目录
前言
一、limit优化
1. 未优化案例
2.优化后案例
二、count优化
count用法
三、update优化
1.锁行情况(有索引)
2.锁表情况(无索引)
前言
上一期我们学习了order by优化和group by优化,本期我们就继续学习sql语句的优化,分为以下三个部分MySQL进阶-----limit、count、update优化。正文如下:
一、limit优化
这里我有一张表tb_sku 里面有400w条数据,以这个表作为案例对象

1. 未优化案例
select * from tb_sku limit 0,10;
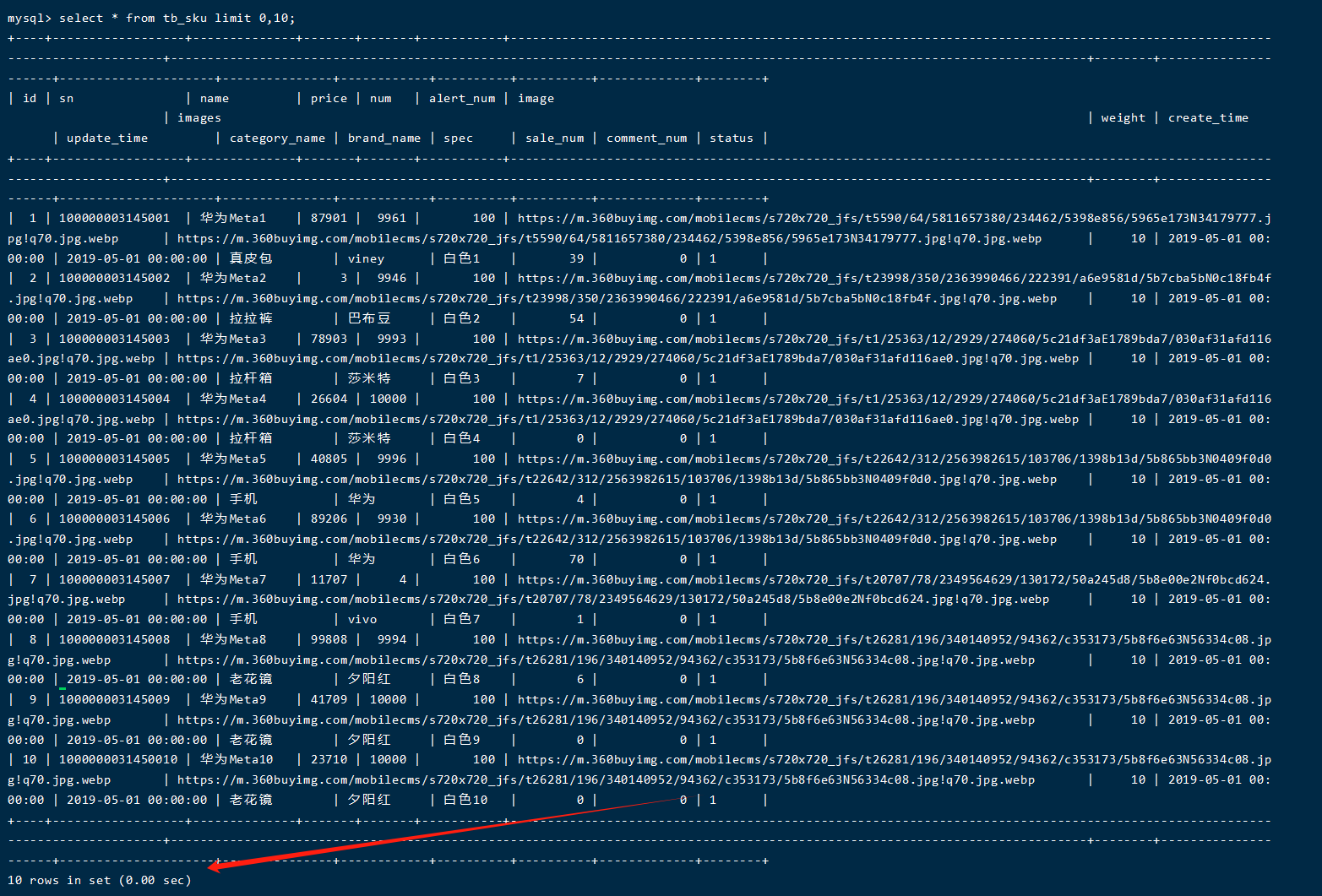
可以看出耗时几乎为0,一下子就完成了
(2)查询起始索引100w后的10条记录
select * from tb_sku limit 1000000,10;
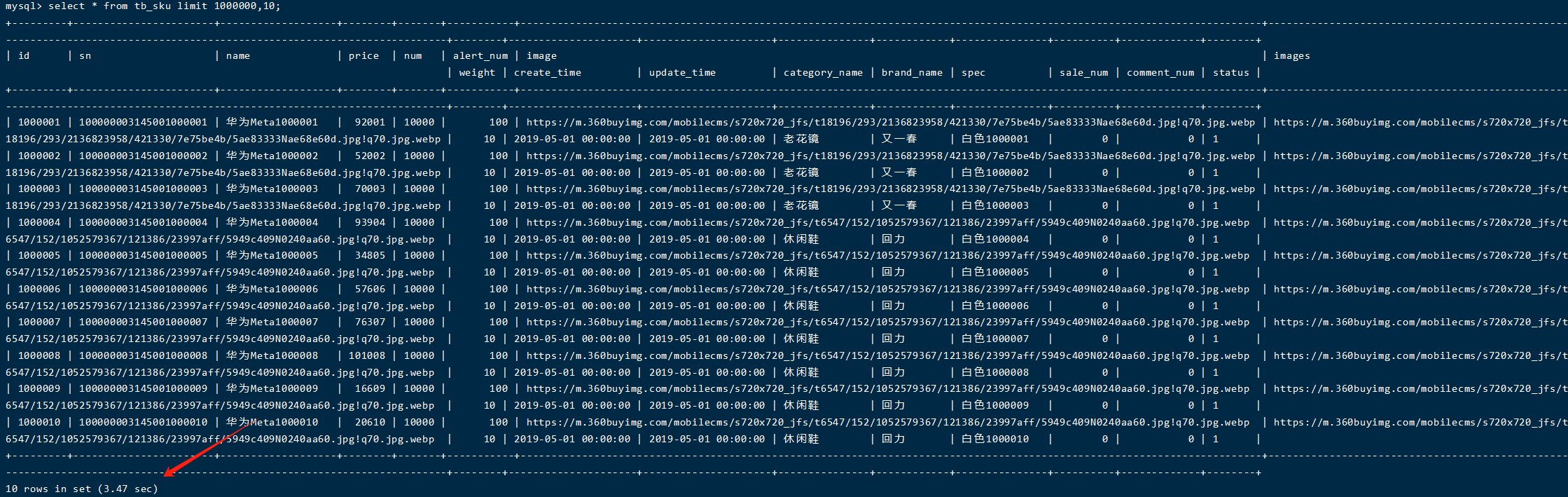
这里耗时要3秒多,需要的时间变长了
(3) 查询起始索引300w后的10条记录
select * from tb_sku limit 3000000,10;

这里耗时几乎翻倍,要11秒多。所以越往后需要的时间就越多。
优化思路 : 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
2.优化后案例
已知当前表的主键为id,其已有索引,那么我们试一下把上面的*换为查询id
select id from tb_sku limit 3000000,10;
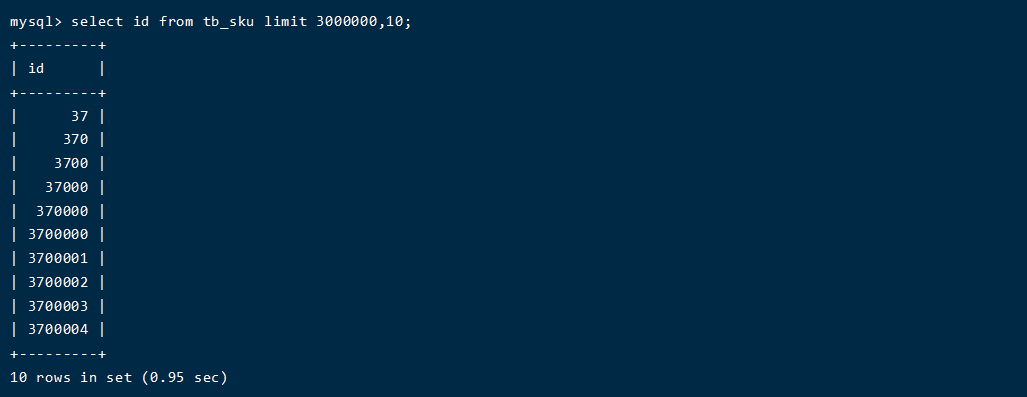
下面我们通过子查询的形式来去优化分页查询
select * from tb_sku a , (select id from tb_sku order by id limit 3000000,10) b where a.id = b.id;
这里查询只需要6秒多 ,查询同样的数据,相较于上面的直接查询少了5秒,将近一半。
二、count优化
select count(*) from tb_user ;
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很高; 但是如果是带条件的count,MyISAM也慢。
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出 来,然后累积计数。
count用法
| count用 法 | 含义 |
| count(主 键) | InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。 服务层拿到主键后,直接按行进行累加(主键不可能为null) |
| count(字 段) | 没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。 有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。 |
| count(数 字) | InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1” 进去,直接按行进行累加。 |
| count(*) | InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。 |
按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)。
三、update优化
下面有一张表courses,数据如下,这里就以这个表作为案例对象

在finalshell这里我们开启两个窗口,然后分别登录MySQL
然后开启事务,执行语句
1.锁行情况(有索引)
A.左边窗口
update courses set c_name='JavaScript' where id=2;
B .右边窗口
update courses set c_name='htmlcss' where id=1;
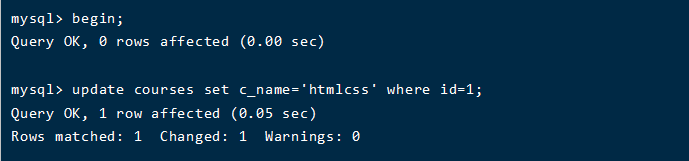
好了,上面两个表都开启了事务,执行update语句,从结果可以看出这两个并发的事务并没有发生冲突,然后下面我们把两边窗口事务进行提交。
再次查询更新后表数据: 执行到这里是没问题的,没有发送阻塞情况,最终表也是更新完成。这是因为这里使用的是行锁,也就是where语句后面定位到的是id字段,这
执行到这里是没问题的,没有发送阻塞情况,最终表也是更新完成。这是因为这里使用的是行锁,也就是where语句后面定位到的是id字段,这
update courses set c_name='C++' where c_name='JavaScript';
个字段是有索引的,故会把这一行锁住,但我们去执行其他行的时候与本行无关,所以不会发生冲突阻塞。所以当我们在执行删除的SQL语句时,会锁定id为1这一行的数据,然后事务提交之后,行锁释放。
2.锁表情况(无索引)
同样的我们还是用两个窗口看看锁表情况的案例:
A.左边窗口
update courses set c_name='msyql' where c_name='htmlcss';

B.右边窗口
update courses set c_name='C++' where c_name='JavaScript';

右边窗口的执行结果跟我们预期的不一样,并没有继续执行下去,而是卡在这里了,这是因为出现了锁表的情况,也就是说左边窗口执行的事务没有提交之前,整个表都是被锁住的,所以其他事务是无法对这个表进行操作的。
当我们去提交了左边窗口的事务后,再看看右边窗口的执行情况。

表锁释放了,所以执行成功。然后我们把右边窗口的事务进行提交。最后查看更新后的表数据。

InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁 。
以上就是本期的全部内容了,我们下次见!
分享一张壁纸: