住狗狗的红色框,在算法流程中,可以用两种数据形式表示,一种是使用中心坐标+长宽的形式(Cx,Cy,H,W),一种是使用左上和右下角点坐标的形式(x1,y1,x2,y2)。而每个框除了要包含位置信息,还包含了该框是否包含物体的置信度,这个置信度怎么计算的我们后面讲解,这里只需要记住每个Bounding Box其实对应了5个数据。
置信度(Confidence)的计算
置信度就是算法的自信心得分,这个值越高,代表这个BoundigBox里越有可能包含物体。计算方式如下:
Pr(Object)为边界框内存在对象的概率,若存在对象,Pr(Object)=1,否则Pr(Object)=0。
但是这里要注意一下,其实我们整个网络的计算中是不需要用这个公式计算的,网络输出一个0~1的值就好。
IOU(Intersection over Union ratio)
IOU又叫做交并比,其实很好理解,就是两个框计算出来的一个值,意义上来看,IOU值越大,表示两个框的重合度越高,从公式上来看:
一个实现代码如下:
def calculate_iou(bbox1,bbox2):"""计算bbox1=(x1,y1,x2,y2)和bbox2=(x3,y3,x4,y4)两个bbox的iou"""intersect_bbox = [0., 0., 0., 0.] # bbox1和bbox2的交集if bbox1[2]<bbox2[0] or bbox1[0]>bbox2[2] or bbox1[3]<bbox2[1] or bbox1[1]>bbox2[3]:passelse:intersect_bbox[0] = max(bbox1[0],bbox2[0])intersect_bbox[1] = max(bbox1[1],bbox2[1])intersect_bbox[2] = min(bbox1[2],bbox2[2])intersect_bbox[3] = min(bbox1[3],bbox2[3])area1 = (bbox1[2] - bbox1[0]) * (bbox1[3] - bbox1[1]) # bbox1面积area2 = (bbox2[2] - bbox2[0]) * (bbox2[3] - bbox2[1]) # bbox2面积area_intersect = (intersect_bbox[2] - intersect_bbox[0]) * (intersect_bbox[3] - intersect_bbox[1]) # 交集面积# print(bbox1,bbox2)# print(intersect_bbox)# input()if area_intersect>0:return area_intersect / (area1 + area2 - area_intersect) # 计算iouelse:return 0
按照这个思路,我们可以简要理一下网络的输入输出:
输入一张固定大小的图像,规定划分的格子数S*S,规定每个格子要预测几个框B。
输出为一个S*S*(B*5+Class),S和B对应输入,5就是boundingbox中包含的五个信息,class就是类别的预测,这里类别使用的是one-hot编码。
以作者在论文里提到的PASCAL VOC上的实验为例:
S=7,B=5,有20个类别,故输出tensor的维度为7*7*(5*2)
这里有个很容易错误理解的点,就是这个class的分类结果其实是对应了这一个grid的,一个grid输出一个20维的分类结果,而不是整个grid所得到的两个BoundingBox的分类结果,
(2)网络结构
YOLOv1的数据流如下:
- resize图片尺寸(没有ROI)
- 输入网络,输出tensor
- 非极大值抑制(NMS)
网络的结构如下:

这里光看图可能很多初学的同学不是很看的懂,我们来看看一个简单的pytorch版本:
参考:动手学习深度学习pytorch版——从零开始实现YOLOv1_自己实现的yolov-CSDN博客
这一部分需要说明一下,由于原论文是采用自己设计的20层卷积层先在ImageNet上训练了一周,完成特征提取部分的训练。我们作为学习者而非发明者来说,花一周时间训练实在是太长了。因此,在这里我打算对原论文的结构做一点改变。YOLOv1的前20层是用于特征提取的,也就是随便替换为一个分类网络(除去最后的全连接层)其实都行。因此,我打算使用ResNet34的网络作为特征提取部分。这样做的好处是,pytorch的torchvision中提供了ResNet34的预训练模型,训练集也是ImageNet,等于说有先成训练好的模型可以直接使用,从而免去了特征提取部分的训练时间。然后,除去ResNet34的最后两层,再连接上YOLOv1的最后4个卷积层和两个全连接层,作为我们训练的网络结构。
此外,还进行了一些小调整,比如最后增加了一个Sigmoid层,以及在卷积层后增加了BN层等等。具体代码如下:import torchvision.models as tvmodel import torch.nn as nn import torchclass YOLOv1_resnet(nn.Module):def __init__(self):super(YOLOv1_resnet,self).__init__()resnet = tvmodel.resnet34(pretrained=True) # 调用torchvision里的resnet34预训练模型resnet_out_channel = resnet.fc.in_features # 记录resnet全连接层之前的网络输出通道数,方便连入后续卷积网络中self.resnet = nn.Sequential(*list(resnet.children())[:-2]) # 去除resnet的最后两层# 以下是YOLOv1的最后四个卷积层self.Conv_layers = nn.Sequential(nn.Conv2d(resnet_out_channel,1024,3,padding=1),nn.BatchNorm2d(1024), # 为了加快训练,这里增加了BN层,原论文里YOLOv1是没有的nn.LeakyReLU(),nn.Conv2d(1024,1024,3,stride=2,padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(),nn.Conv2d(1024, 1024, 3, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(),nn.Conv2d(1024, 1024, 3, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(),)# 以下是YOLOv1的最后2个全连接层self.Conn_layers = nn.Sequential(nn.Linear(7*7*1024,4096),nn.LeakyReLU(),nn.Linear(4096,7*7*30),nn.Sigmoid() # 增加sigmoid函数是为了将输出全部映射到(0,1)之间,因为如果出现负数或太大的数,后续计算loss会很麻烦)def forward(self, input):input = self.resnet(input)input = self.Conv_layers(input)input = input.view(input.size()[0],-1)input = self.Conn_layers(input)return input.reshape(-1, (5*NUM_BBOX+len(CLASSES)), 7, 7) # 记住最后要reshape一下输出数据这里我们主要关注最后两个fc层,是没有使用池化操作的,直接使用view和resize就实现了三维张量和二维张量的转换。
(3)非极大值抑制
非极大值抑制的目的就是去掉一些冗余框。
这一部分可以参考一下:目标检测入门之非最大值抑制(NMS)算法 - 知乎 (zhihu.com)
(4)损失函数
损失函数是理解YOLOv1训练的关键,具体形式如下:

这里的损失函数包括五项:
前两项对应BoundingBox的损失函数(针对x, y, H, W进行学习)
接下来两项对应Confidence的损失函数(针对置信度进行学习)
最后一项对应分类的损失(针对类别label进行学习)
细节上来说:
1.公式中每一个均方误差的系数: 表示的是第i个grid的第j个BoundingBox是否负责Object,每个grid对应的B个BoudingBox中,与GT的IOU最大的BoundingBox才负责这个Object,其余的为
,这一部分可以简单看一下代码:
if iou1 >= iou2:coor_loss = coor_loss + 5 * (torch.sum((pred[i,0:2,m,n] - labels[i,0:2,m,n])**2) \+ torch.sum((pred[i,2:4,m,n].sqrt()-labels[i,2:4,m,n].sqrt())**2))obj_confi_loss = obj_confi_loss + (pred[i,4,m,n] - iou1)**2# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou2noobj_confi_loss = noobj_confi_loss + 0.5 * ((pred[i,9,m,n]-iou2)**2)
这里计算obj_confi_loss和noobj_confi_loss使用的pred和IOU都是不一样的,pred[i,4,m,n]中的4对应的是IOU更大的框,9对应的是IOU更小的框。
2.这里对 (w,ℎ) 在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20 个像素点的偏差,对于 800x600 的预测框几乎没有影响,此时的IOU数值还是很大,但是对于 30x40 的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
3.此时再来看 与
,YOLO 面临的物体检测问题,是一个典型的类别数目不均衡的问题(Focal Loss就是解决这个问题的,一个面试中常问的点)。其中 49 个格点,含有物体的格点往往只有 3、4 个,其余全是不含有物体的格点。此时如果不采取点措施,那么物体检测的mAP不会太高,因为模型更倾向于不含有物体的格点。
与
的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中,
与
的取值分别为 5 与 0.5 。
最后整个Loss部分的代码如下:
class Loss_yolov1(nn.Module):def __init__(self):super(Loss_yolov1,self).__init__()def forward(self, pred, labels):""":param pred: (batchsize,30,7,7)的网络输出数据:param labels: (batchsize,30,7,7)的样本标签数据:return: 当前批次样本的平均损失"""num_gridx, num_gridy = labels.size()[-2:] # 划分网格数量num_b = 2 # 每个网格的bbox数量num_cls = 20 # 类别数量noobj_confi_loss = 0. # 不含目标的网格损失(只有置信度损失)coor_loss = 0. # 含有目标的bbox的坐标损失obj_confi_loss = 0. # 含有目标的bbox的置信度损失class_loss = 0. # 含有目标的网格的类别损失n_batch = labels.size()[0] # batchsize的大小# 可以考虑用矩阵运算进行优化,提高速度,为了准确起见,这里还是用循环for i in range(n_batch): # batchsize循环for n in range(7): # x方向网格循环for m in range(7): # y方向网格循环if labels[i,4,m,n]==1:# 如果包含物体# 将数据(px,py,w,h)转换为(x1,y1,x2,y2)# 先将px,py转换为cx,cy,即相对网格的位置转换为标准化后实际的bbox中心位置cx,xy# 然后再利用(cx-w/2,cy-h/2,cx+w/2,cy+h/2)转换为xyxy形式,用于计算ioubbox1_pred_xyxy = ((pred[i,0,m,n]+n)/num_gridx - pred[i,2,m,n]/2,(pred[i,1,m,n]+m)/num_gridy - pred[i,3,m,n]/2,(pred[i,0,m,n]+n)/num_gridx + pred[i,2,m,n]/2,(pred[i,1,m,n]+m)/num_gridy + pred[i,3,m,n]/2)bbox2_pred_xyxy = ((pred[i,5,m,n]+n)/num_gridx - pred[i,7,m,n]/2,(pred[i,6,m,n]+m)/num_gridy - pred[i,8,m,n]/2,(pred[i,5,m,n]+n)/num_gridx + pred[i,7,m,n]/2,(pred[i,6,m,n]+m)/num_gridy + pred[i,8,m,n]/2)bbox_gt_xyxy = ((labels[i,0,m,n]+n)/num_gridx - labels[i,2,m,n]/2,(labels[i,1,m,n]+m)/num_gridy - labels[i,3,m,n]/2,(labels[i,0,m,n]+n)/num_gridx + labels[i,2,m,n]/2,(labels[i,1,m,n]+m)/num_gridy + labels[i,3,m,n]/2)iou1 = calculate_iou(bbox1_pred_xyxy,bbox_gt_xyxy)iou2 = calculate_iou(bbox2_pred_xyxy,bbox_gt_xyxy)# 选择iou大的bbox作为负责物体if iou1 >= iou2:coor_loss = coor_loss + 5 * (torch.sum((pred[i,0:2,m,n] - labels[i,0:2,m,n])**2) \+ torch.sum((pred[i,2:4,m,n].sqrt()-labels[i,2:4,m,n].sqrt())**2))obj_confi_loss = obj_confi_loss + (pred[i,4,m,n] - iou1)**2# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou2noobj_confi_loss = noobj_confi_loss + 0.5 * ((pred[i,9,m,n]-iou2)**2)else:coor_loss = coor_loss + 5 * (torch.sum((pred[i,5:7,m,n] - labels[i,5:7,m,n])**2) \+ torch.sum((pred[i,7:9,m,n].sqrt()-labels[i,7:9,m,n].sqrt())**2))obj_confi_loss = obj_confi_loss + (pred[i,9,m,n] - iou2)**2# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou1noobj_confi_loss = noobj_confi_loss + 0.5 * ((pred[i, 4, m, n]-iou1) ** 2)class_loss = class_loss + torch.sum((pred[i,10:,m,n] - labels[i,10:,m,n])**2)else: # 如果不包含物体noobj_confi_loss = noobj_confi_loss + 0.5 * torch.sum(pred[i,[4,9],m,n]**2)loss = coor_loss + obj_confi_loss + noobj_confi_loss + class_loss# 此处可以写代码验证一下loss的大致计算是否正确,这个要验证起来比较麻烦,比较简洁的办法是,将输入的pred置为全1矩阵,再进行误差检查,会直观很多。return loss/n_batch
3.YOLOv1的缺点
- 由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。
- 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
- YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。